here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(performance, see, datawizard, MASS)22 Outlier
Panoramica del capitolo
In questo capitolo impareremo a:
- comprendere il ruolo e gli effetti degli outlier nelle analisi statistiche;
- individuare outlier con metodi univariati e multivariati;
- utilizzare il pacchetto performance in R per la loro identificazione;
- documentare le decisioni in modo trasparente e riproducibile;
- valutare alternative alla rimozione (ad es. winsorizzazione) e l’importanza della preregistrazione.
ConsiglioPrerequisiti
- Leggere “Check your outliers! An introduction to identifying statistical outliers in R with easystats” (Thériault et al., 2024).
AttenzionePreparazione del Notebook
22.1 Individuare e gestire gli outlier
L’identificazione e la gestione degli outlier (o valori anomali) rappresentano una fase critica e interpretativa dell’analisi dei dati. La maggior parte delle statistiche di sintesi e dei modelli più diffusi, come la media, la deviazione standard, il coefficiente di correlazione o i parametri di una regressione lineare, sono infatti altamente sensibili alla loro presenza. Un singolo valore estremo può distorcere in modo significativo i risultati, portando a conclusioni errate o fuorvianti.
Un classico esempio è il calcolo del reddito medio: l’inclusione accidentale di un dato estremamente elevato (ad es., di un miliardario in un campione di cittadini comuni) produrrà una media che non riflette affatto la condizione economica tipica del gruppo, alterando completamente la rappresentazione della realtà.
Tuttavia, è fondamentale ricordare che individuare un outlier non significa automaticamente eliminarlo. La sua gestione è una scelta metodologica che deve essere ponderata: un valore anomalo può essere un errore di misurazione da correggere, ma anche un’osservazione genuina e informativa che richiede un modello analitico più robusto o che, addirittura, costituisce il vero oggetto di studio. La decisione finale dipende sempre dal contesto sostanziale della ricerca e dalla domanda analitica che si intende affrontare.
22.1.1 L’importanza della visualizzazione dei dati
La visualizzazione è spesso il primo passo per individuare valori anomali. Strumenti come boxplot, istogrammi e scatterplot permettono di identificare rapidamente osservazioni che si discostano dalla distribuzione generale.
Tuttavia, queste tecniche sono efficaci soprattutto per outlier unidimensionali o bidimensionali. Quando il numero di variabili cresce, l’analisi visiva diventa insufficiente e sono necessari metodi statistici più strutturati, come la distanza di Mahalanobis.
22.2 Come identificare gli outlier
22.2.1 I boxplot
Il boxplot è uno strumento semplice e intuitivo. Riassume la distribuzione mostrando la mediana, il primo e il terzo quartile (Q1 e Q3) e due estremi, detti “whiskers”. I punti al di fuori di questi whiskers sono considerati potenziali outlier.
Esempio in R:
data <- data.frame(
value = c(rnorm(100, mean = 10, sd = 2), 30)
) # Aggiungiamo un outlier
ggplot(data, aes(y = value)) +
geom_boxplot() +
coord_flip()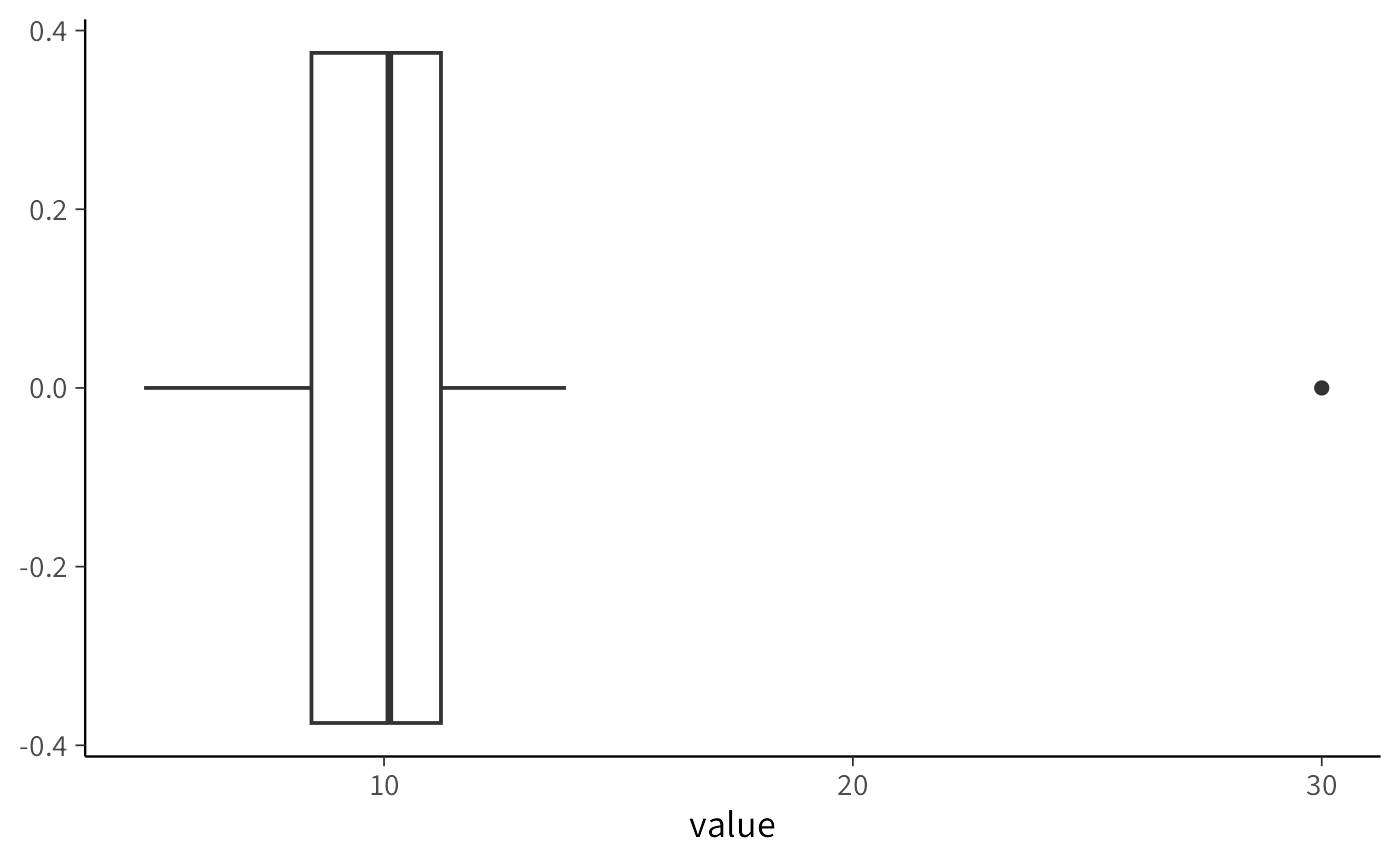
22.2.2 Metodi basati sulla variabilità
22.2.2.1 Intervallo interquartile (IQR)
John Tukey ha introdotto una definizione operativa di outlier basata sull’Interquartile Range (IQR), ovvero la differenza tra il terzo e il primo quartile:
- i valori inferiori a \(Q1 - 1.5 \times IQR\) o superiori a \(Q3 + 1.5 \times IQR\) sono considerati outlier moderati;
- i valori oltre \(Q1 - 3 \times IQR\) o \(Q3 + 3 \times IQR\) sono definiti far out outliers.
Esempio in R:
Questo metodo è robusto e semplice, ma può risultare meno efficace con distribuzioni fortemente asimmetriche.
22.2.2.2 Median Absolute Deviation (MAD)
Un metodo più robusto rispetto all’IQR è il Median Absolute Deviation (MAD), che utilizza la mediana anziché la media per stimare la dispersione:
È spesso preferibile quando i dati non seguono una distribuzione normale.
22.3 Outlier multivariati
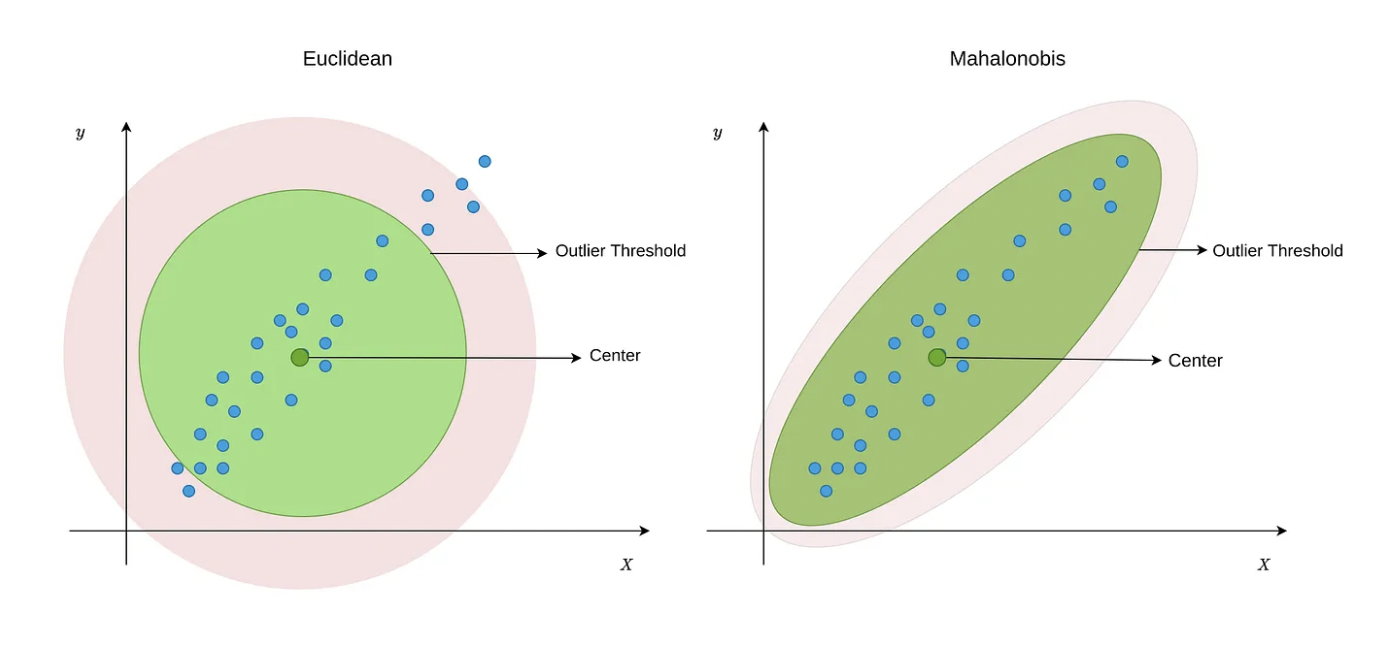
Un’osservazione può non apparire anomala su una singola variabile, ma risultare atipica considerando più variabili simultaneamente. La distanza di Mahalanobis misura quanto ogni osservazione si discosta dal centro multivariato, tenendo conto delle correlazioni tra variabili.
- Con la distanza “normale” (come quella che misuri con un righello), se una persona è più alta o più pesante della media, la distanza è calcolata in modo “isolato”, senza considerare che altezza e peso sono spesso correlate (persone più alte tendono a pesare di più).
- Con la distanza di Mahalanobis, invece, si osserva il “contesto” dei dati. Se tutti nel gruppo hanno un’altezza e un peso che crescono in modo coordinato (ad esempio, ogni 10 cm in più corrispondono a 8 kg in più), questa distanza valuta se la nuova persona si allontana da questo schema generale. Ad esempio, una persona molto alta ma con peso medio potrebbe essere considerata più “anomala” di una persona altrettanto alta ma più pesante, perché viola la relazione tipica del gruppo.
Per comprendere intuitivamente la distanza di Mahalanobis, immaginiamo di avere una nube di punti che rappresentano individui, ciascuno con i propri valori di altezza e peso. Il “centro” di questa nube è un punto ideale che rappresenta una sorta di media multivariata (tenendo conto sia dell’altezza sia del peso). La distanza di Mahalanobis misura quanto ogni singolo individuo si allontana da questo centro, considerando la variabilità congiunta delle variabili (ad esempio, la correlazione tra altezza e peso). Se un individuo presenta caratteristiche molto diverse rispetto alla maggioranza, la sua distanza di Mahalanobis sarà elevata, segnalando un potenziale outlier.
ConsiglioDistanza di Mahalanobis
Consideriamo ora una definizione della distanza di Mahalanobis nel caso bivariato (due variabili). Immaginiamo di avere due variabili come altezza (\(X\)) e peso (\(Y\)), con:
-
Medie: \(\mu_X\) (altezza media del gruppo), \(\mu_Y\) (peso medio del gruppo).
-
Varianze: \(\sigma_X^2\) (quanto varia l’altezza), \(\sigma_Y^2\) (quanto varia il peso).
- Correlazione: \(\rho\) (quanto \(X\) e \(Y\) sono legate, ad esempio: se l’altezza aumenta, di quanto aumenta solitamente il peso?).
Per un nuovo individuo con altezza \(x\) e peso \(y\), la distanza di Mahalanobis (\(D\)) si calcola così:
-
Calcolare le differenze rispetto alla media:
- Quanto si discosta l’altezza: \((x - \mu_X)\).
- Quanto si discosta il peso: \((y - \mu_Y)\).
-
Scalare le differenze con le varianze:
-
Dividere ogni differenza per la sua “variabilità tipica” (deviazione standard \(\sigma_X\) e \(\sigma_Y\)):
\[ \frac{(x - \mu_X)}{\sigma_X} \quad \text{e} \quad \frac{(y - \mu_Y)}{\sigma_Y} . \]
-
-
Correggere per la correlazione:
- Se \(X\) e \(Y\) sono correlate (\(\rho \neq 0\)), modifica le differenze per tenere conto di come di solito si “muovono insieme”.
- La formula finale combina tutto in un unico valore:
\[ D = \sqrt{ \frac{ \left( \frac{(x - \mu_X)}{\sigma_X} \right)^2 + \left( \frac{(y - \mu_Y)}{\sigma_Y} \right)^2 - 2 \rho \left( \frac{(x - \mu_X)}{\sigma_X} \right)\left( \frac{(y - \mu_Y)}{\sigma_Y} \right) }{1 - \rho^2} } \]
- Se \(X\) e \(Y\) sono correlate (\(\rho \neq 0\)), modifica le differenze per tenere conto di come di solito si “muovono insieme”.
Spiegazione:
- Senza correlazione (\(\rho = 0\)), sarebbe come una distanza Euclidea “scalata” dalle varianze.
- Con correlazione (\(\rho \neq 0\)), sottrai un termine che “aggiusta” la distanza in base a quanto \(X\) e \(Y\) tendono a variare insieme.
- Il denominatore \(1 - \rho^2\) normalizza il risultato, per evitare che la correlazione distorca troppo la misura.
Esempio:
Se tutti gli alti sono anche pesanti (\(\rho\) positivo), un individuo alto ma magro avrà una distanza di Mahalanobis maggiore rispetto a uno altrettanto alto ma pesante, perché viola la relazione tipica del gruppo.
ConsiglioDistanza Eucliea
Ricordiamo che la distanza euclidea tra due punti \((x_1, y_1)\) e \((x_2, y_2)\) in un piano cartesiano è definita come:
\[ d = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2} \]
Esempio in R:
Questo metodo è utile per dataset con più variabili correlate, come misure biometriche (altezza e peso).
Tuttavia, la versione classica di questa misura non è particolarmente robusta: la presenza stessa di outlier può distorcere il calcolo del “centro” e della variabilità complessiva, rendendo meno affidabile l’individuazione di altri valori anomali. Per questo motivo, si preferisce utilizzare una variante più resistente, la Minimum Covariance Determinant (MCD), che diminuisce l’influenza degli outlier stessi nel processo di identificazione.
All’interno del pacchetto {performance} in R, è possibile applicare questa variante robusta utilizzando la funzione check_outliers() con l’argomento method = "mcd". In questo modo, è possibile individuare gli outlier multivariati in maniera più solida e coerente, anche quando si lavora con dati fortemente influenzati da valori estremi.
d <- mtcars[, c("mpg", "hp")]
outliers <- performance::check_outliers(d, method = "mcd", verbose = FALSE)
outliers
#> 2 outliers detected: cases 20, 31.
#> - Based on the following method and threshold: mcd (13.816).
#> - For variables: mpg, hp.Si possono poi visualizzare questi outlier:
plot(outliers)
#> $threshold_outliers
#> [1] 20 31
#>
#> $threshold
#> [1] 13.8
#>
#> $elbow_outliers
#> [1] 31
#>
#> $elbow_threshold
#> [1] 6.41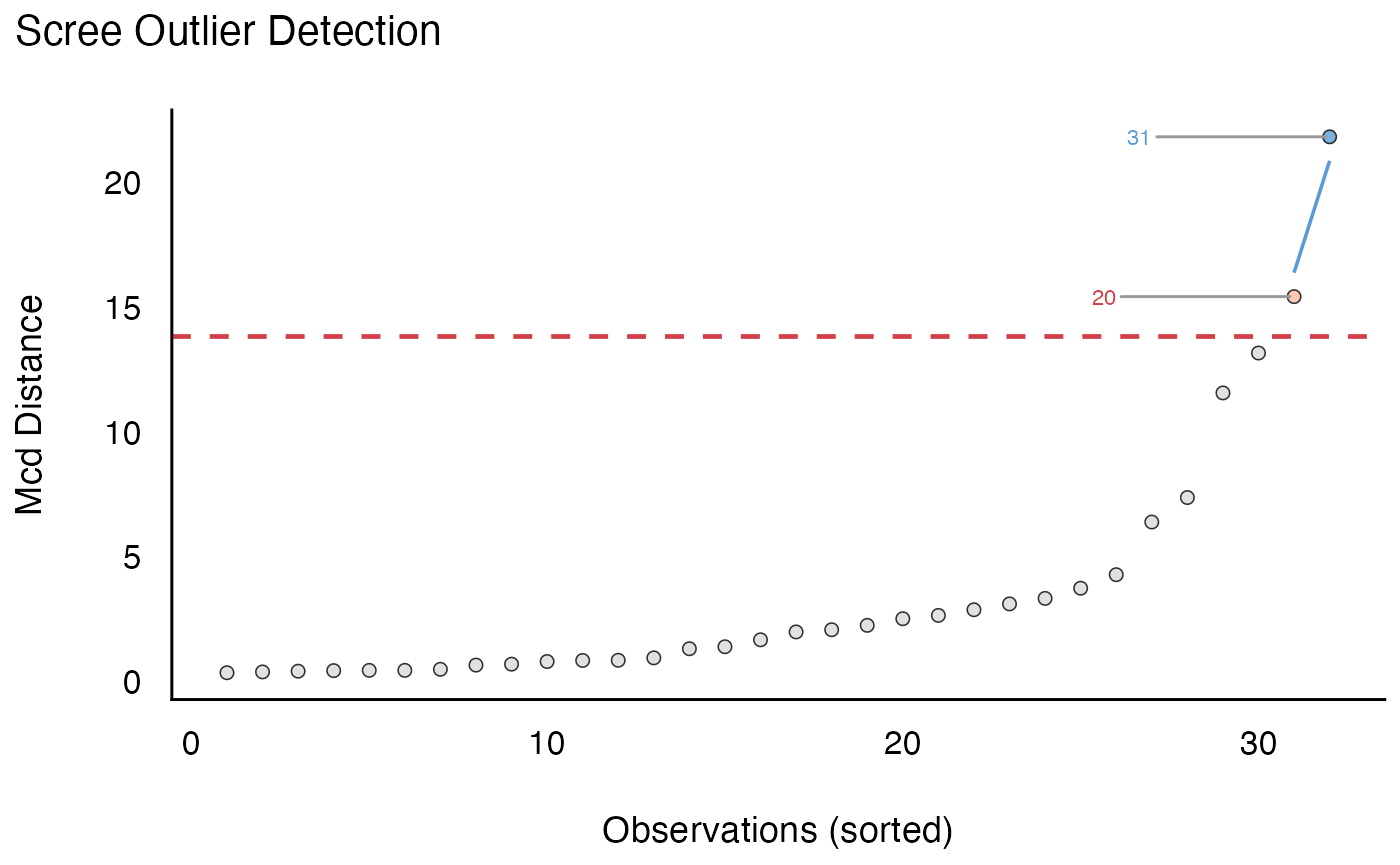
Sono disponibili anche altre varianti multivariate documentate nella help page della funzione.
22.4 Cosa fare con gli outlier?
Una volta identificati gli outlier, dobbiamo decidere se rimuoverli, correggerli o mantenerli (Leys et al., 2019). Alcuni approcci comuni includono:
- Verificare la fonte del dato: un errore di inserimento può essere corretto.
- Rimuovere gli outlier estremi: utile se il valore è chiaramente un errore di misura.
- Usare metodi robusti: strumenti come la mediana o il MAD sono meno influenzati dagli outlier.
- Trasformare i dati: applicare logaritmi o altre trasformazioni può ridurre l’impatto degli outlier.
- Winsorizzazione: invece di rimuovere gli outlier, possiamo limitarli a un massimo accettabile.
ConsiglioWinsorizzazione
La Winsorizzazione è una tecnica per gestire gli outlier senza eliminarli. Invece di scartare i valori estremi, questi vengono sostituiti con il valore più vicino ritenuto “accettabile”, preservando così la struttura e la dimensione del dataset.
Come si applica? Il procedimento si articola in due passaggi principali:
-
Definire le soglie
Si scelgono due percentili come limiti. Una scelta comune è utilizzare il 5° percentile per il limite inferiore e il 95° percentile per quello superiore.- I valori al di sotto del 5° percentile sono considerati outlier “bassi”.
- I valori al di sopra del 95° percentile sono considerati outlier “alti”.
- I percentili possono essere adattati (es. 1° e 99°) a seconda della necessità di essere più o meno conservativi.
-
Sostituire i valori
- Tutti i dati inferiori al limite inferiore vengono portati al valore di quel limite (es. 5° percentile).
- Tutti i dati superiori al limite superiore vengono portati al valore di quel limite (es. 95° percentile).
Esempio Pratico
Consideriamo i voti di 10 esami, ordinati:40, 55, 60, 65, 70, 75, 80, 85, 90, 200
- Limite inferiore (5° percentile): 55
- Limite superiore (95° percentile): 90
Applicando la Winsorizzazione:
- Il valore
40(outlier basso) viene sostituito con55. - Il valore
200(outlier alto) viene sostituito con90.
Dataset winsorizzato:55, 55, 60, 65, 70, 75, 80, 85, 90, 90
Vantaggi e Applicazioni
- Mantiene la dimensione del campione: non si perdono osservazioni, si “aggiustano” solo gli estremi.
- Robustezza statistica: riduce drasticamente l’influenza distorsiva degli outlier su indicatori sensibili come la media e la deviazione standard.
- Utilità pratica: è particolarmente utile in campi come la psicologia (per contenere l’effetto di misurazioni estreme), dove l’eliminazione dei dati non è sempre desiderabile o giustificabile.
Nel pacchetto easystats, la funzione winsorize() di datawizard semplifica il compito di Winsorizzazione:
winsorized_data <-
winsorize(data$value, method = "zscore", robust = TRUE, threshold = 3)22.5 Importanza della trasparenza
Qualunque scelta fatta nella gestione degli outlier deve essere documentata in modo completo e replicabile. La trasparenza richiede di specificare chiaramente quanti outlier sono stati individuati, descrivendo il metodo di identificazione e le soglie applicate. È fondamentale dichiarare in che modo sono stati gestiti, se mantenuti, corretti o esclusi, e fornire il codice utilizzato per l’intera procedura, preferibilmente in linguaggi come R o Python.
Questa tracciabilità metodologica costituisce la base di una ricerca rigorosa. Pratiche come la preregistrazione del protocollo analitico e la condivisione aperta di dati e codice su piattaforme quali OSF, GitHub o Zenodo non sono semplicemente raccomandabili, ma rappresentano ormai lo standard imprescindibile per assicurare riproducibilità, credibilità e integrità scientifica.
Riflessioni conclusive
L’analisi degli outlier non è una procedura meccanica o puramente tecnica, ma una scelta metodologica sostanziale. L’obiettivo delle buone pratiche non è quello di “ripulire” i dati automaticamente, quanto piuttosto di comprendere l’origine dei valori anomali, applicare metodi coerenti con gli obiettivi della ricerca, e documentare con trasparenza e giustificazione ogni decisione presa. In questo quadro, la gestione degli outlier non è un passaggio secondario, ma parte integrante di un’analisi dei dati responsabile, che mira a garantire rigore, riproducibilità e validità interpretativa dei risultati.
ImportanteProblemi 1
Domande teoriche
- Cos’è un outlier?
- Perché è importante identificare e trattare correttamente gli outlier?
- Descrivi brevemente il metodo del boxplot per identificare gli outlier.
- Cosa si intende per Interquartile Range (IQR) e come viene utilizzato per individuare gli outlier?
- Qual è la differenza tra il metodo IQR e il Median Absolute Deviation (MAD) per l’identificazione degli outlier?
- Cos’è la distanza di Mahalanobis e in che modo può aiutare nell’identificazione degli outlier multivariati?
- Perché la distanza di Mahalanobis classica potrebbe non essere robusta? Come si può migliorare l’approccio?
- Quali sono le opzioni per gestire gli outlier una volta identificati?
- Cos’è la Winsorizzazione e in quali casi potrebbe essere utile?
- Perché è importante la trasparenza nelle decisioni riguardanti gli outlier?
ConsiglioSoluzioni 1
-
Cos’è un outlier?
- Un outlier è un’osservazione che si discosta significativamente dalla maggior parte delle altre osservazioni in un insieme di dati. Può essere dovuto ad errori di misura, errori di inserimento dati o a casi estremi ma validi.
-
Perché è importante identificare e trattare correttamente gli outlier?
- Gli outlier possono distorcere i risultati dell’analisi statistica, portando a conclusioni errate. Identificarli e trattarli correttamente aiuta a ridurre l’effetto di questi valori anomali sulle statistiche descrittive e sulle inferenze statistiche.
-
Descrivi brevemente il metodo del boxplot per identificare gli outlier.
- Il boxplot visualizza la distribuzione di una variabile, mostrando la mediana, il primo e il terzo quartile, e due estremi (“whiskers”). I punti al di fuori di questi whiskers sono considerati potenziali outlier.
-
Cosa si intende per Interquartile Range (IQR) e come viene utilizzato per individuare gli outlier?
- L’IQR è la differenza tra il terzo e il primo quartile di un insieme di dati. Valori inferiori a \(Q1 - 1.5 \times IQR\) o superiori a \(Q3 + 1.5 \times IQR\) sono considerati outlier moderati. Valori oltre \(Q1 - 3 \times IQR\) o \(Q3 + 3 \times IQR\) sono definiti “far out” outliers.
-
Qual è la differenza tra il metodo IQR e il Median Absolute Deviation (MAD) per l’identificazione degli outlier?
- Il metodo IQR si basa sulla differenza tra il terzo e il primo quartile, mentre il MAD utilizza la mediana delle deviazioni assolute dalla mediana per stimare la dispersione. Il MAD è meno sensibile agli outlier rispetto all’IQR e alla deviazione standard, rendendolo preferibile per dati con distribuzioni non normali.
-
Cos’è la distanza di Mahalanobis e in che modo può aiutare nell’identificazione degli outlier multivariati?
- La distanza di Mahalanobis misura quanto un punto si discosta dal centro della distribuzione di un set di dati multivariato, tenendo conto della correlazione tra le variabili. Valori con distanze di Mahalanobis elevate sono potenziali outlier multivariati.
-
Perché la distanza di Mahalanobis classica potrebbe non essere robusta? Come si può migliorare l’approccio?
- La distanza di Mahalanobis classica può essere distorta dalla presenza di outlier, che influenzano il calcolo del centro e della variabilità complessiva. Un approccio più robusto è la Minimum Covariance Determinant (MCD), che riduce l’influenza degli outlier nel processo di identificazione.
-
Quali sono le opzioni per gestire gli outlier una volta identificati?
- Le opzioni includono: verificare la fonte del dato per possibili errori, rimuovere gli outlier estremi, usare metodi robusti come la mediana o il MAD, trasformare i dati (ad esempio, logaritmi), e limitare gli outlier attraverso la Winsorizzazione.
-
Cos’è la Winsorizzazione e in quali casi potrebbe essere utile?
- La Winsorizzazione è una tecnica che consiste nel sostituire gli outlier estremi con il valore massimo o minimo accettabile. È utile quando si vuole mantenere la dimensione del dataset e ridurre l’impatto degli outlier senza rimuoverli completamente.
Perché è importante la trasparenza nelle decisioni riguardanti gli outlier?
- La trasparenza aiuta a garantire la riproducibilità e la validità dell’analisi. Documentare le decisioni, inclusi i metodi e i threshold utilizzati, consente ad altri di capire e valutare l’impatto di queste decisioni sui risultati dell’analisi.
ImportanteProblemi 2
Esercizio: Gestione degli Outlier nella Scala di Soddisfazione di Vita (SWLS)
Scopo:
Imparare a individuare e correggere gli outlier in un dataset che misura la soddisfazione di vita (SWLS). L’esercizio prevede l’inserimento artificiale di due outlier (uno molto alto e uno molto basso) nei dati raccolti, per poi gestirli con i metodi discussi nel capitolo. Infine, bisognerà consegnare:
- Un file
.qmd(Quarto) con tutto il codice e i commenti delle operazioni svolte.
- Un file CSV finale con i dati “puliti” (ossia senza i due outlier anomali) o con i valori modificati mediante il metodo scelto (winsorizzazione, rimozione, correzione, ecc.).
Fasi e Istruzioni
-
Scarica o carica il dataset SWLS
- Nominare il dataset originale, ad esempio SWLS_raw.csv, contenente i punteggi dei partecipanti sulla Scala di Soddisfazione di Vita (SWLS).
- Assicurati di avere nel dataset almeno le colonne:
-
id(identificatore univoco del partecipante)
-
swls_score(punteggio totale alla scala SWLS)
-
- Nominare il dataset originale, ad esempio SWLS_raw.csv, contenente i punteggi dei partecipanti sulla Scala di Soddisfazione di Vita (SWLS).
-
Crea due outlier artificiali
- Scegli un partecipante al quale assegnare un valore estremamente basso di
swls_score(es. -999) e un altro partecipante con un valore estremamente alto (es. 999).
- Spiega brevemente nel
.qmddove e come hai inserito questi valori.
- Scegli un partecipante al quale assegnare un valore estremamente basso di
-
Analizza i dati alla ricerca di outlier
- Visualizza la distribuzione tramite un boxplot e/o un istogramma.
- Calcola i valori soglia utilizzando almeno uno dei metodi visti:
- IQR (intervallo interquartile)
- MAD (Median Absolute Deviation)
- IQR (intervallo interquartile)
- Mostra quali osservazioni vengono segnalate come potenziali outlier.
- Visualizza la distribuzione tramite un boxplot e/o un istogramma.
-
Decidi come gestire gli outlier
- Scegli se rimuoverli, winsorizzarli o correggerli.
- Giustifica la tua scelta: spiega perché quel metodo è appropriato per questi dati o perché preferisci un approccio rispetto a un altro.
- Scegli se rimuoverli, winsorizzarli o correggerli.
-
Genera i dati “puliti”
- Applica il metodo selezionato.
- Salva il dataset risultante (senza i valori anomali o con i valori modificati) in un file CSV chiamato SWLS_clean.csv.
- Applica il metodo selezionato.
-
Documenta tutto in un file
.qmd- Includi codice R, commenti e brevi spiegazioni testuali dei vari passaggi.
- Mostra i risultati rilevanti (boxplot, calcolo dei soglie IQR/MAD, elenco degli outlier individuati, ecc.).
- Assicurati di eseguire il rendering del
.qmdin modo che l’istruttore possa vedere sia l’output che il codice.
- Includi codice R, commenti e brevi spiegazioni testuali dei vari passaggi.
-
Consegnare i file
-
File .qmd: deve contenere tutto il codice e i passaggi effettuati (inclusi grafici, calcoli e spiegazioni).
- File CSV “pulito” (SWLS_clean.csv): con i dati finali dopo il trattamento degli outlier.
-
File .qmd: deve contenere tutto il codice e i passaggi effettuati (inclusi grafici, calcoli e spiegazioni).
Suggerimenti
-
Struttura il tuo
.qmdin sezioni (ad es. Caricamento dati, Creazione outlier artificiali, Identificazione outlier, Gestione outlier, Salvataggio dati puliti).
-
Motiva sempre le scelte, soprattutto se rimuovi o modifichi i dati originali: spiega perché il valore appare come un errore di misura o un valore estremo.
-
Fai controlli incrociati: potresti usare più di un metodo (boxplot, IQR, MAD) per vedere se l’outlier viene segnalato in tutti i casi.
- Documenta la tua strategia di trasparenza nell’analisi: note sull’eventuale preregistrazione di come avresti gestito gli outlier o su come hai deciso i threshold.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] MASS_7.3-65 datawizard_1.3.0 see_0.12.0
#> [4] performance_0.15.2 ragg_1.5.0 tinytable_0.15.2
#> [7] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [10] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.15.0
#> [13] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [16] posterior_1.6.1 loo_2.9.0 rstan_2.32.7
#> [19] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [22] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [25] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [28] dplyr_1.1.4 tidyr_1.3.2 rio_1.2.4
#> [31] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.1
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [40] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [43] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [46] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [49] checkmate_2.3.3 stats4_4.5.2 insight_1.4.4
#> [52] distributional_0.5.0 generics_0.1.4 rprojroot_2.1.1
#> [55] rstantools_2.5.0 scales_1.4.0 xtable_1.8-4
#> [58] glue_1.8.0 emmeans_2.0.1 tools_4.5.2
#> [61] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [64] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [67] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [70] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [73] ggrepel_0.9.6 TH.data_1.1-5 htmlwidgets_1.6.4
#> [76] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [79] lifecycle_1.0.5Bibliografia
Leys, C., Delacre, M., Mora, Y. L., Lakens, D., & Ley, C. (2019). How to classify, detect, and manage univariate and multivariate outliers, with emphasis on pre-registration. International Review of Social Psychology, 32(1).
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological science, 22(11), 1359–1366.
Thériault, R., Ben-Shachar, M. S., Patil, I., Lüdecke, D., Wiernik, B. M., & Makowski, D. (2024). Check your outliers! An introduction to identifying statistical outliers in R with easystats. Behavior Research Methods, 56(4), 4162–4172.