here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(janitor, viridis, vcd, ggbeeswarm, dslabs)16 Esplorare distribuzioni univariate
Dal dato grezzo al pattern riconoscibile
Prerequisiti
ConsiglioLetture consigliate
Prima di procedere, familiarizzati con questi concetti attraverso:
- Exploring categorical data di Mine Çetinkaya-Rundel e Johanna Hardin
- Exploring numerical data degli stessi autori
- L’Appendice ?sec-apx-sums per un ripasso dei concetti matematici di base
AttenzionePreparazione del Notebook
16.1 Due nature del dato psicologico
I dati che incontriamo in psicologia hanno natura profondamente diversa. Da un lato, raccogliamo informazioni qualitative: il genere dei partecipanti, la diagnosi clinica, il tipo di intervento ricevuto e la condizione sperimentale assegnata. Queste variabili categorizzano il mondo in classi discrete, in etichette che distinguono senza necessariamente ordinare. Dall’altro lato, misuriamo quantità numeriche: punteggi di questionari, tempi di reazione, parametri fisiologici e scale di valutazione. Queste variabili posizionano ogni osservazione su un continuum, consentendoci di parlare di “più” o “meno”, di distanze e di medie.
Questa fondamentale distinzione richiede strumenti analitici diversi. Non ha senso calcolare la media del genere, così come sarebbe riduttivo considerare un punteggio BDI come una semplice categoria. Eppure, entrambe le nature dei dati richiedono lo stesso rigore esplorativo: dobbiamo capire come si distribuiscono le osservazioni, dove si concentrano, quali combinazioni sono frequenti o rare e quali pattern emergono quando le stratifichiamo per gruppi.
Inizieremo esplorando le variabili categoriali, per poi passare a quelle numeriche, scoprendo che le domande fondamentali rimangono invariate anche quando cambiano gli strumenti per rispondere.
16.2 Parte I: quando i dati appartengono a categorie
16.2.1 I pinguini di Palmer
Per esplorare i dati categoriali useremo il dataset palmerpenguins, raccolto da Kristen Gorman presso la Palmer Station in Antartide. Questo dataset documenta 344 pinguini appartenenti a tre specie (Adelie, Chinstrap, Gentoo), osservati su tre isole dell’arcipelago di Palmer. Oltre alle variabili categoriali come specie, isola e genere, il dataset include misure morfometriche che esploreremo nella seconda parte del capitolo.
d <- rio::import(here("data", "penguins.csv"))
# Rimuoviamo le osservazioni incomplete per semplicità
df_penguins <- d |> drop_na()
glimpse(df_penguins)
#> Rows: 333
#> Columns: 8
#> $ species <chr> "Adelie", "Adelie", "Adelie", "Adelie", "Adelie", "A…
#> $ island <chr> "Torgersen", "Torgersen", "Torgersen", "Torgersen", …
#> $ bill_length_mm <dbl> 39.1, 39.5, 40.3, 36.7, 39.3, 38.9, 39.2, 41.1, 38.6…
#> $ bill_depth_mm <dbl> 18.7, 17.4, 18.0, 19.3, 20.6, 17.8, 19.6, 17.6, 21.2…
#> $ flipper_length_mm <int> 181, 186, 195, 193, 190, 181, 195, 182, 191, 198, 18…
#> $ body_mass_g <int> 3750, 3800, 3250, 3450, 3650, 3625, 4675, 3200, 3800…
#> $ sex <chr> "male", "female", "female", "female", "male", "femal…
#> $ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…16.2.2 Contare per capire: le tabelle di contingenza
La prima domanda che ci poniamo di fronte a variabili categoriali è disarmante nella sua semplicità: quanti? Quanti pinguini per specie? Quanti maschi e femmine? Quante osservazioni per isola? Questa apparente banalità nasconde in realtà il nucleo dell’analisi esplorativa categoriale: la distribuzione delle frequenze, infatti, rivela immediatamente squilibri, assenze inattese e concentrazioni che suggeriscono pattern biologici o artefatti della raccolta dati.
Le tabelle di contingenza organizzano questi conteggi quando vogliamo esaminare due variabili simultaneamente. Ogni cella della tabella risponde alla domanda: quante osservazioni condividono questa specifica combinazione di attributi? Nel nostro caso, possiamo chiederci come si distribuiscono le specie nelle diverse isole.
df_penguins |>
tabyl(island, species) |>
adorn_totals(c("row", "col"))
#> island Adelie Chinstrap Gentoo Total
#> Biscoe 44 0 119 163
#> Dream 55 68 0 123
#> Torgersen 47 0 0 47
#> Total 146 68 119 333La tabella rivela immediatamente un interessante pattern ecologico: la specie Adelie è ubiquitaria, presente su tutte e tre le isole. I pinguini Chinstrap, invece, abitano esclusivamente l’isola Dream, mentre i pinguini Gentoo si trovano solo a Biscoe. Questa distribuzione non uniforme potrebbe riflettere preferenze ecologiche, storia evolutiva o semplicemente il disegno di campionamento dello studio. L’analisi esplorativa non ci dice il perché di questi pattern, ma ce li rende visibili, così da poter formulare ipotesi informate.
16.2.3 Proporzioni: quando i numeri assoluti ingannano
I conteggi grezzi, però, possono essere fuorvianti quando confrontiamo gruppi di dimensioni diverse. Se un’isola ospita molti più pinguini di un’altra, il semplice conteggio non ci dice se una specie è effettivamente più predominante in quella località. Per questo motivo, è necessario utilizzare le proporzioni, che normalizzano i conteggi rispetto ai totali di riga o colonna.
Le proporzioni di riga ci dicono: “All’interno di questa isola, quale percentuale di pinguini appartiene a ciascuna specie?”.
df_penguins |>
tabyl(island, species) |>
adorn_percentages("row") |>
adorn_totals("col") |>
adorn_pct_formatting(digits = 2)
#> island Adelie Chinstrap Gentoo Total
#> Biscoe 26.99% 0.00% 73.01% 100.00%
#> Dream 44.72% 55.28% 0.00% 100.00%
#> Torgersen 100.00% 0.00% 0.00% 100.00%Le proporzioni di colonna invertono la prospettiva: “All’interno di questa specie, quale percentuale di individui vive su ciascuna isola?”
df_penguins |>
tabyl(island, species) |>
adorn_percentages("col") |>
adorn_totals("row") |>
adorn_pct_formatting(digits = 2)
#> island Adelie Chinstrap Gentoo
#> Biscoe 30.14% 0.00% 100.00%
#> Dream 37.67% 100.00% 0.00%
#> Torgersen 32.19% 0.00% 0.00%
#> Total 100.00% 100.00% 100.00%Queste due prospettive complementari rispondono a domande diverse. La prima ci aiuta a caratterizzare la composizione di ciascuna isola, la seconda a capire come ciascuna specie si distribuisce geograficamente. La scelta tra proporzioni di riga e di colonna dipende dalla domanda di ricerca e non da preferenze estetiche.
16.2.4 Visualizzare categorie: i grafici a barre
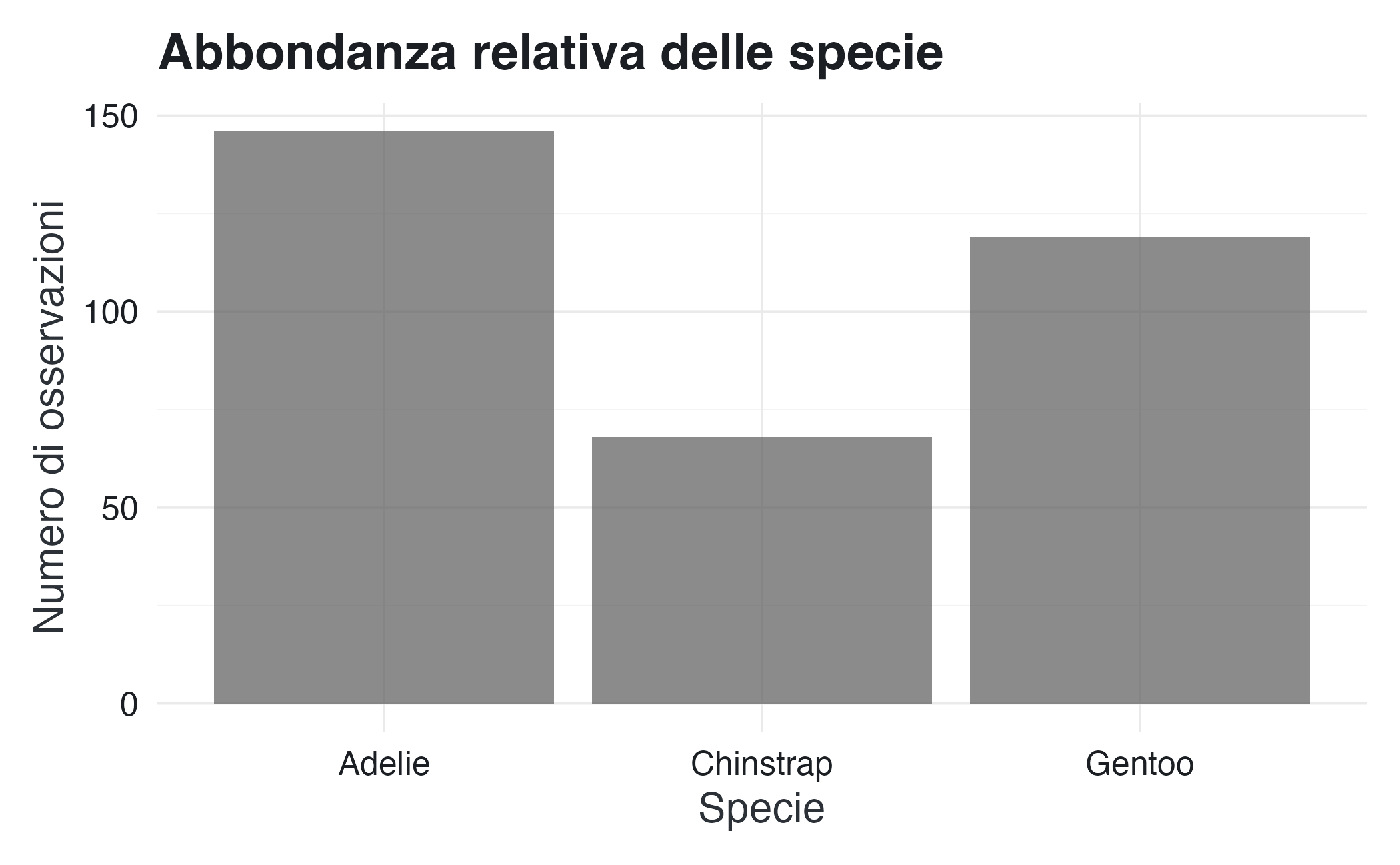
I numeri nelle tabelle sono precisi, ma la percezione visiva permette di cogliere pattern che sfuggono all’ispezione sequenziale propria della letturamdi una tabella. I grafici a barre traducono le frequenze in altezze, permettendoci di confrontare le categorie con un colpo d’occhio. Iniziamo con una singola variabile categoriale: la distribuzione delle specie.
ggplot(df_penguins, aes(x = species)) +
geom_bar(alpha = 0.7) +
labs(
x = "Specie",
y = "Numero di osservazioni",
title = "Abbondanza relativa delle specie"
)
Quando vogliamo visualizzare due variabili categoriali simultaneamente, possiamo stratificare le barre utilizzando colori diversi. Questo approccio mantiene l’immediatezza del confronto visivo, aggiungendo però una dimensione informativa.
ggplot(df_penguins, aes(x = island, fill = species)) +
geom_bar(position = "stack", alpha = 0.8) +
scale_color_qualitative() +
labs(
x = "Isola",
y = "Numero di osservazioni",
fill = "Specie",
title = "Composizione delle comunità per isola"
) 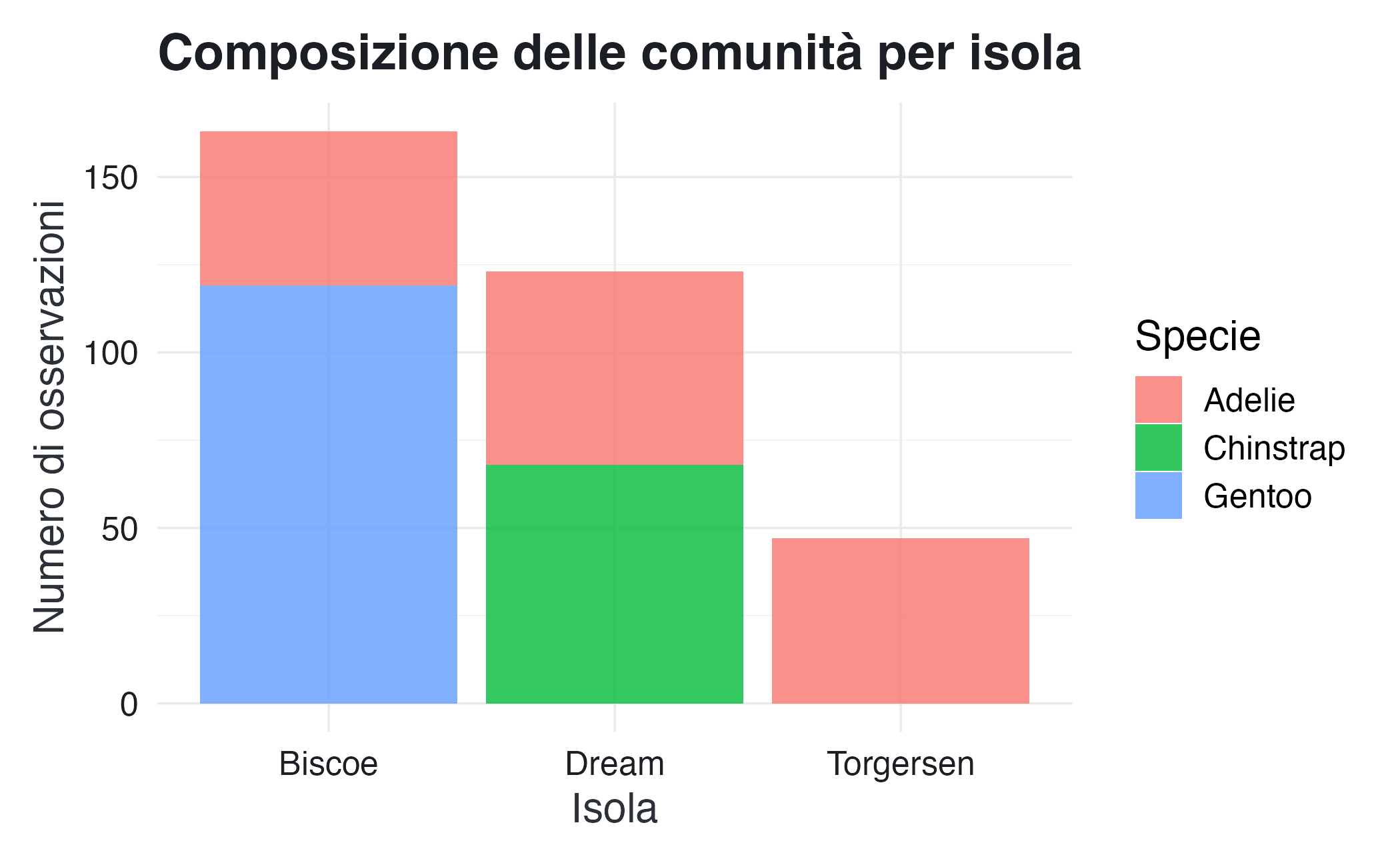
Le barre impilate mostrano chiaramente che Biscoe ospita molti più pinguini rispetto alle altre isole, ma questa abbondanza è dovuta principalmente alla popolazione di pinguini Gentoo. Se invece vogliamo mettere in risalto le proporzioni relative piuttosto che i conteggi assoluti, normalizziamo le altezze delle barre a 1.
ggplot(df_penguins, aes(x = island, fill = species)) +
geom_bar(position = "fill", alpha = 0.8) +
scale_color_qualitative() +
labs(
x = "Isola",
y = "Proporzione",
fill = "Specie",
title = "Dominanza relativa: quale specie prevale dove?"
) 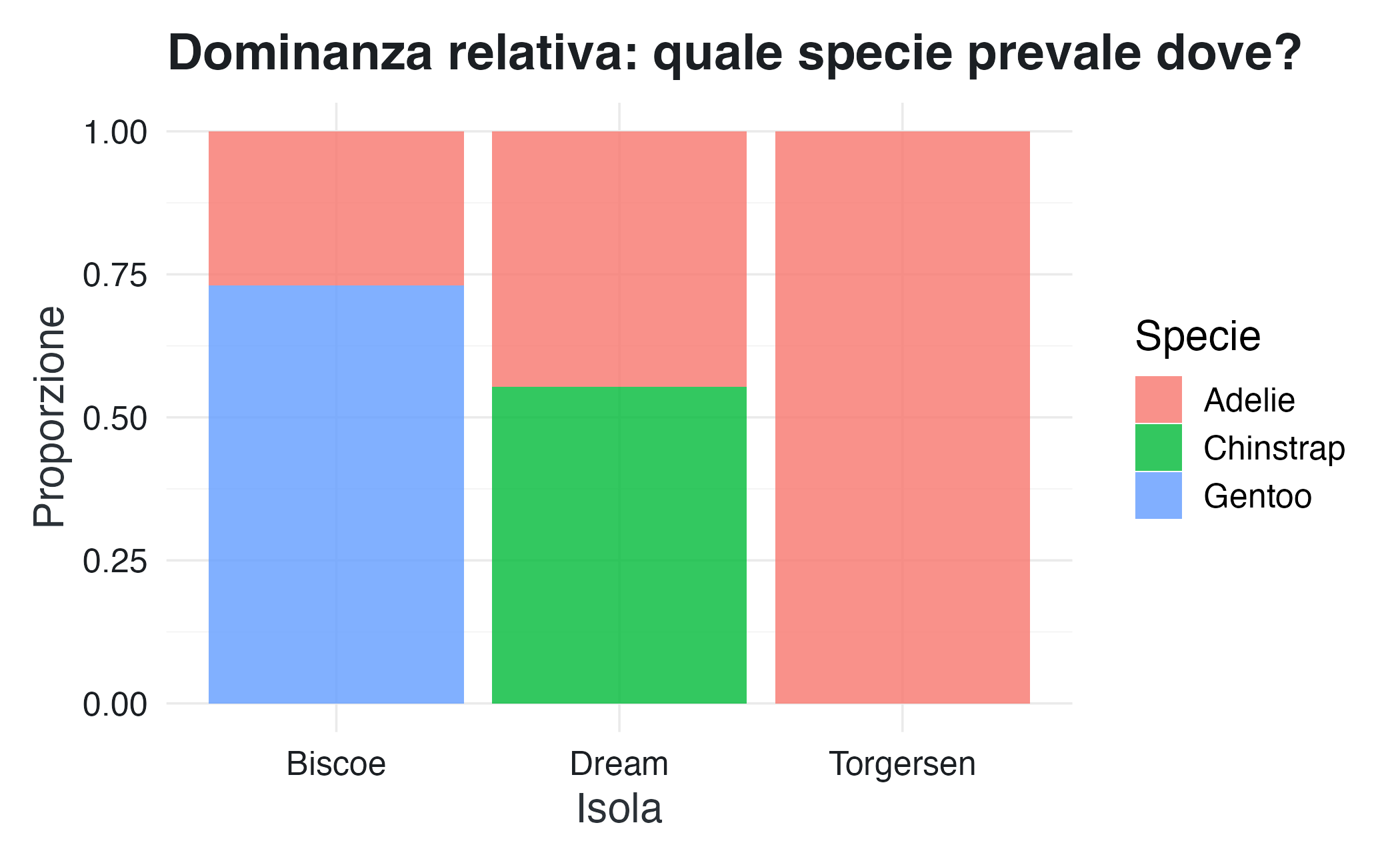
Ora ogni barra ha la stessa altezza, ma la suddivisione interna rivela che Dream è l’unica isola in cui coesistono due specie in proporzioni comparabili, mentre Biscoe è dominata dai pinguini Gentoo e Torgersen ospita esclusivamente i pinguini Adelie.
16.2.5 Mosaic plot: quando le dimensioni contano
I grafici a barre normalizzati presentano un limite: celano le differenze di dimensione assoluta tra i gruppi. Se un’isola ha 10 pinguini e un’altra 200, questo fatto scompare quando si normalizza a 1. Il mosaic plot risolve elegantemente questo problema, in quanto visualizza simultaneamente la dimensione relativa dei gruppi e la loro composizione interna.
mosaic(
~ species + island,
data = df_penguins,
main = "Distribuzione geografica delle specie",
shade = TRUE,
legend = TRUE
)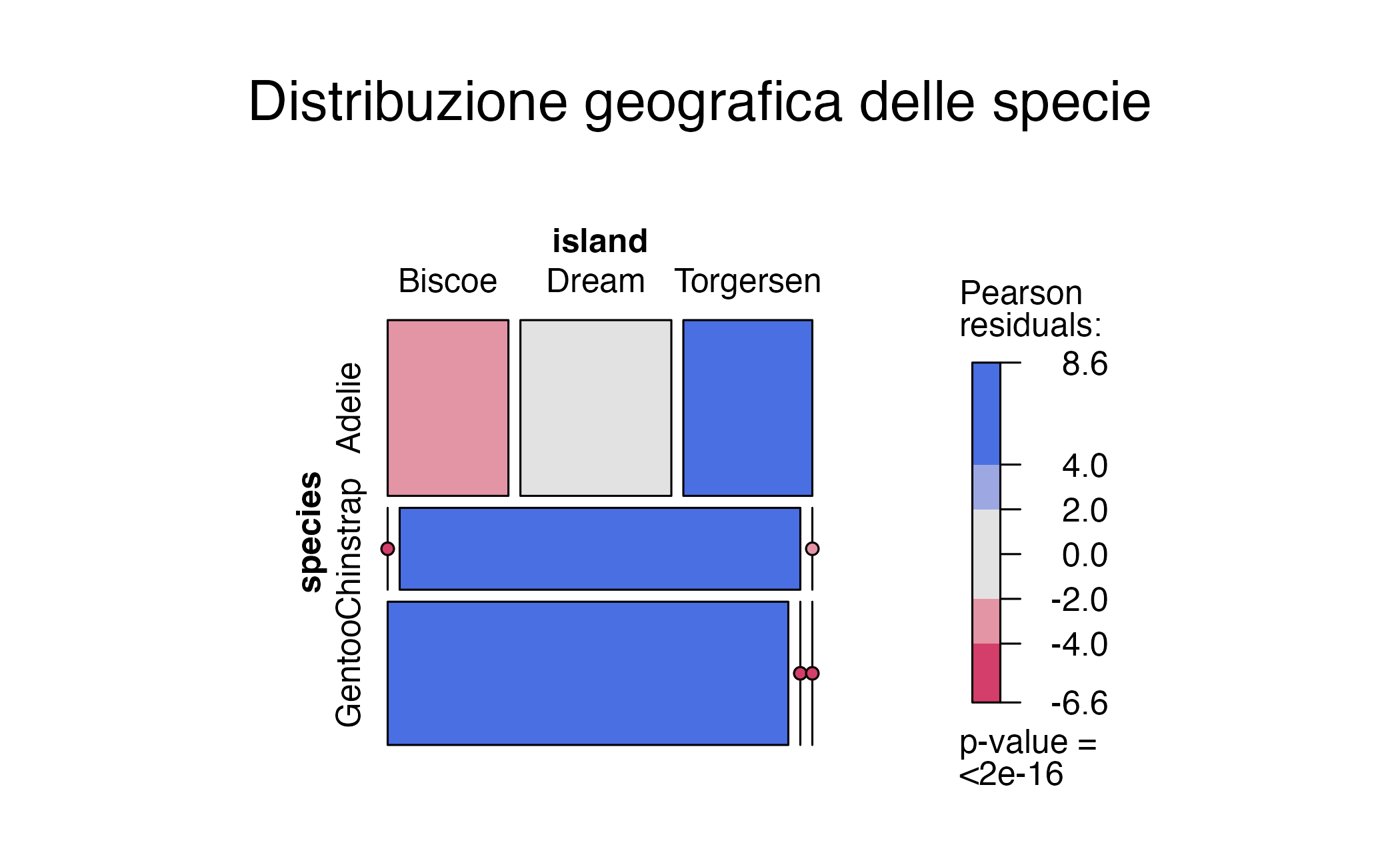
Nel mosaic plot, la larghezza di ogni rettangolo rappresenta la dimensione relativa del gruppo (in questo caso, la specie), mentre l’altezza all’interno di ogni colonna mostra come quella specie si distribuisce tra le isole. I colori (quando shade = TRUE) evidenziano le deviazioni dalle frequenze attese se le specie e le isole fossero indipendenti: le tonalità più scure indicano associazioni più forti del previsto.
Il grafico rivela immediatamente che i pinguini Gentoo sono numerosi, ma confinati a Biscoe; i pinguini Chinstrap sono meno abbondanti e più esclusivi di Dream, mentre i pinguini Adelie sono la specie più diffusa geograficamente, ma anche quella più frammentata.
16.2.6 Confrontare distribuzioni categoriali
L’analisi esplorativa spesso richiede il confronto della distribuzione di una variabile categoriale rispetto a un’altra. Per esempio, possiamo chiederci se il rapporto tra maschi e femmine è bilanciato all’interno di ciascuna specie. Questo tipo di domanda combina stratificazione e visualizzazione.
ggplot(df_penguins, aes(x = species, fill = sex)) +
geom_bar(position = "dodge", alpha = 0.7) +
scale_color_qualitative() +
labs(
x = "Specie",
y = "Numero di osservazioni",
fill = "Genere",
title = "Rapporto tra generi: c'è equilibrio?"
) 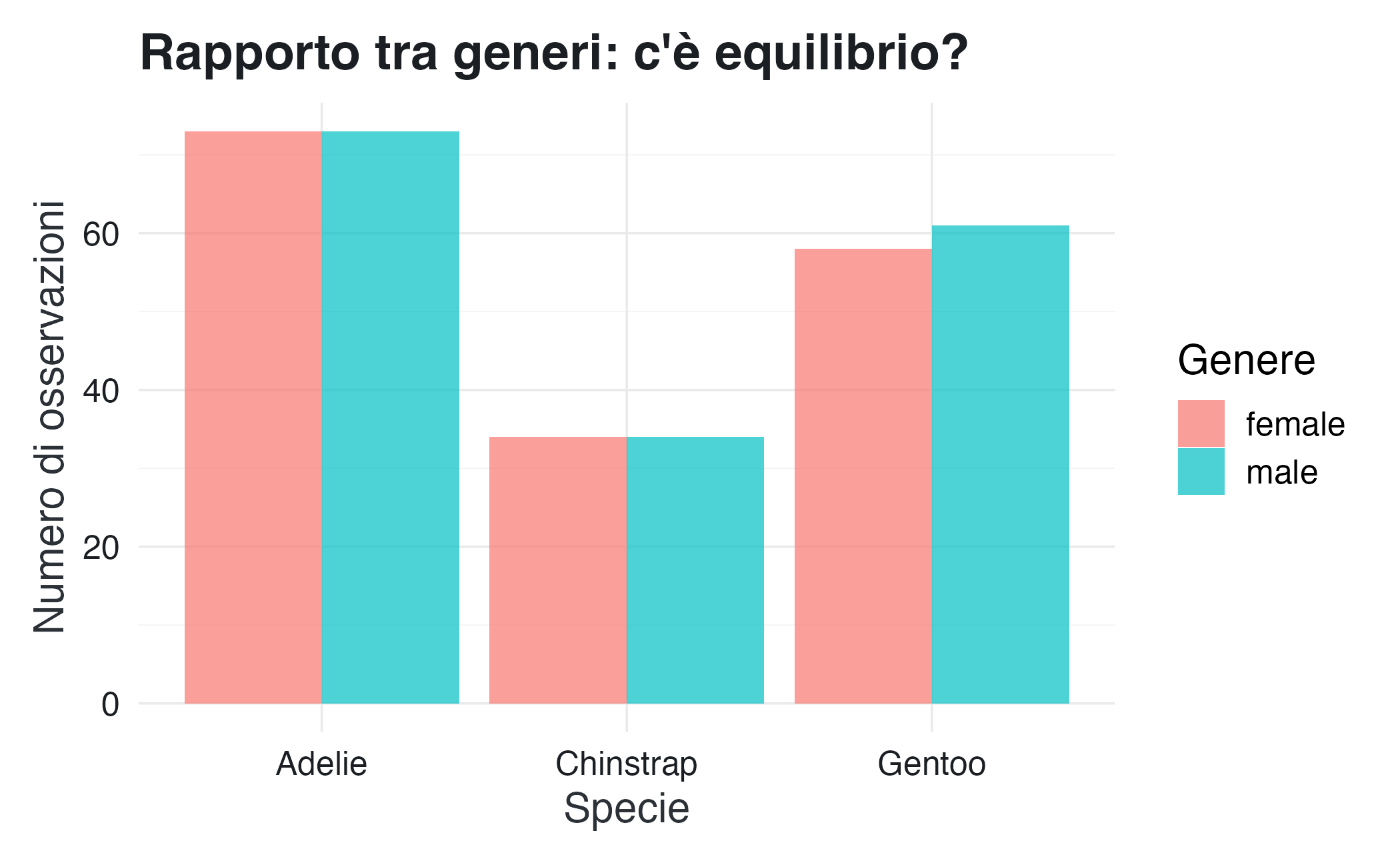
Le barre affiancate (position = "dodge") facilitano il confronto diretto dei conteggi per genere all’interno di ciascuna specie. Il campione appare ragionevolmente bilanciato, sebbene presenti lievi asimmetrie, probabilmente dovute alla casualità del campionamento o a differenze comportamentali che influenzano la probabilità di cattura.
16.3 Parte II: quando i dati si distribuiscono su continuità
16.3.1 Dalle categorie alle quantità
Passiamo ora a esaminare variabili numeriche, quelle che misurano quantità su scale continue piuttosto che appartenenze a classi discrete. In psicologia clinica, per esempio, i punteggi ottenuti con questionari standardizzati come il Beck Depression Inventory (BDI-II) collocano ogni individuo su un continuum di gravità dei sintomi. A differenza delle categorie diagnostiche (“depresso” vs. “non depresso”), questi punteggi catturano le sfumature e le gradazioni.
Per esplorare i dati numerici useremo un dataset di Zetsche et al. (2019) che indaga il ruolo delle aspettative negative nel mantenimento della depressione. Lo studio ha messo a confronto pazienti affetti da disturbo depressivo maggiore (MDD) e soggetti sani, raccogliendo, tra le altre cose, i punteggi BDI-II.
df_dep <- rio::import(here("data", "data.mood.csv"))
# Selezioniamo le variabili rilevanti
df_dep <- df_dep |>
select(esm_id, group, bdi) |>
# Rimuoviamo duplicati (un solo BDI per partecipante)
distinct() |>
# Eliminiamo missing
drop_na(bdi) |>
# Convertiamo group in factor
mutate(group = factor(group, levels = c("ctl", "mdd")))
glimpse(df_dep)
#> Rows: 66
#> Columns: 3
#> $ esm_id <int> 10, 9, 6, 7, 12, 16, 21, 18, 20, 22, 23, 25, 24, 26, 41, 31, 27…
#> $ group <fct> mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd, mdd…
#> $ bdi <int> 25, 30, 26, 35, 44, 30, 22, 33, 43, 43, 24, 39, 19, 3, 0, 25, 0…16.3.2 Prima di visualizzare: riassunti numerici
Prima di costruire i grafici, è buona norma ottenere dei riassunti numerici che ci aiutino a capire la natura della distribuzione. La funzione summary() fornisce quartili e media, rivelando immediatamente se ci sono valori estremi o asimmetrie.
summary(df_dep$bdi)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.00 0.25 6.00 14.94 29.50 44.00I punteggi del BDI-II variano da un minimo di 1 (assenza di sintomi) a un massimo di 45 (sintomatologia severa). La mediana (19) è notevolmente inferiore alla media (21.7), il che suggerisce una distribuzione asimmetrica con coda destra, tipica quando un sottogruppo di individui presenta valori molto elevati.
16.3.3 Distribuzioni di frequenza: l’arte di riassumere
Quando ci troviamo di fronte a un gran numero di valori numerici distinti, una visualizzazione puntuale di tutti i dati rischia di produrre confusione e rumore visivo. Una strategia più efficace consiste nel raggruppare i valori in classi (o intervalli) e contare quante osservazioni appartengono a ciascuna. Questa operazione porta alla costruzione di una distribuzione di frequenza, che permette di cogliere con immediatezza la struttura e le tendenze sottostanti ai dati.
Nel caso specifico del BDI-II, l’interpretazione dei punteggi si basa su soglie cliniche standardizzate che riflettono diversi livelli di gravità:
- 0–13: depressione minima
- 14–19: depressione lieve-moderata
- 20–28: depressione moderata-severa
- 29–63: depressione severa
Possiamo sfruttare questi criteri per creare una variabile categoriale e calcolare la relativa frequenza, rendendo così immediatamente evidente la composizione del campione rispetto ai livelli clinici di riferimento.
df_dep <- df_dep |>
mutate(
bdi_class = cut(
bdi,
breaks = c(0, 13.5, 19.5, 28.5, 63),
labels = c("Minima", "Lieve-mod", "Mod-sev", "Severa"),
include.lowest = TRUE
)
)
# Frequenze assolute
table(df_dep$bdi_class)
#>
#> Minima Lieve-mod Mod-sev Severa
#> 36 1 12 17
# Frequenze relative (proporzioni)
prop.table(table(df_dep$bdi_class)) |> round(3)
#>
#> Minima Lieve-mod Mod-sev Severa
#> 0.545 0.015 0.182 0.258Circa il 36% del campione presenta una sintomatologia minima, mentre quasi un terzo (il 30%) rientra nella fascia severa. Questa bimodalità riflette la composizione del campione: controlli sani versus pazienti clinici.
16.3.4 Distribuzioni cumulative: quanto sta sotto?
Una distribuzione cumulativa empirica (eCDF) ci dice, per ogni valore \(a\), quale proporzione di dati è minore o uguale ad \(a\). Matematicamente:
\[F(a) = P(X \leq a) = \frac{\text{conteggio di }X \leq a}{n}\]
Questa rappresentazione è particolarmente utile per identificare percentili e valutare rapidamente la dispersione.
ggplot(df_dep, aes(x = bdi)) +
stat_ecdf(geom = "step", linewidth = 1, color = "darkblue") +
labs(
x = "Punteggio BDI-II",
y = "Proporzione cumulativa F(x)",
title = "eCDF: quanti sono sotto ogni soglia?"
) +
geom_hline(yintercept = c(0.25, 0.5, 0.75),
linetype = "dashed", alpha = 0.3)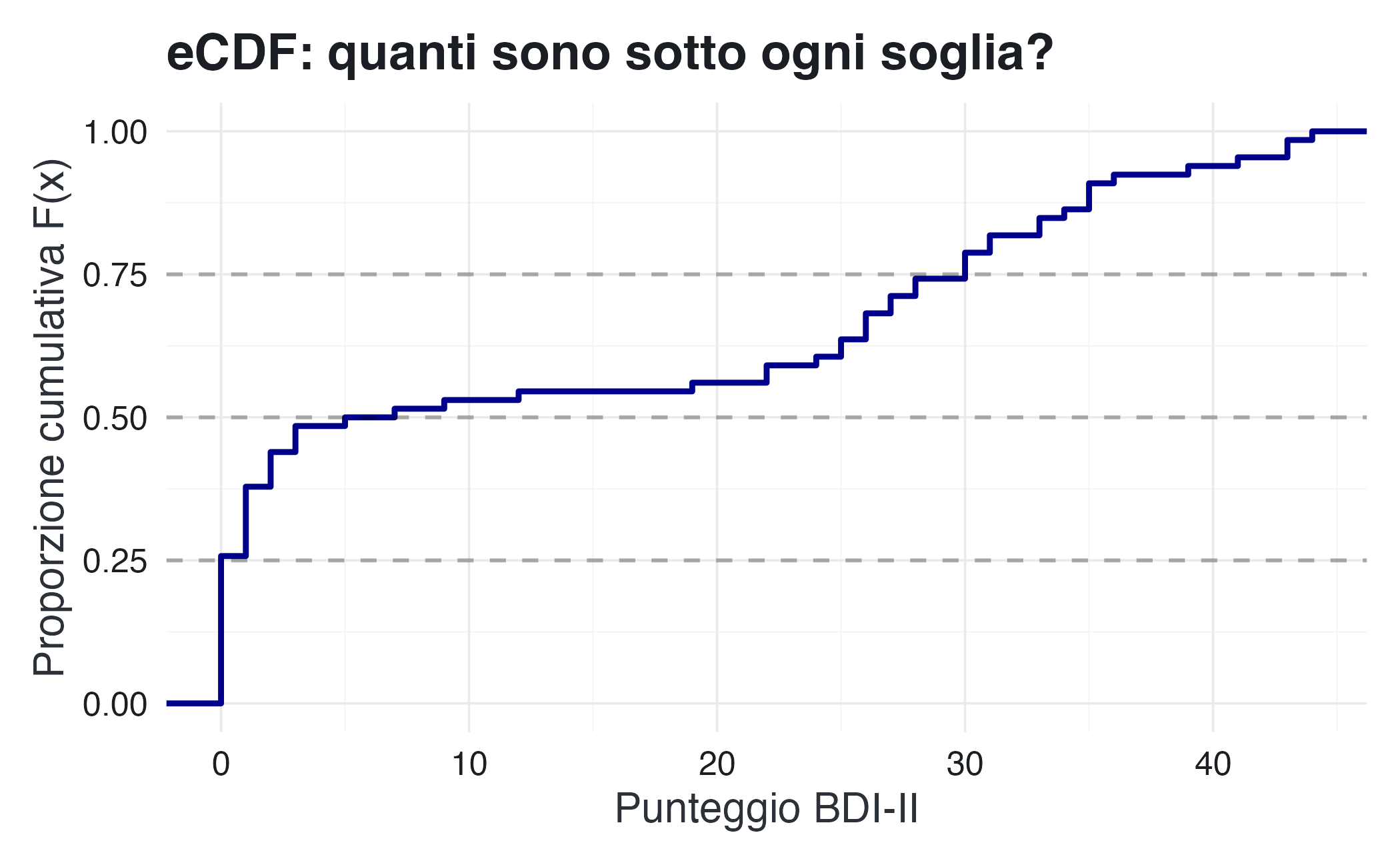
La curva presenta un andamento a gradini, tipico dei dati discreti. L’inflection point intorno al punteggio 20 suggerisce che in quel punto si concentra una transizione importante nella distribuzione, probabilmente il confine tra controlli e pazienti.
16.3.5 Istogrammi: la forma della distribuzione
Sebbene l’eCDF sia precisa, non permette di visualizzare immediatamente la forma della distribuzione, ovvero dove si concentrano i dati, se ci sono picchi multipli e quanto è dispersa la variabilità. Gli istogrammi sacrificano un po’ di precisione in cambio di un’immediata intuizione visiva.
Un istogramma suddivide l’asse dei valori in intervalli (bin) di ampiezza uguale e rappresenta la densità delle osservazioni in ciascun bin con l’altezza delle barre. L’area di ogni rettangolo è proporzionale alla frequenza relativa, e l’area totale è normalizzata a 1.
ggplot(df_dep, aes(x = bdi)) +
geom_histogram(
aes(y = after_stat(density)),
binwidth = 3,
color = "white",
alpha = 0.7
) +
labs(
x = "Punteggio BDI-II",
y = "Densità",
title = "Istogramma: la bimodalità emerge"
) 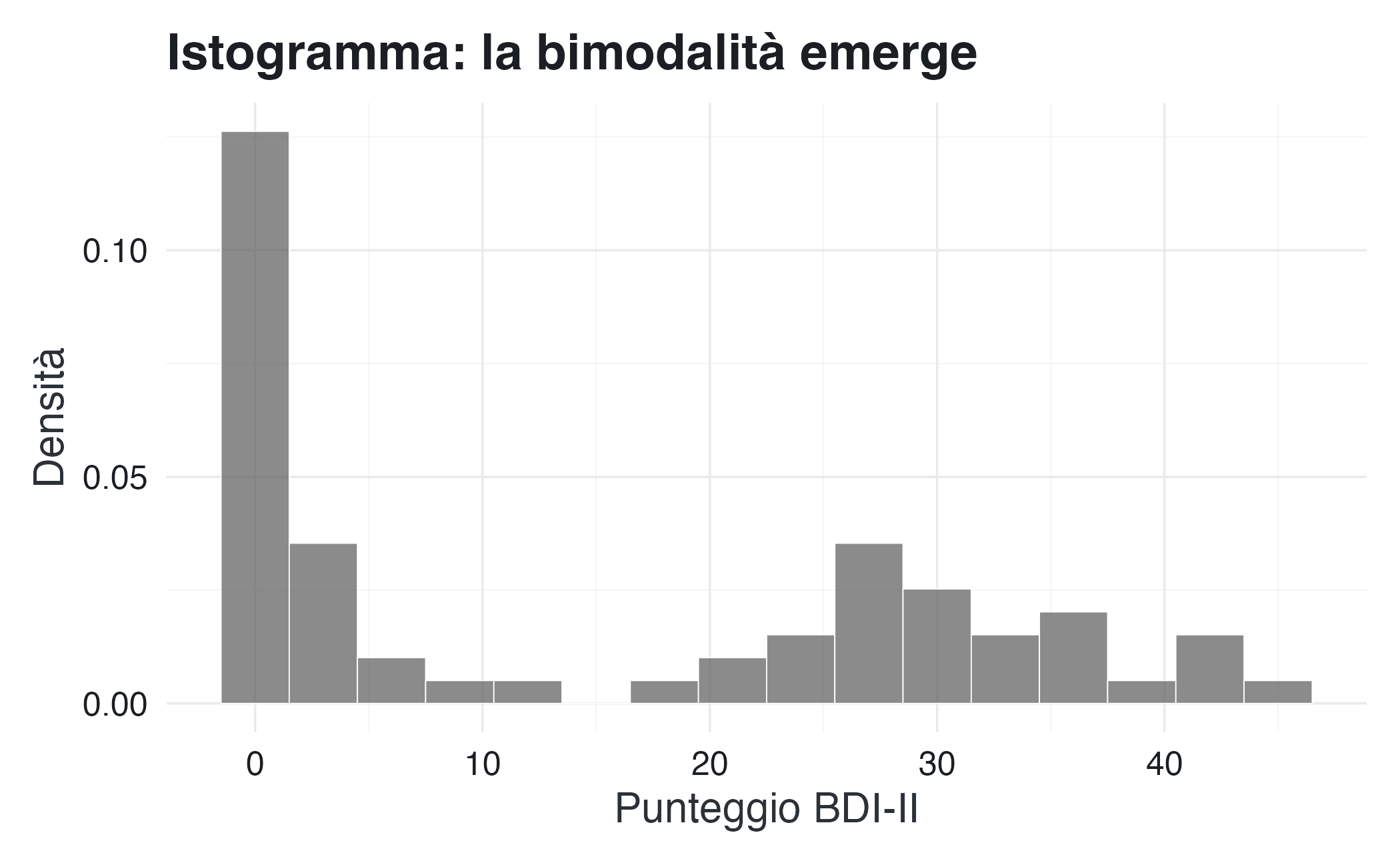
La scelta del “binwidth” è cruciale: bin troppo stretti producono istogrammi frastagliati in cui domina il rumore, mentre bin troppo larghi smussano eccessivamente, nascondendo i veri pattern. Qui utilizziamo bin di 3 unità, un compromesso che rivela la bimodalità senza introdurre artefatti.
16.3.6 Kernel Density Estimation: smussare senza perdere informazione
Gli istogrammi presentano un limite intrinseco: la loro forma dipende arbitrariamente dalla scelta dei bin. Modificare leggermente l’ampiezza o il punto di partenza può alterare sensibilmente l’aspetto del grafico. La stima della densità kernel (KDE) risolve questo problema costruendo una curva continua e smussata che non suddivide i dati in intervalli discreti.
L’idea alla base della KDE è elegante: invece di raggruppare i dati in intervalli discreti, posizioniamo una piccola curva gaussiana (o altro kernel) su ciascuna osservazione e sommiamo tutte queste curve. Il risultato è una funzione di densità continua che approssima la distribuzione sottostante.
Il parametro critico è il bandwidth, che controlla quanto “larghe” sono le curve gaussiane individuali. Un bandwidth piccolo produce una curva frastagliata che segue da vicino ogni singolo dato, mentre un bandwidth grande genera una curva molto liscia che rischia di nascondere i dettagli reali.
# Base plot
base_plot <- ggplot(df_dep, aes(x = bdi)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = 3, fill = "gray80", color = "white") +
labs(x = "BDI-II", y = "Densità")
# Bandwidth piccolo
base_plot +
geom_density(adjust = 0.5, linewidth = 1, color = "darkblue") +
labs(subtitle = "adjust = 0.5")
# Bandwidth standard
base_plot +
geom_density(adjust = 1, linewidth = 1, color = "darkgreen") +
labs(subtitle = "adjust = 1 (default)")
# Bandwidth grande
base_plot +
geom_density(adjust = 2, linewidth = 1, color = "darkred") +
labs(subtitle = "adjust = 2")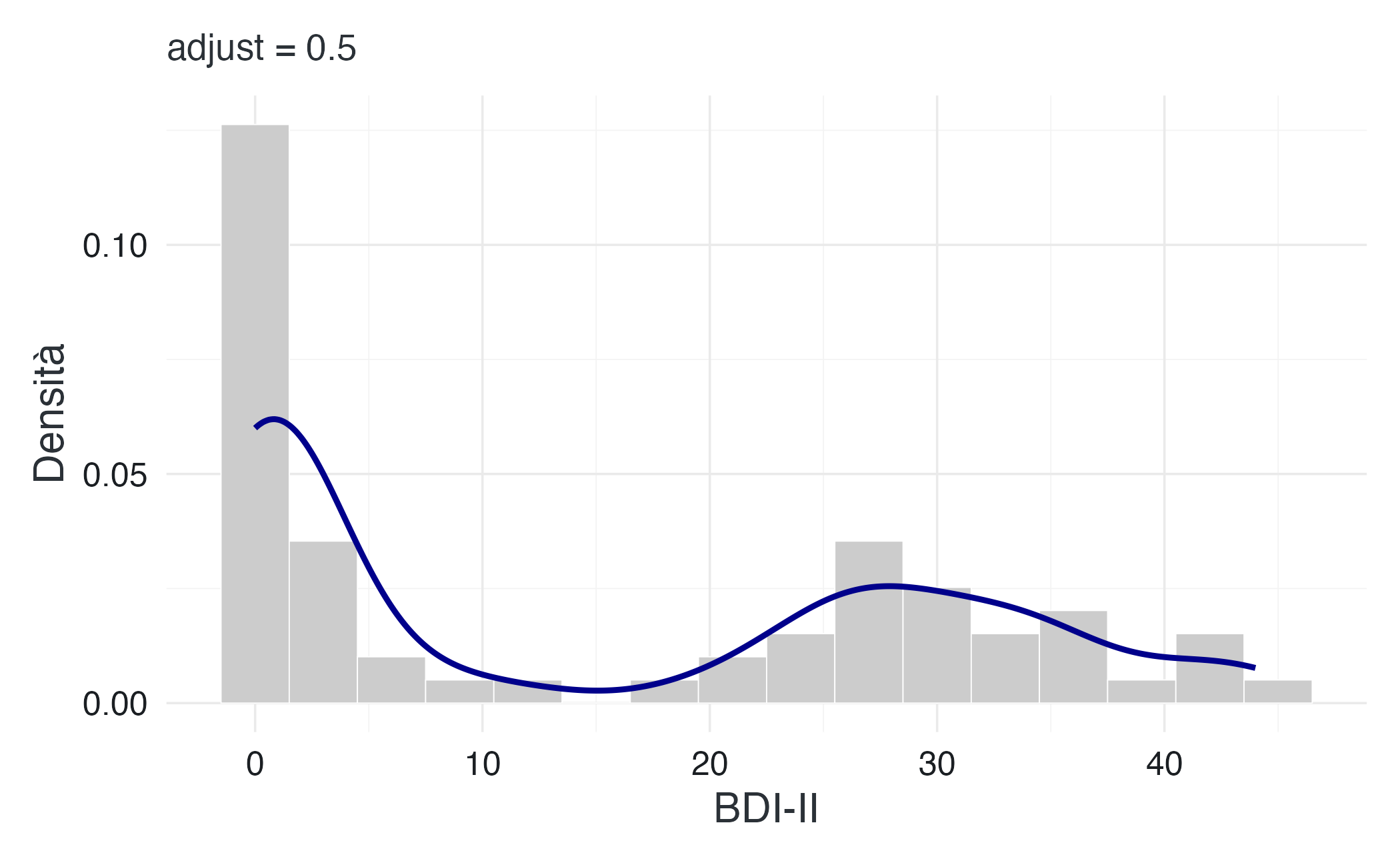
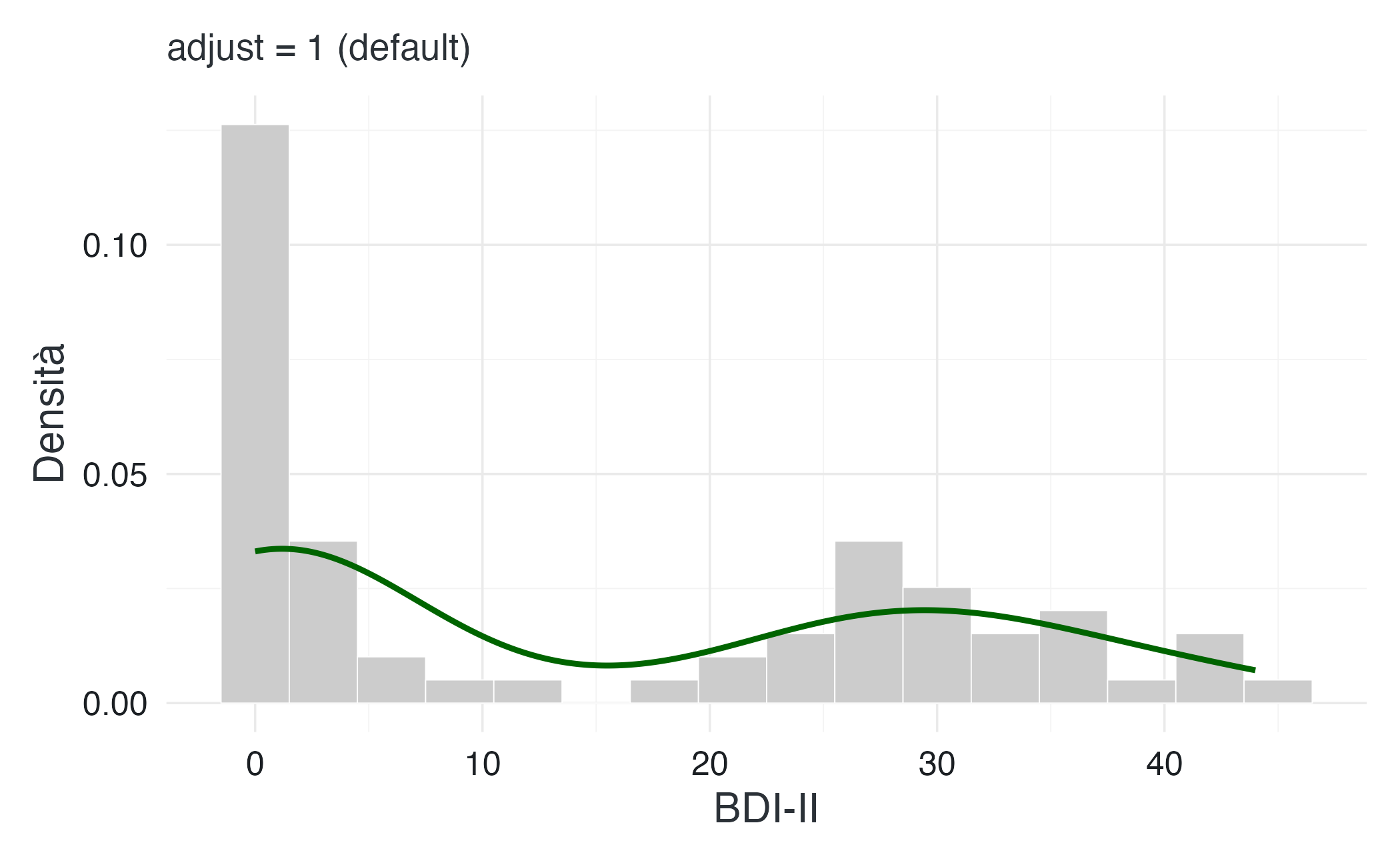
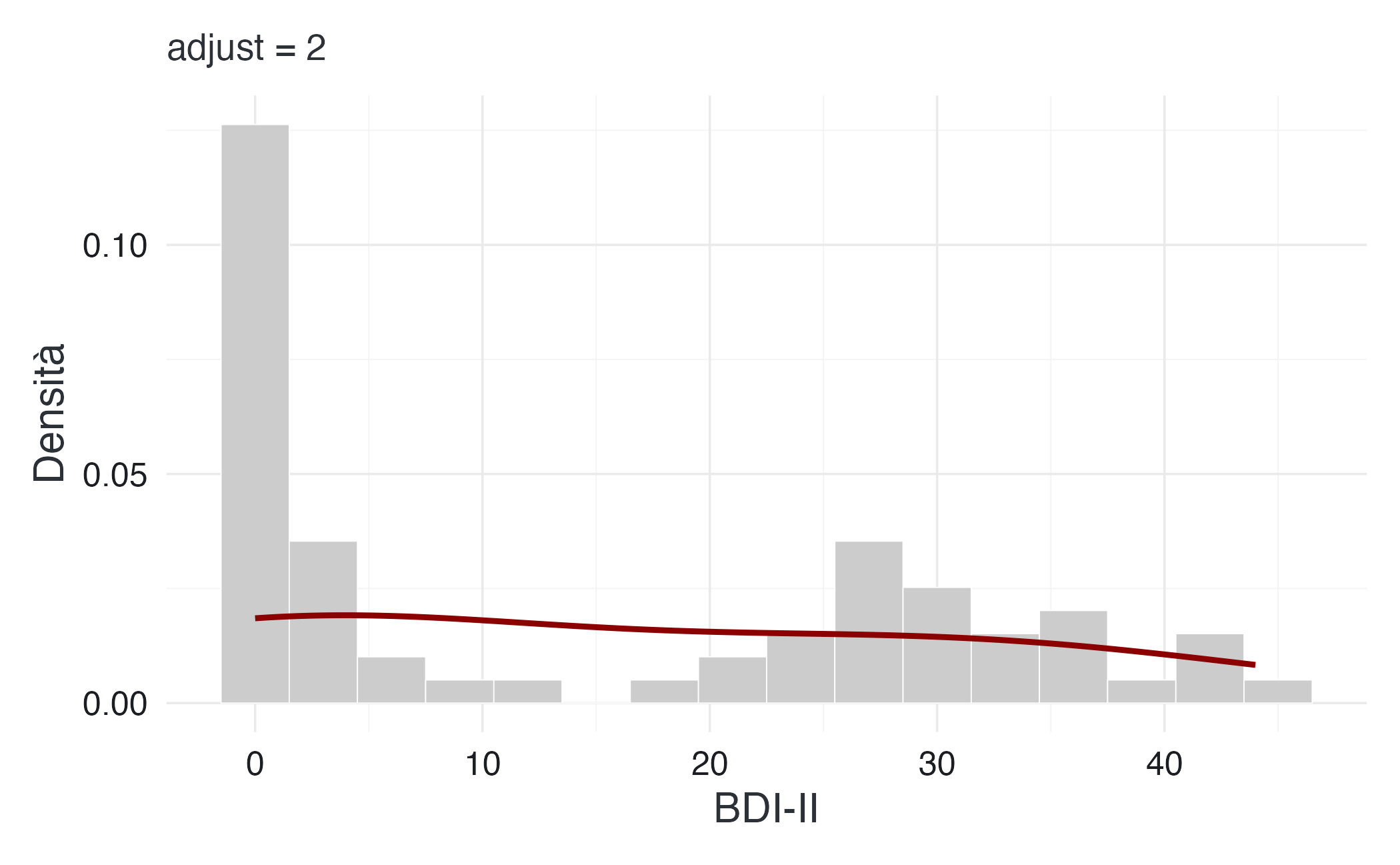
Confronto tra KDE con diversi bandwidth
Con adjust = 1 (impostazione predefinita), la curva rivela chiaramente la natura bimodale della distribuzione: un picco tra 0–15 (controlli) e uno tra 25–40 (pazienti). Questa bimodalità riflette la struttura del campione e sarebbe meno evidente con un bandwidth troppo grande.
16.3.7 Confrontare gruppi: sovrapposizioni rivelano differenze
Uno degli usi più potenti della KDE è il confronto delle distribuzioni tra gruppi. Possiamo sovrapporre le curve di densità dei controlli e dei pazienti per valutare quanto le distribuzioni si sovrappongano.
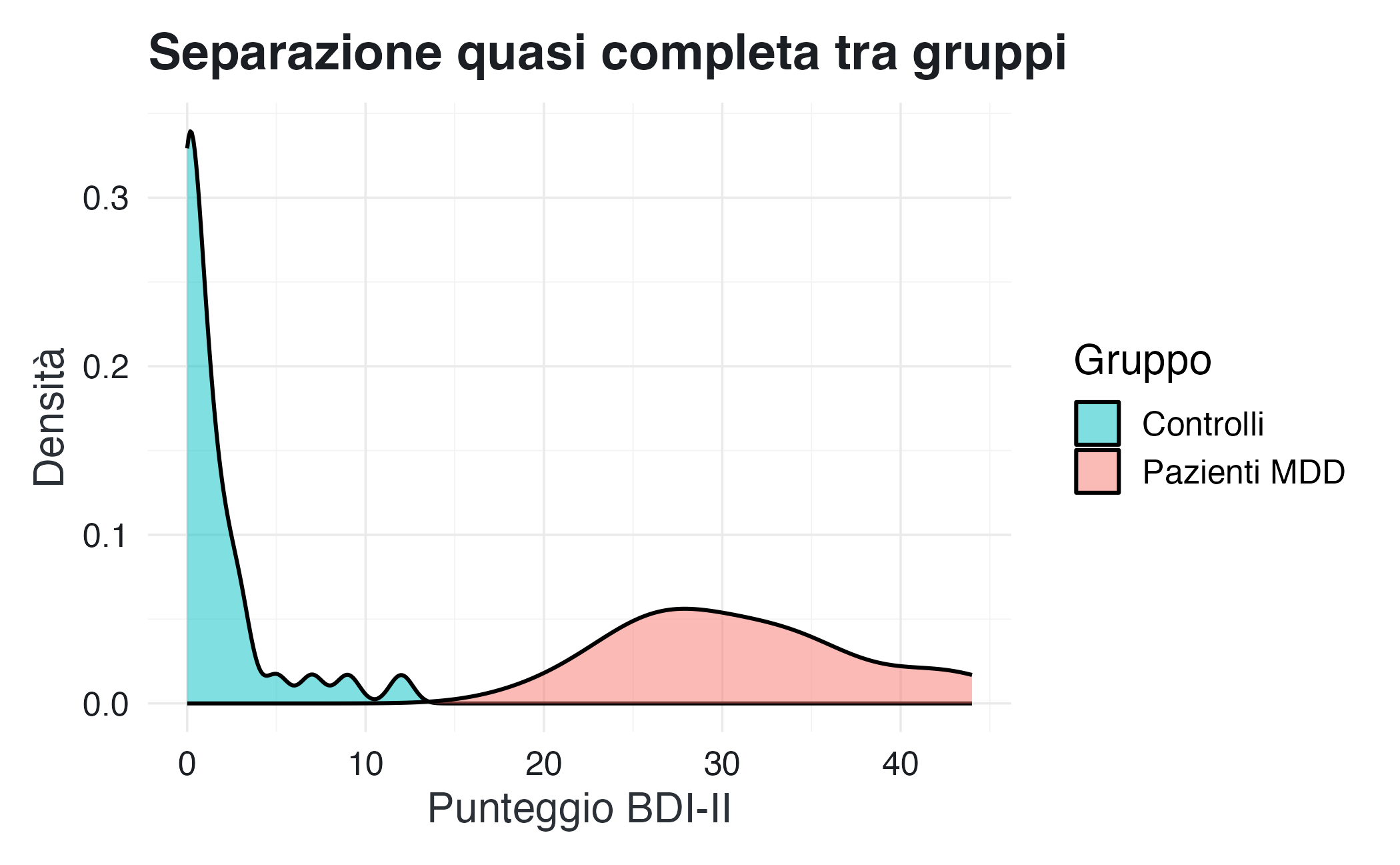
La sovrapposizione minima tra le due curve indica che il BDI-II discrimina efficacemente tra controlli sani e pazienti clinici in questo campione. Tuttavia, esiste una piccola zona di ambiguità intorno al punteggio 15-20, in cui i due gruppi tendono a sovrapporsi leggermente.
16.3.8 Quantili e boxplot: riassunti robusti
Mentre la media e la deviazione standard sono influenzate dai valori estremi, i quantili forniscono una sintesi robusta della distribuzione. I tre quartili (\(q_{0.25}\), \(q_{0.5}\), \(q_{0.75}\)) dividono i dati in quattro parti di uguale numerosità. Il secondo quartile è la mediana, che non viene influenzata dagli outlier come invece accade alla media.
Il boxplot (diagramma a scatola) visualizza questi quantili insieme ai valori estremi, fornendo un riassunto grafico compatto della distribuzione.
ggplot(df_dep, aes(x = group, y = bdi, fill = group)) +
geom_boxplot(alpha = 0.6, outlier.shape = 16) +
scale_fill_manual(
values = c("ctl" = "#00BFC4", "mdd" = "#F8766D"),
labels = c("Controlli", "Pazienti")
) +
scale_x_discrete(labels = c("Controlli", "Pazienti")) +
labs(
x = "Gruppo",
y = "Punteggio BDI-II",
title = "Mediane e dispersione a confronto"
) +
theme(legend.position = "none")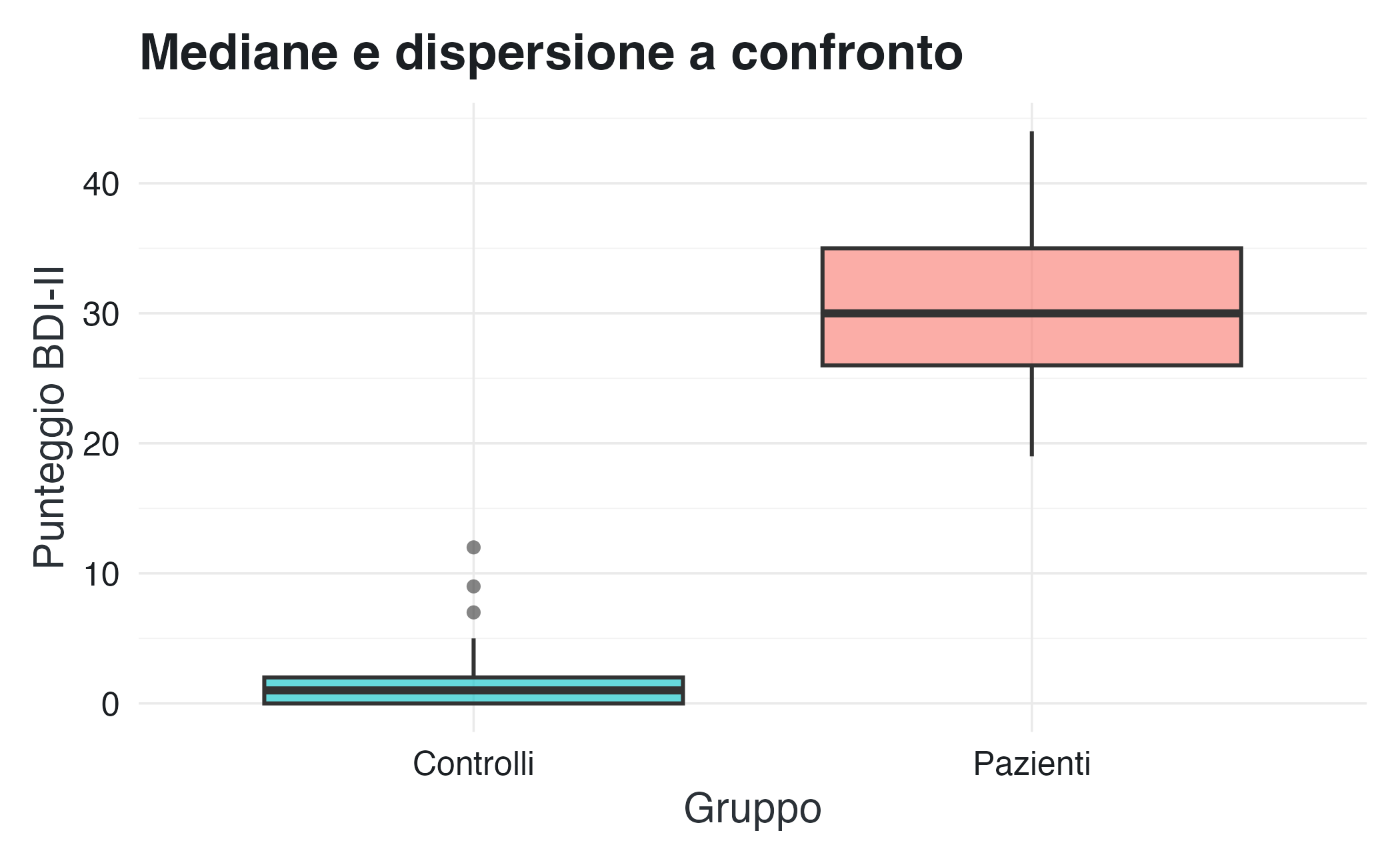
La scatola contiene il 50% centrale dei dati (da \(q_{0.25}\) a \(q_{0.75}\)) e una linea che indica la mediana. I “baffi” si estendono fino a 1.5 volte l’intervallo interquartile (IQR) e i punti oltre tale intervallo sono segnalati come potenziali outlier.
Questo grafico mostra che non c’è alcuna sovrapposizione tra i due gruppi: anche il terzo quartile dei controlli (circa 14) è inferiore al primo quartile dei pazienti (circa 23). Questa separazione netta riflette la validità discriminante dello strumento in un campione clinico ben definito.
16.3.9 Violin plot: boxplot + densità
I violin plot combinano le informazioni sintetiche del boxplot con la forma completa della distribuzione mostrata dalla KDE. Il risultato è una visualizzazione che conserva sia i riassunti robusti che i dettagli della distribuzione.
ggplot(df_dep, aes(x = group, y = bdi, fill = group)) +
geom_violin(alpha = 0.5, trim = FALSE) +
geom_boxplot(width = 0.15, alpha = 0.7, outlier.shape = NA) +
scale_fill_manual(
values = c("ctl" = "#00BFC4", "mdd" = "#F8766D"),
labels = c("Controlli", "Pazienti")
) +
scale_x_discrete(labels = c("Controlli", "Pazienti")) +
labs(
x = "Gruppo",
y = "Punteggio BDI-II",
title = "Forma completa + riassunto robusto"
) +
theme(legend.position = "none")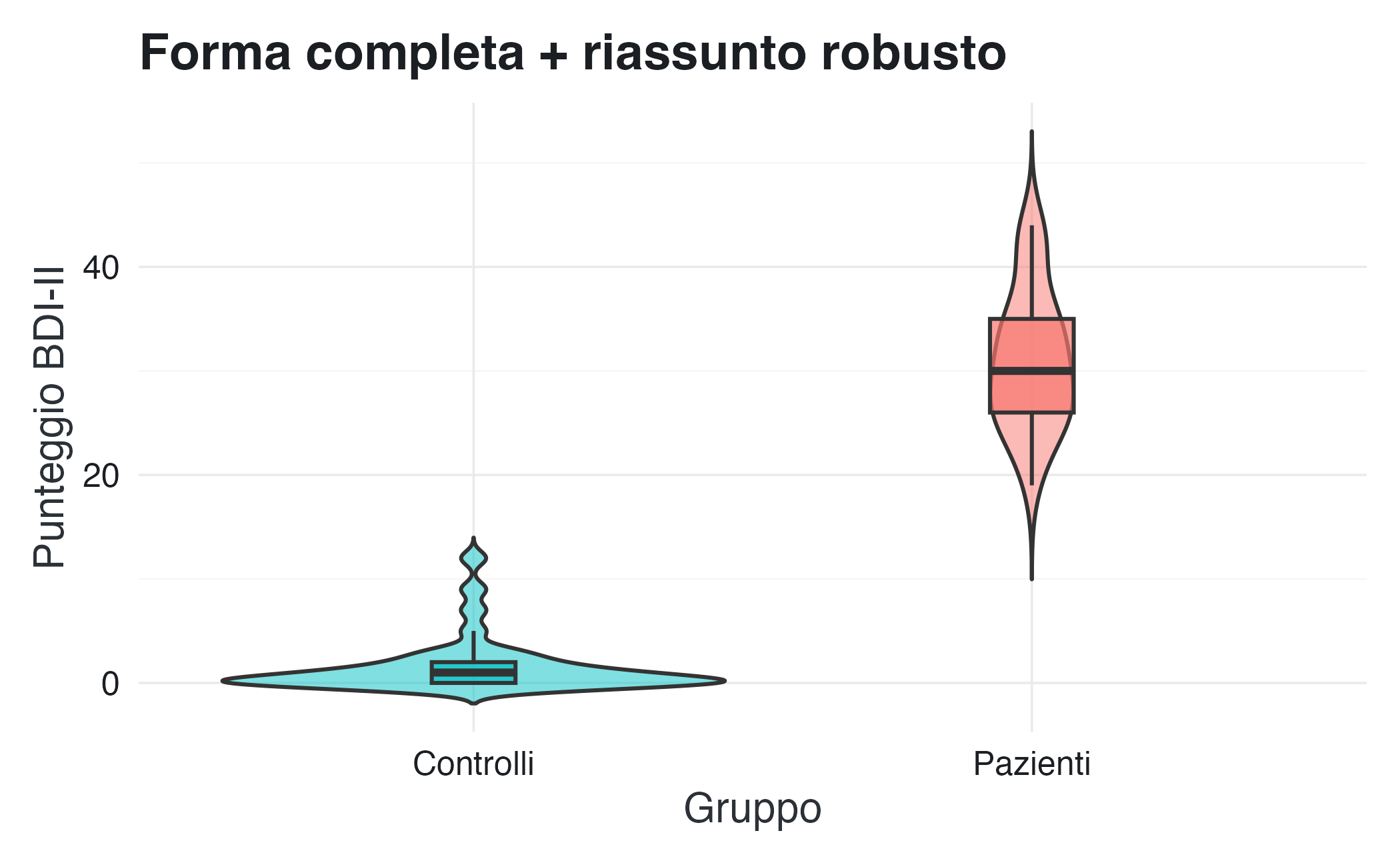
La “larghezza” del violino in ogni punto corrisponde alla densità dei dati a quell’altezza. Ciò rivela che i controlli si concentrano principalmente tra i valori 5 e 15, mentre i pazienti mostrano una distribuzione più dispersa tra i valori 20 e 40.
16.3.10 Beeswarm plot: ogni punto conta
Quando il campione non è troppo grande, può essere utile visualizzare ogni singola osservazione mantenendo la leggibilità. I beeswarm plot dispongono i punti evitando sovrapposizioni, creando pattern che riflettono la densità locale.
ggplot(df_dep, aes(x = group, y = bdi, color = group)) +
geom_beeswarm(cex = 2.5, alpha = 0.6) +
scale_color_manual(
values = c("ctl" = "#00BFC4", "mdd" = "#F8766D"),
labels = c("Controlli", "Pazienti")
) +
scale_x_discrete(labels = c("Controlli", "Pazienti")) +
labs(
x = "Gruppo",
y = "Punteggio BDI-II",
title = "Nessun punto nascosto"
) +
theme(legend.position = "none")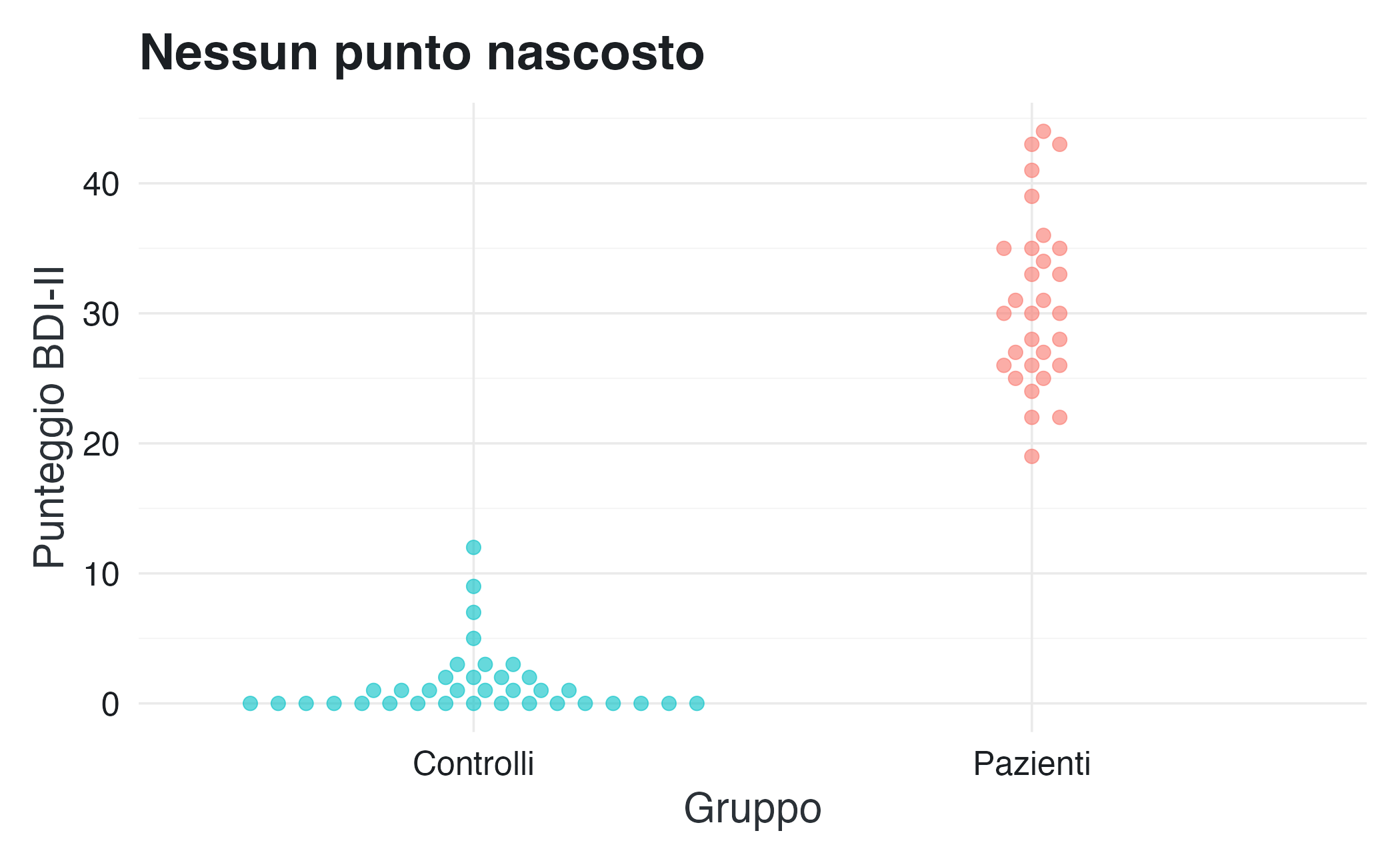
Questo grafico rende evidente che non ci sono outlier nascosti e che la separazione tra i gruppi è netta, anche se ci sono alcune osservazioni borderline che meriterebbero un approfondimento clinico.
16.4 Ponti tra categorie e numeri
Abbiamo esplorato le variabili categoriali e quelle numeriche come se fossero mondi separati, ma in realtà dialogano costantemente tra loro. Quando stratifichiamo una variabile numerica in base a delle categorie (come i punteggi BDI per gruppo clinico), costruiamo un ponte: utilizziamo strumenti per i dati numerici (come KDE e boxplot), ma organizziamo il confronto attraverso le categorie.
Allo stesso modo, quando si discretizza una variabile continua in classi (come abbiamo fatto con i cutoff del BDI), si traducono le quantità in categorie per semplificare la comunicazione. Ogni approccio ha i suoi meriti: le categorie facilitano la comprensione immediata, ma perdono informazioni; le quantità continue, invece, preservano i dettagli, ma richiedono una maggiore alfabetizzazione statistica.
Un’analisi esplorativa efficace utilizza entrambe le prospettive in modo complementare, scegliendo la rappresentazione più adatta alla domanda che stiamo ponendo.
Riflessioni conclusive
L’analisi univariata è il fondamento di ogni analisi più complessa. Prima di costruire modelli multivariati e di testare ipotesi formali, è necessario comprendere a fondo ciascuna variabile: come si distribuisce, dove si concentra, quanto varia e quali anomalie presenta. Tale conoscenza non emerge dall’applicazione meccanica di tecniche standardizzate, ma dalla scelta ragionata tra molti strumenti complementari.
Per le variabili categoriali, abbiamo visto come le tabelle di contingenza rivelino i pattern di associazione, come le proporzioni permettano di effettuare confronti tra gruppi di dimensioni diverse e come i grafici a barre e i mosaic plot traducano i numeri in una percezione visiva immediata.
Per le variabili numeriche, abbiamo esplorato il dilemma tra precisione e interpretabilità: le eCDF sono complete, ma poco intuitive; gli istogrammi dipendono dalla scelta dei bin; le KDE introducono assunzioni di smoothness. Abbiamo scoperto che i boxplot sacrificano i dettagli in favore della robustezza, mentre i violin plot tentano di preservare entrambi.
La competenza nell’analisi esplorativa non consiste nel ricordare quale grafico utilizzare in una determinata situazione, ma nello sviluppare un’intuizione su quale aspetto della distribuzione vogliamo evidenziare in un determinato momento. Vogliamo mostrare la forma completa o riassumere con indici robusti? Vogliamo confrontare i gruppi evidenziandone le sovrapposizioni o le separazioni? Vogliamo comunicare con chi ha familiarità con le distribuzioni o con un pubblico generico?
Queste domande non hanno risposte universali. L’analisi esplorativa è un dialogo iterativo con i dati, in cui si provano diverse rappresentazioni finché non emerge un’immagine coerente del fenomeno che si sta studiando. Solo allora saremo pronti per l’analisi inferenziale, ma questa è un’altra storia.
Esercizi
ImportanteEsercizio 1: Dataset penguins
Obiettivo: Esplorare relazioni tra variabili categoriali e numeriche nel dataset penguins.
Consegne:
Crea una tabella di contingenza tra
speciesesex. Calcola proporzioni di riga e colonna. Cosa ti dice il risultato sul rapporto tra generi nelle diverse specie?Costruisci un mosaic plot tra
islandesex. Le proporzioni di genere variano significativamente tra isole?-
Visualizza la distribuzione di
body_mass_g(massa corporea) con:- Un istogramma per l’intero campione
- Curve KDE sovrapposte per ciascuna specie
- Violin plot stratificati per specie e genere
Domanda di riflessione: La massa corporea mostra pattern chiari legati a specie e genere? Quali visualizzazioni sono più efficaci per comunicare questo risultato?
Suggerimento: Usa position = position_dodge() nei violin plot per affiancare maschi e femmine all’interno di ogni specie.
ImportanteEsercizio 2: SWLS e rete sociale
Contesto: Analizzerai dati sulla Satisfaction With Life Scale (SWLS) e sulla Lubben Social Network Scale (LSNS-6), che misura la qualità delle relazioni sociali distinguendo tra famiglia e amici.
Variabili:
-
swls: Punteggio totale soddisfazione di vita (5–35) -
lsns_total: Punteggio rete sociale totale (0–30) -
lsns_family: Sottoscala famiglia (0–15) -
lsns_friends: Sottoscala amici (0–15) -
gender: Genere (M,F) -
school_type: Tipo scuola superiore (liceo classico/scientifico vs. altri)
Consegne:
-
Esplorazione categoriale:
- Tabella di contingenza
gender×school_type - Grafico a barre della distribuzione di
school_type
- Tabella di contingenza
-
Esplorazione numerica:
- Istogrammi di
swls,lsns_total,lsns_family,lsns_friends - Per ciascuna variabile, calcola: media, mediana, \(q_{0.25}\), \(q_{0.75}\), min, max
- Costruisci eCDF per
swls
- Istogrammi di
-
Confronti stratificati:
- Boxplot di
swlsstratificato pergender - Violin plot di
lsns_totalstratificato perschool_type - KDE sovrapposte di
lsns_familyvs.lsns_friends(sulla stessa scala)
- Boxplot di
-
Domanda di ricerca: La soddisfazione di vita (
swls) è maggiore in chi ha punteggi elevati sulla rete sociale familiare o amicale? Usa visualizzazioni appropriate per investigare (Suggerimento: potresti categorizzarelsns_familyelsns_friendsin “basso”/“alto” rispetto alla mediana).
File: swls_lsns_students.csv
Punti chiave
In uno dei capitoli successivi esploreremo le relazioni bivariate, scoprendo come due variabili co-variano e quali pattern emergono dalla loro interazione.
Bibliografia
Zetsche, U., Buerkner, P.-C., & Renneberg, B. (2019). Future expectations in clinical depression: biased or realistic? Journal of Abnormal Psychology, 128(7), 678–688.