11 Visualizzazione dei dati con ggplot2
Introduzione
La visualizzazione è il cuore dell’analisi esplorativa dei dati. Prima di costruire modelli statistici complessi, è essenziale osservare i dati per scoprire pattern, identificare anomalie e formulare ipotesi. In questo capitolo imparerai a creare grafici efficaci utilizzando ggplot2, il sistema di visualizzazione più potente e flessibile di R.
- Grammatica coerente: ogni grafico si costruisce con gli stessi principi.
- Personalizzabile: controllo completo su ogni elemento visuale.
- Pubblicabile: qualità da rivista scientifica.
- Estensibile: centinaia di pacchetti aggiuntivi.
ggplot2 è lo standard de facto per la visualizzazione in psicologia e scienze sociali.
11.1 La filosofia: Grammar of Graphics
ggplot2 si fonda sul concetto di grammatica dei grafici (Wilkinson, 2005): un grafico è costruito come una composizione di strati (layers) che mappano i dati su attributi visivi.
11.1.1 Componenti essenziali
Ogni grafico realizzato con ggplot2 comprende tre componenti fondamentali:
-
Dati (
data): il dataset da rappresentare. -
Estetiche (
aes): la mappatura delle variabili sulle proprietà visive (posizione, colore, forma, ecc.). -
Geometrie (
geom_*): il tipo di elemento grafico utilizzato (punti, linee, barre, …).
Anatomia di un grafico:
ggplot(data = <DATI>) +
aes(x = <VARIABILE_X>, y = <VARIABILE_Y>) +
geom_<TIPO>()+ in ggplot2
In ggplot2 il simbolo + serve ad aggiungere strati al grafico; non si utilizza la pipe (|>). Si tratta di uno dei pochi contesti del tidyverse in cui la pipe non è applicabile.
# Corretto
ggplot(dati) + geom_point()
# Errato
ggplot(dati) |> geom_point() # NON funziona11.2 Setup e dati di esempio
Per gli esempi seguenti, useremo dataset psicologici realistici:
# Dataset 1: Studio sulla depressione
set.seed(123)
depression <- tibble(
id = 1:100,
gruppo = sample(c("Controllo", "Trattamento"), 100, replace = TRUE),
pre_bdi = rnorm(100, mean = 20, sd = 8),
post_bdi = pre_bdi - rnorm(100, mean = 5, sd = 4),
eta = sample(18:65, 100, replace = TRUE),
genere = sample(c("F", "M"), 100, replace = TRUE)
) |>
mutate(
post_bdi = pmax(0, post_bdi), # BDI non può essere negativo
cambiamento = pre_bdi - post_bdi
)
# Dataset 2: Tempi di reazione in compito Stroop
stroop <- tibble(
partecipante = rep(1:30, each = 40),
trial = rep(1:40, times = 30),
condizione = rep(c("Congruente", "Incongruente"), each = 20, times = 30),
rt = ifelse(condizione == "Congruente",
rnorm(1200, mean = 650, sd = 100),
rnorm(1200, mean = 750, sd = 120))
) |>
mutate(rt = pmax(300, rt)) # RT minimo realistico
head(depression)# A tibble: 6 × 7
id gruppo pre_bdi post_bdi eta genere cambiamento
<int> <chr> <dbl> <dbl> <int> <chr> <dbl>
1 1 Controllo 22.0 13.9 23 M 8.15
2 2 Controllo 19.8 11.7 33 M 8.08
3 3 Controllo 19.7 13.3 32 M 6.33
4 4 Trattamento 30.9 30.0 36 F 0.966
5 5 Controllo 18.2 13.7 20 M 4.52
6 6 Trattamento 32.1 28.3 63 M 3.88 head(stroop)# A tibble: 6 × 4
partecipante trial condizione rt
<int> <int> <chr> <dbl>
1 1 1 Congruente 346.
2 1 2 Congruente 546.
3 1 3 Congruente 675.
4 1 4 Congruente 657.
5 1 5 Congruente 502.
6 1 6 Congruente 813.11.3 Grafici univariati
11.3.1 Istogrammi: distribuzioni di variabili continue
L’istogramma è il primo grafico da creare per esplorare una variabile quantitativa.
ggplot(depression) +
aes(x = pre_bdi) +
geom_histogram()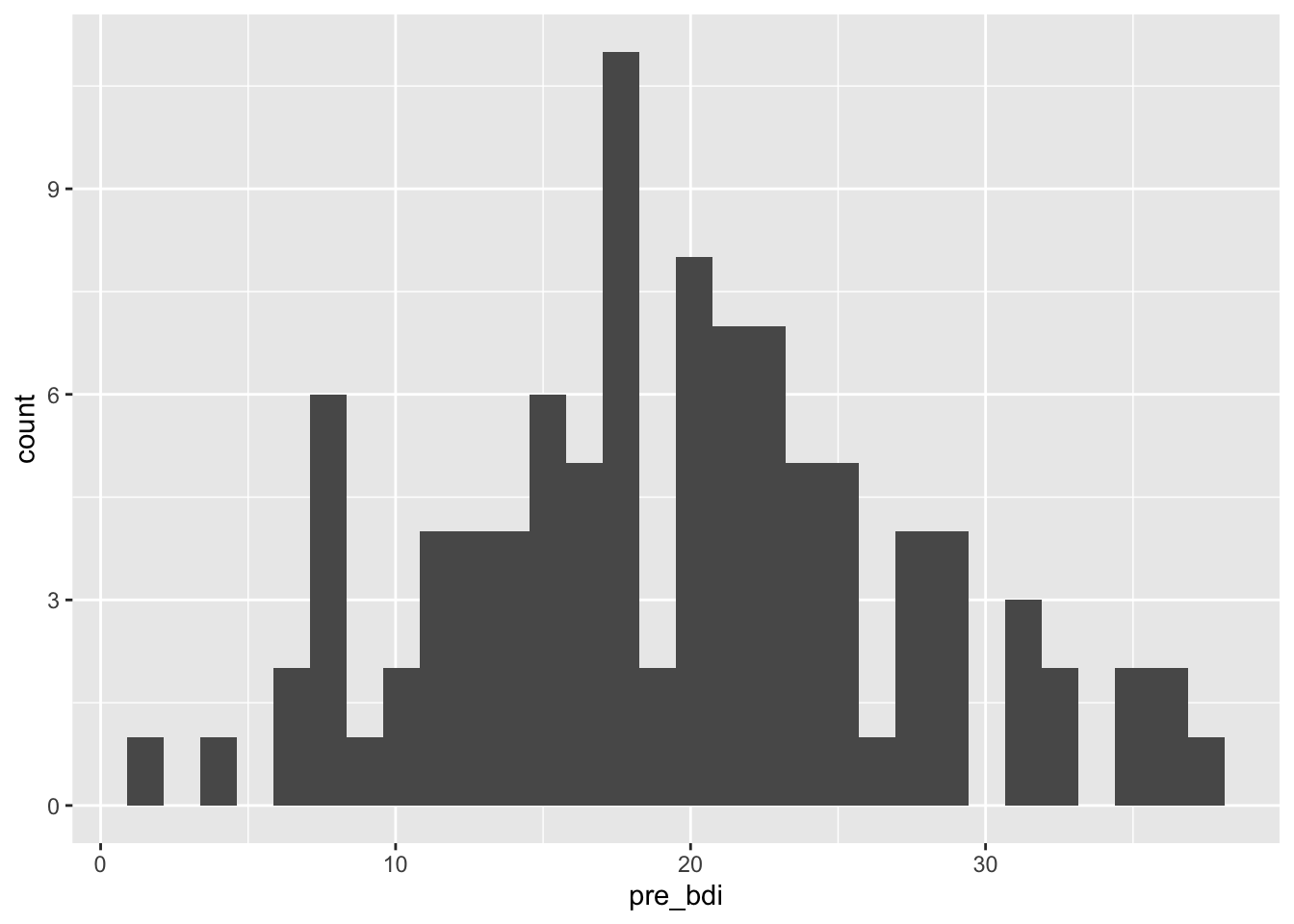
bins = 30”
Per impostazione predefinita, ggplot2 utilizza 30 bin (intervalli) per gli istogrammi. Questa scelta automatica è raramente ottimale. È buona pratica specificare esplicitamente il numero di bin (bins) oppure la loro ampiezza (binwidth):
geom_histogram(bins = 20) # Numero di bin
geom_histogram(binwidth = 2) # Ampiezza di ciascun binIstogramma migliorato:
ggplot(depression) +
aes(x = pre_bdi) +
geom_histogram(binwidth = 3, fill = "steelblue", color = "white") +
labs(
title = "Distribuzione dei punteggi BDI",
x = "Punteggio BDI (pre-trattamento)",
y = "Frequenza"
) +
theme_minimal()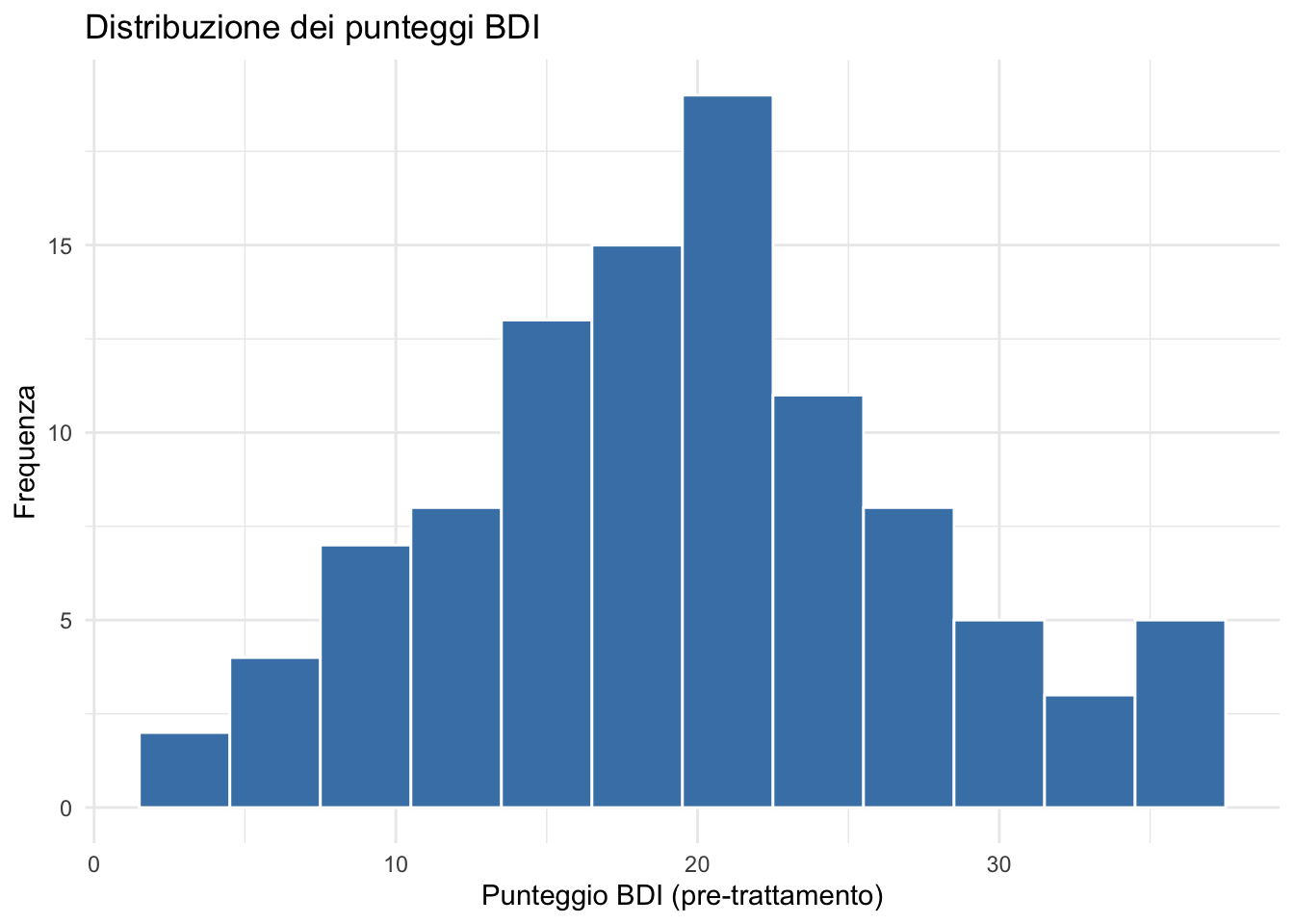
Elementi aggiunti:
-
binwidth = 3: bin da 3 unità BDI. -
fillecolor: colore riempimento e bordo. -
labs(): titoli degli assi. -
theme_minimal(): tema pulito.
11.3.2 Grafici di densità: un’alternativa agli istogrammi
I grafici di densità forniscono una stima lisciata della distribuzione di una variabile continua e sono particolarmente utili per il confronto visivo tra gruppi.
ggplot(depression) +
aes(x = pre_bdi, fill = gruppo) +
geom_density(alpha = 0.5) +
labs(
title = "Confronto delle distribuzioni BDI tra gruppi",
x = "Punteggio BDI",
y = "Densità",
fill = "Gruppo"
) +
theme_minimal()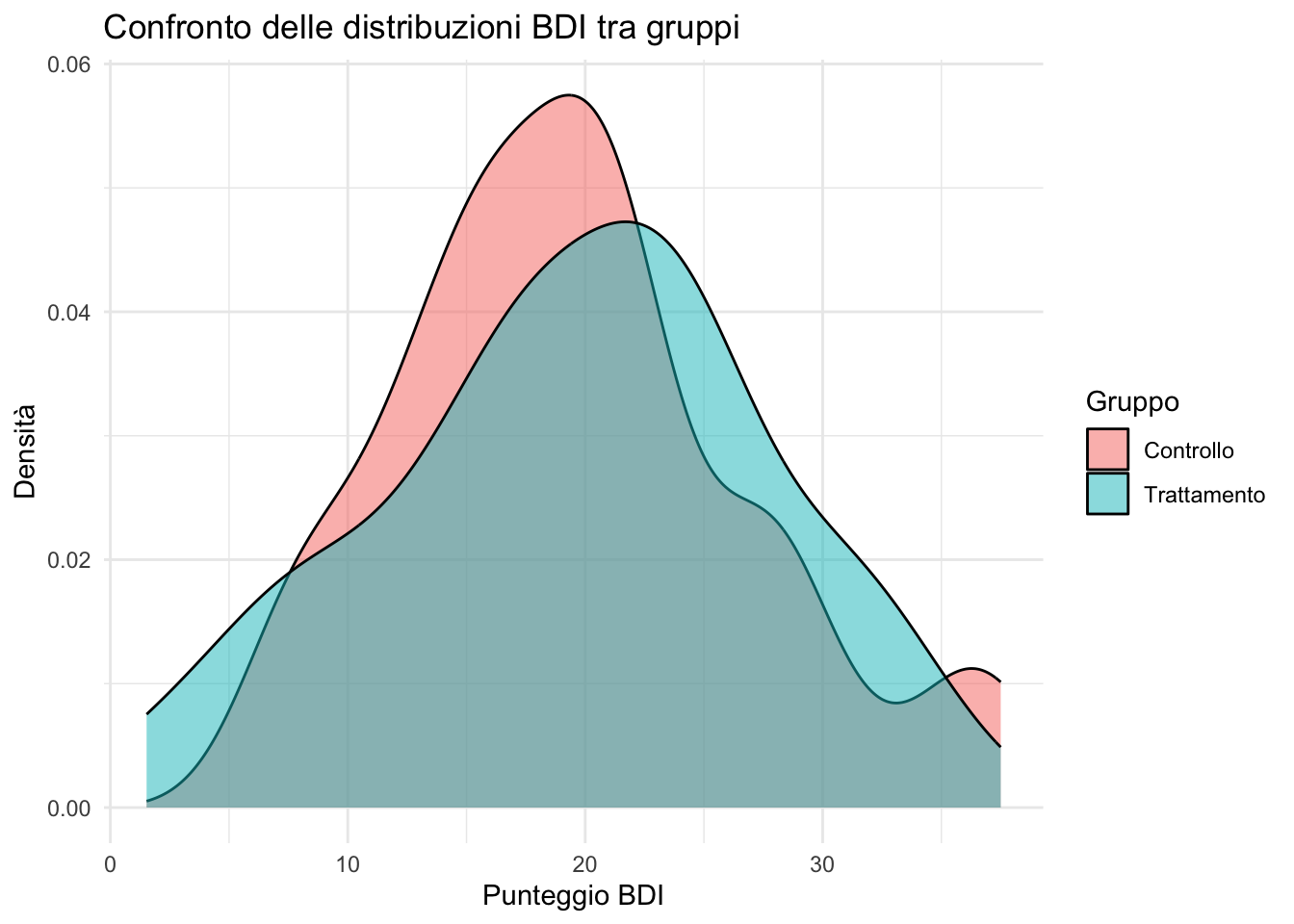
Nota: l’argomento alpha = 0.5 introduce trasparenza, facilitando l’osservazione delle sovrapposizioni tra distribuzioni.
11.3.3 Boxplot: sintesi dei cinque numeri
I boxplot offrono una rappresentazione compatta di posizione, dispersione e valori estremi.
ggplot(depression) +
aes(x = gruppo, y = cambiamento, fill = gruppo) +
geom_boxplot() +
labs(
title = "Cambiamento nei punteggi BDI",
x = "Gruppo",
y = "Riduzione BDI (punti)",
fill = "Gruppo"
) +
theme_minimal()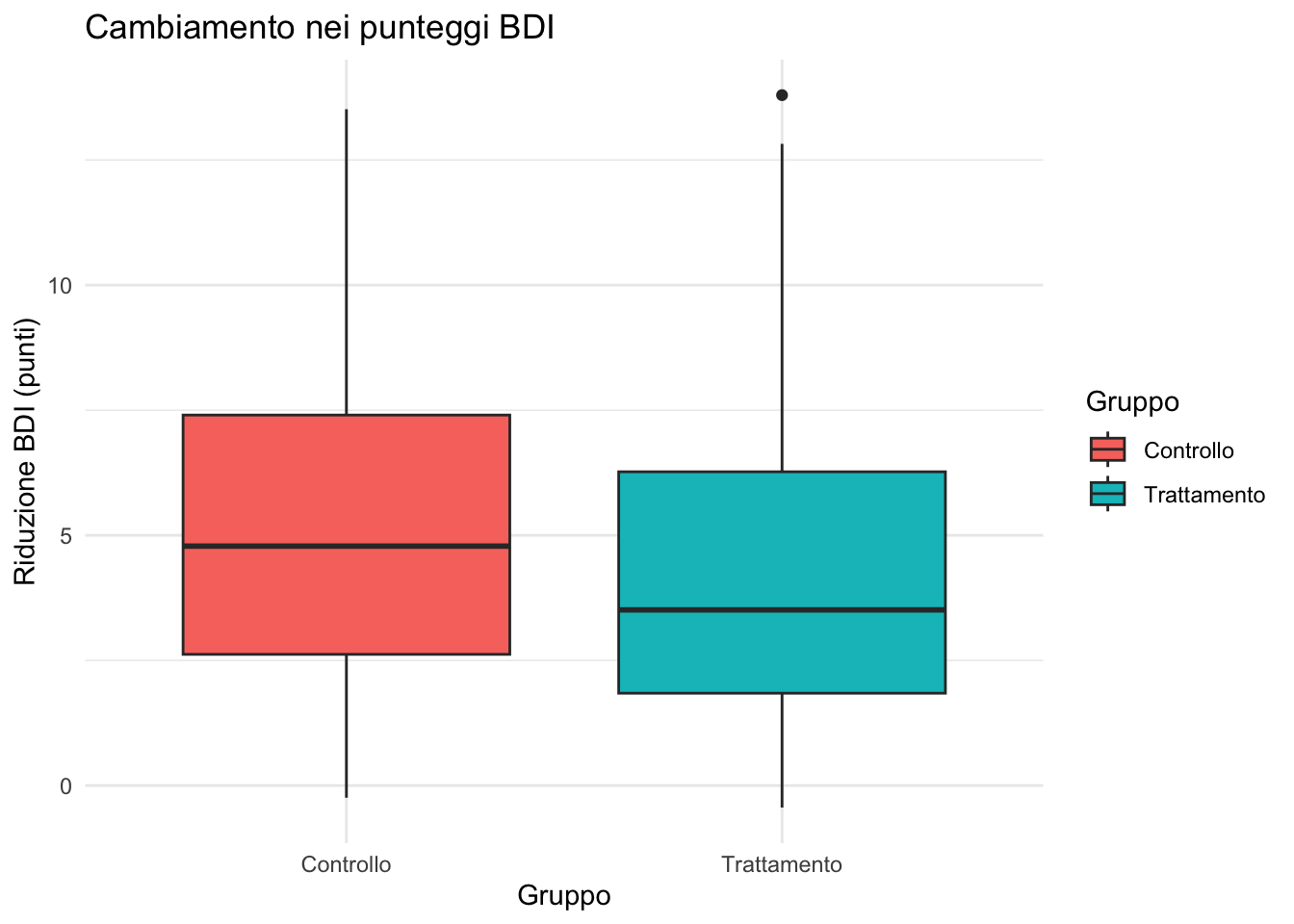
Interpretazione:
- box: intervallo interquartile (IQR, 50% centrale dei dati);
- linea nel box: mediana;
- baffi: estensione fino a 1.5 × IQR;
- punti isolati: potenziali outlier.
11.3.4 Violin plot: boxplot + densità
I violin plot combinano la sintesi del boxplot con la forma completa della distribuzione.
ggplot(depression) +
aes(x = gruppo, y = cambiamento, fill = gruppo) +
geom_violin(alpha = 0.5) +
geom_boxplot(width = 0.2, alpha = 0.7) +
labs(
title = "Distribuzione completa dei cambiamenti",
x = "Gruppo",
y = "Riduzione BDI"
) +
theme_minimal()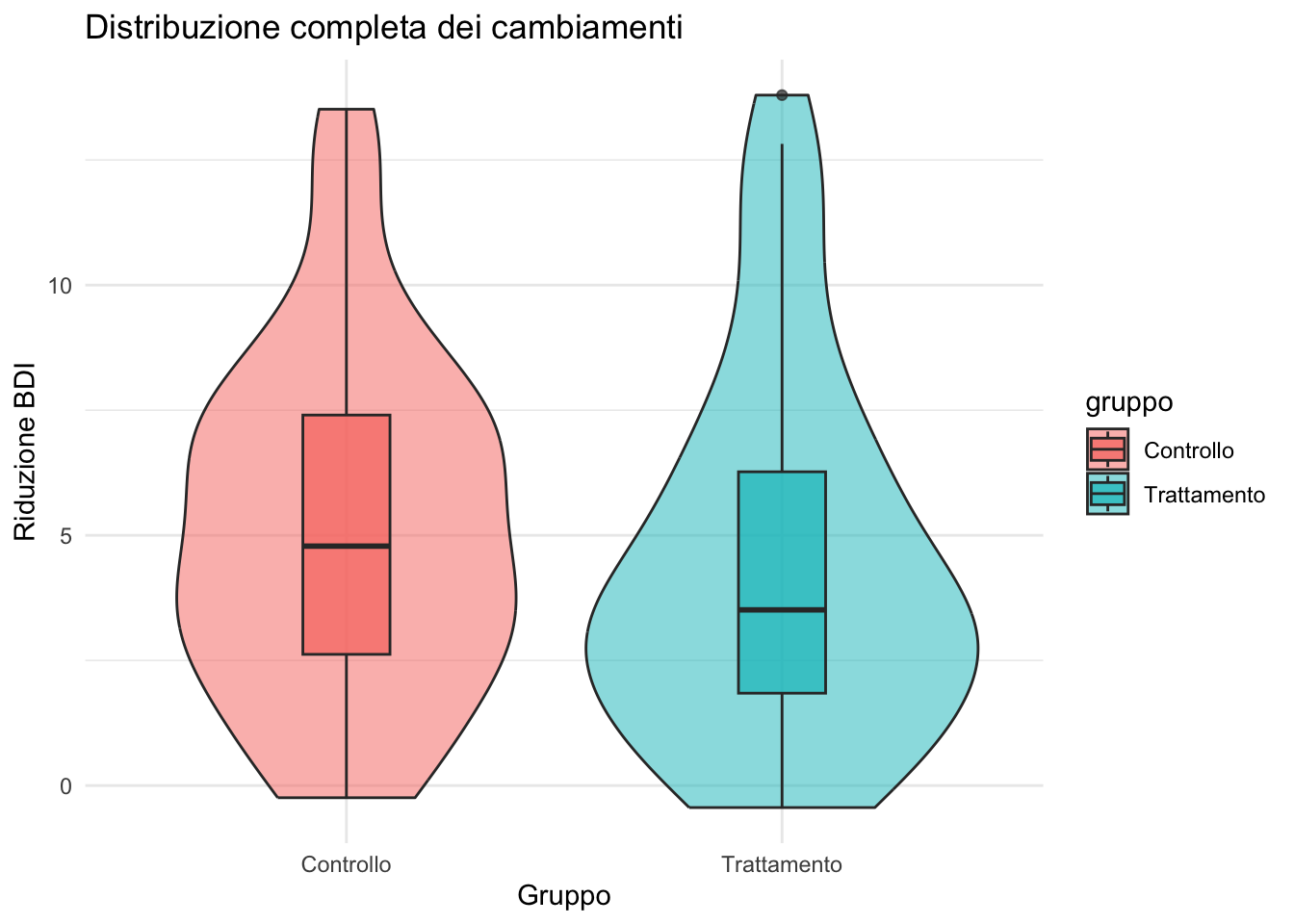
- Istogramma: variabile singola, interesse per la forma dettagliata.
- Densità: confronto di distribuzioni tra gruppi.
- Boxplot: sintesi rapida, molti gruppi.
- Violin plot: informazione completa sulla distribuzione per gruppo.
11.4 Grafici bivariati
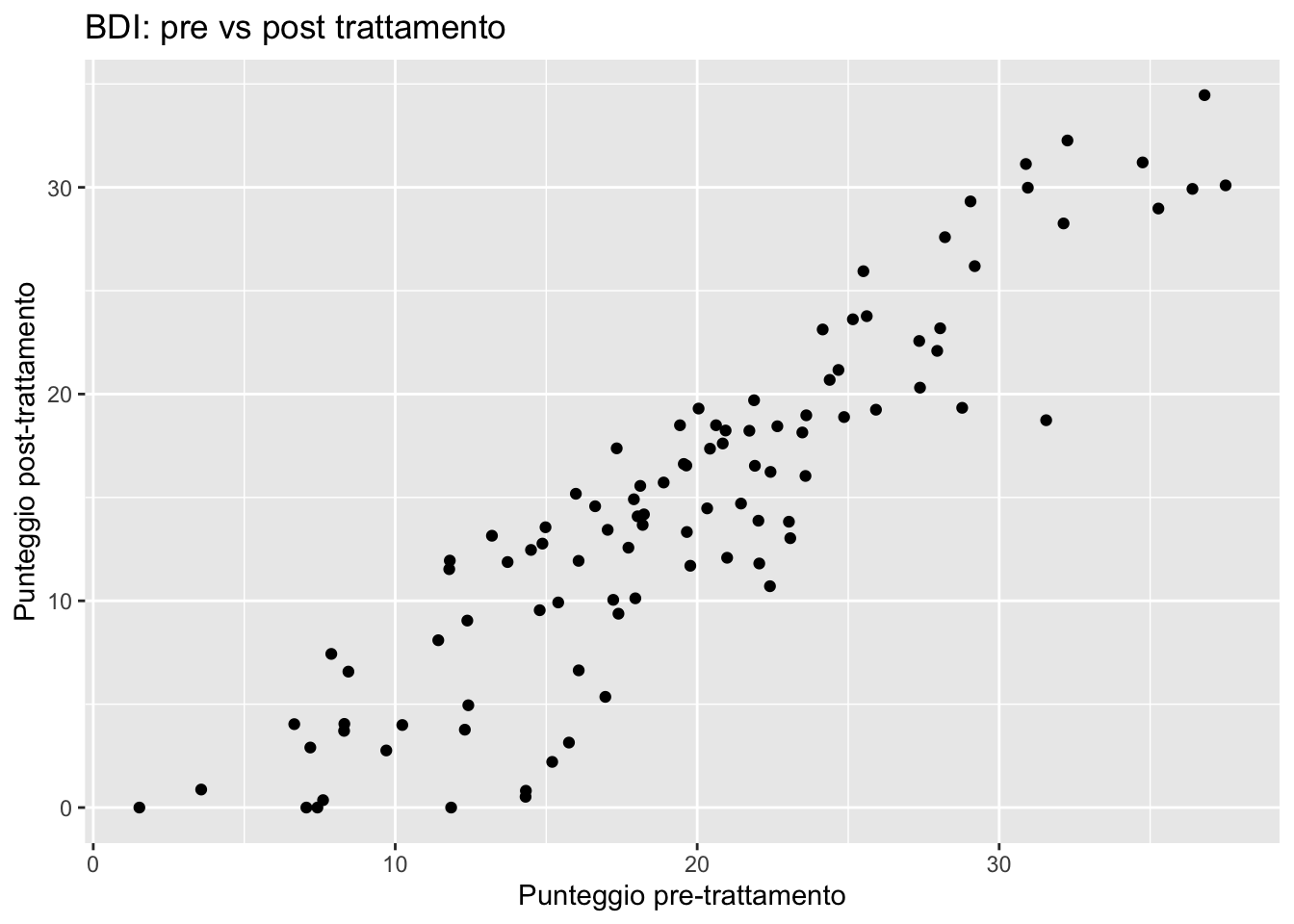
11.4.1 Scatterplot: relazioni tra variabili continue
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi) +
geom_point() +
labs(
title = "BDI: pre vs post trattamento",
x = "Punteggio pre-trattamento",
y = "Punteggio post-trattamento"
) 
11.4.1.1 Aggiungere una linea di tendenza
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", se = TRUE, color = "red") +
labs(
title = "Relazione BDI pre–post",
x = "Pre-trattamento",
y = "Post-trattamento"
) 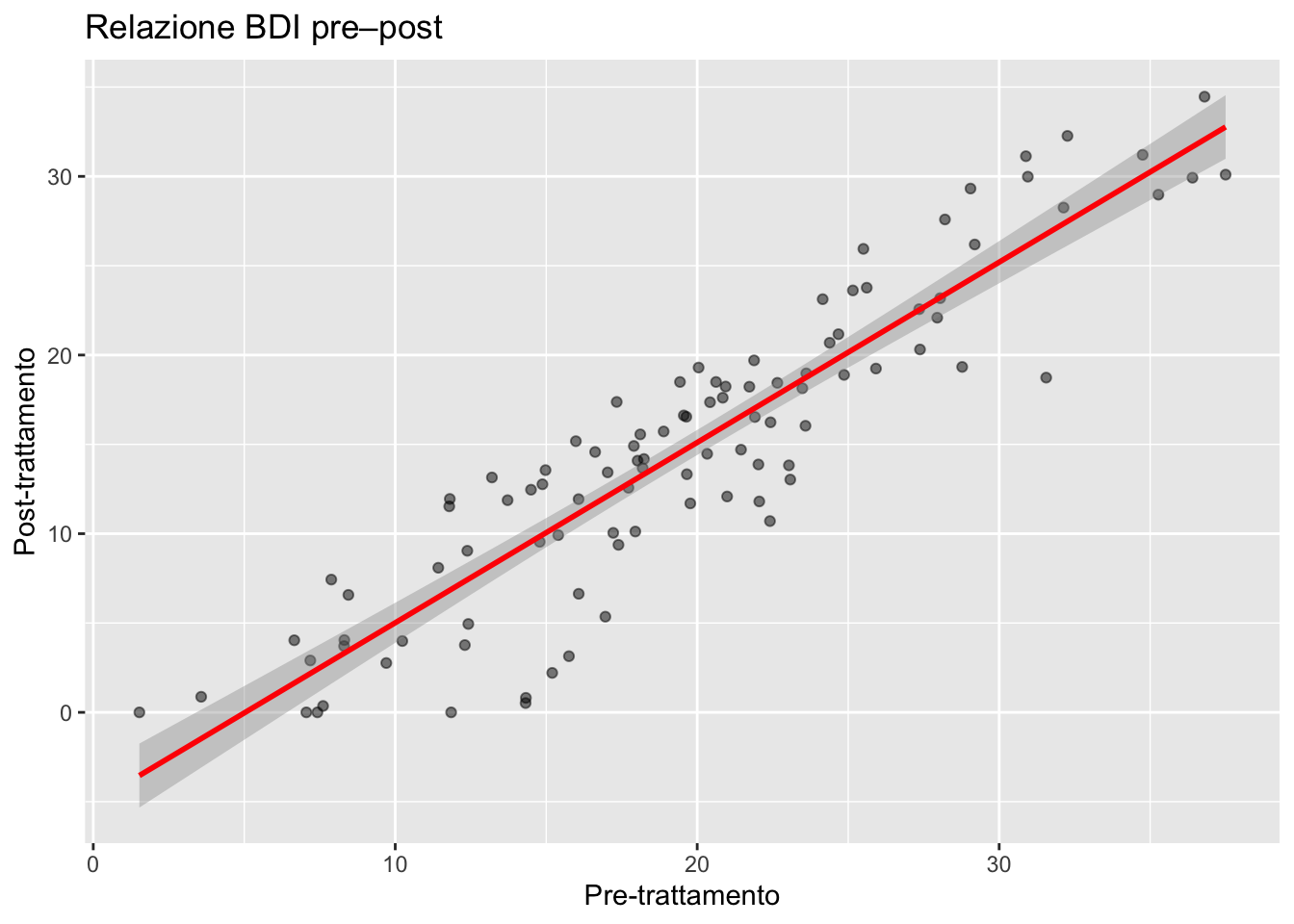
Elementi chiave:
-
geom_smooth(): aggiunge una linea di tendenza -
method = "lm": regressione lineare -
se = TRUE: banda di confidenza
11.4.2 Colorare per gruppo
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi, color = gruppo) +
geom_point(size = 2, alpha = 0.6) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "Relazione BDI per gruppo",
x = "Pre-trattamento",
y = "Post-trattamento",
color = "Gruppo"
) 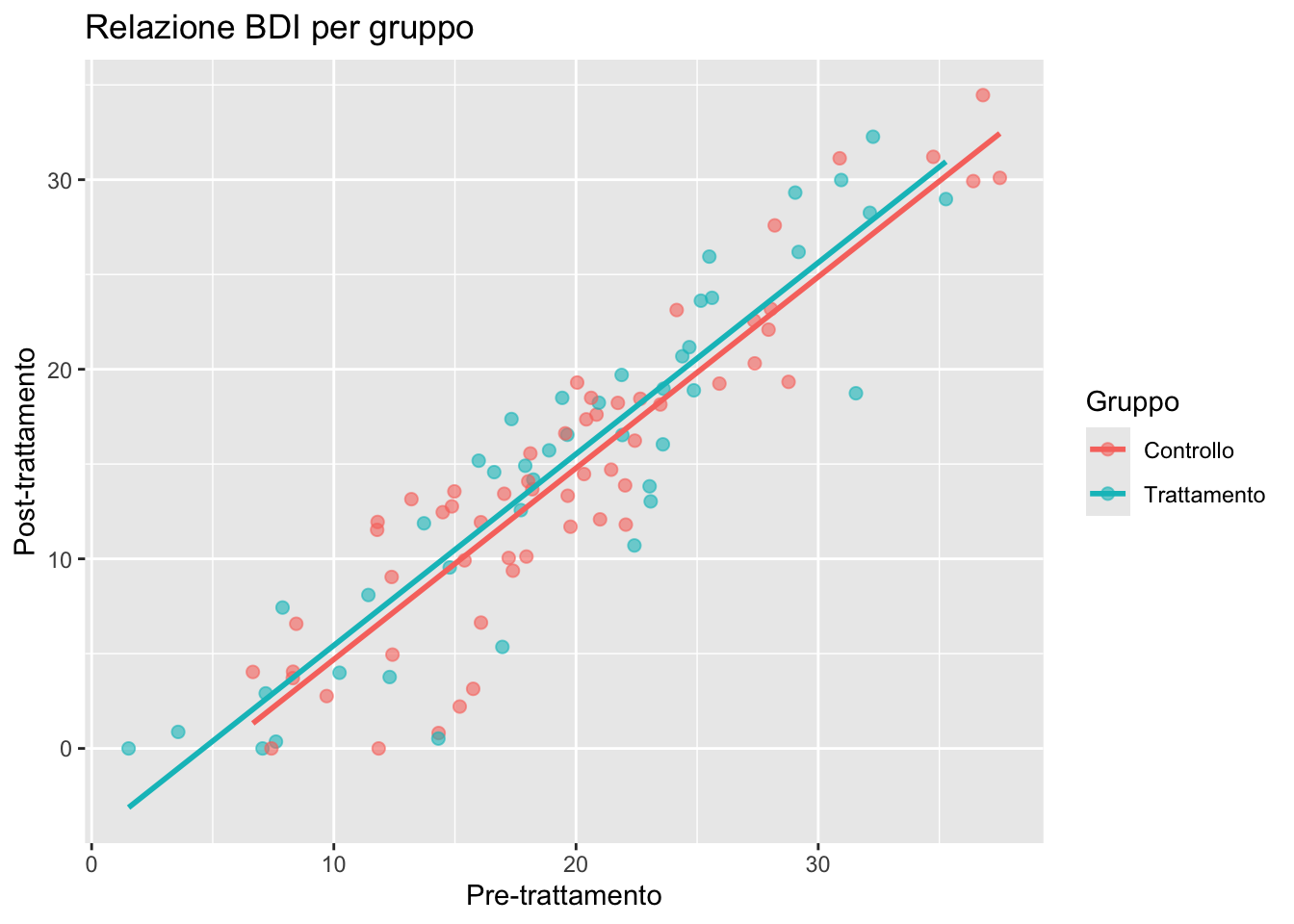
Nota: mappando color = gruppo all’interno di aes(), ggplot2 genera automaticamente colori distinti, legenda e linee di tendenza separate.
11.4.3 Grafici a barre: medie per gruppo
I grafici a barre sono appropriati solo per statistiche riassuntive già calcolate.
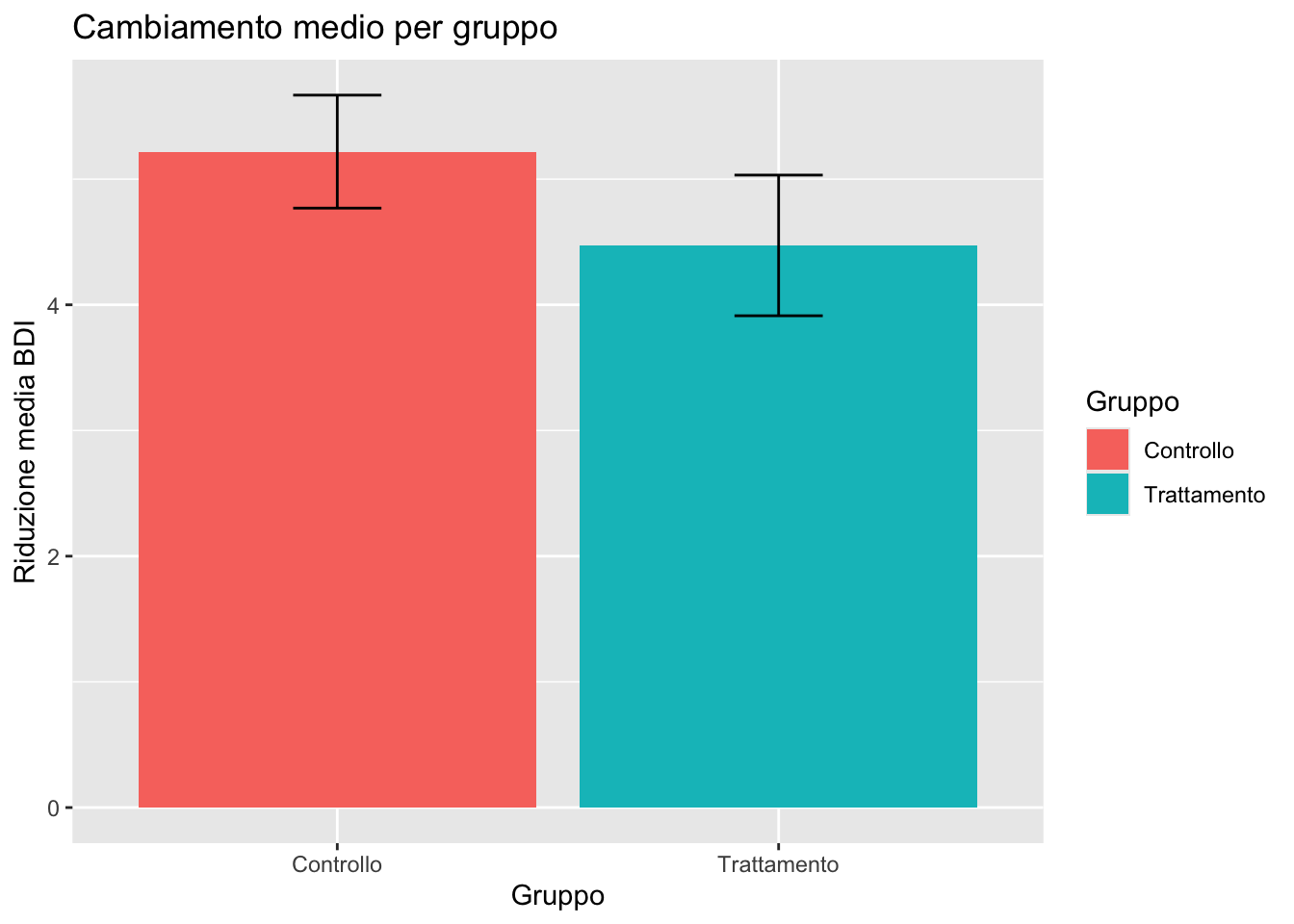
-
geom_bar(): calcola automaticamente le frequenze -
geom_col(): utilizza valori y forniti esplicitamente
Per medie o somme già calcolate, usa sempre geom_col().
11.5 Estetiche (aesthetics)
Le estetiche mappano le variabili del dataset su proprietà visive del grafico.
11.5.1 Estetiche principali
| Estetica | Tipo variabile | Funzione |
|---|---|---|
x, y
|
Continua / discreta | Posizione |
color |
Qualsiasi | Colore del bordo |
fill |
Qualsiasi | Colore di riempimento |
size |
Continua | Dimensione |
alpha |
Continua | Trasparenza |
shape |
Discreta | Forma |
linetype |
Discreta | Tipo di linea |
11.5.2 Mappare vs. impostare
Distinzione fondamentale:
# Mappare: la proprietà varia con i dati
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi, color = gruppo) +
geom_point()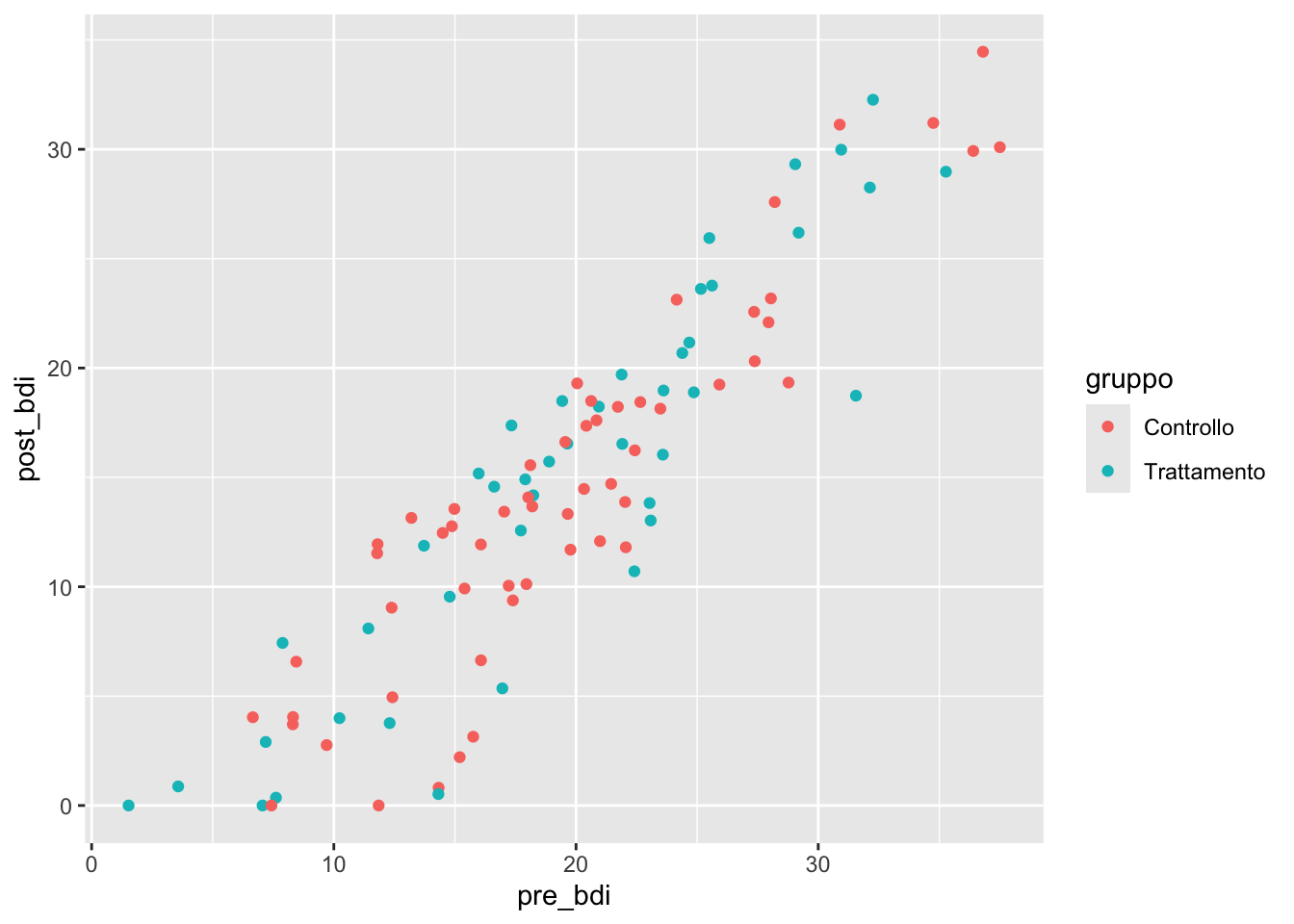
# Impostare: valore fisso
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi) +
geom_point(color = "red")
Regola d’oro:
11.5.3 Esempio con più estetiche
ggplot(depression) +
aes(
x = pre_bdi,
y = post_bdi,
color = gruppo,
size = eta,
shape = genere
) +
geom_point(alpha = 0.6) +
labs(
title = "Analisi multivariata dei punteggi BDI",
x = "Pre-trattamento",
y = "Post-trattamento",
color = "Gruppo",
size = "Età",
shape = "Genere"
) 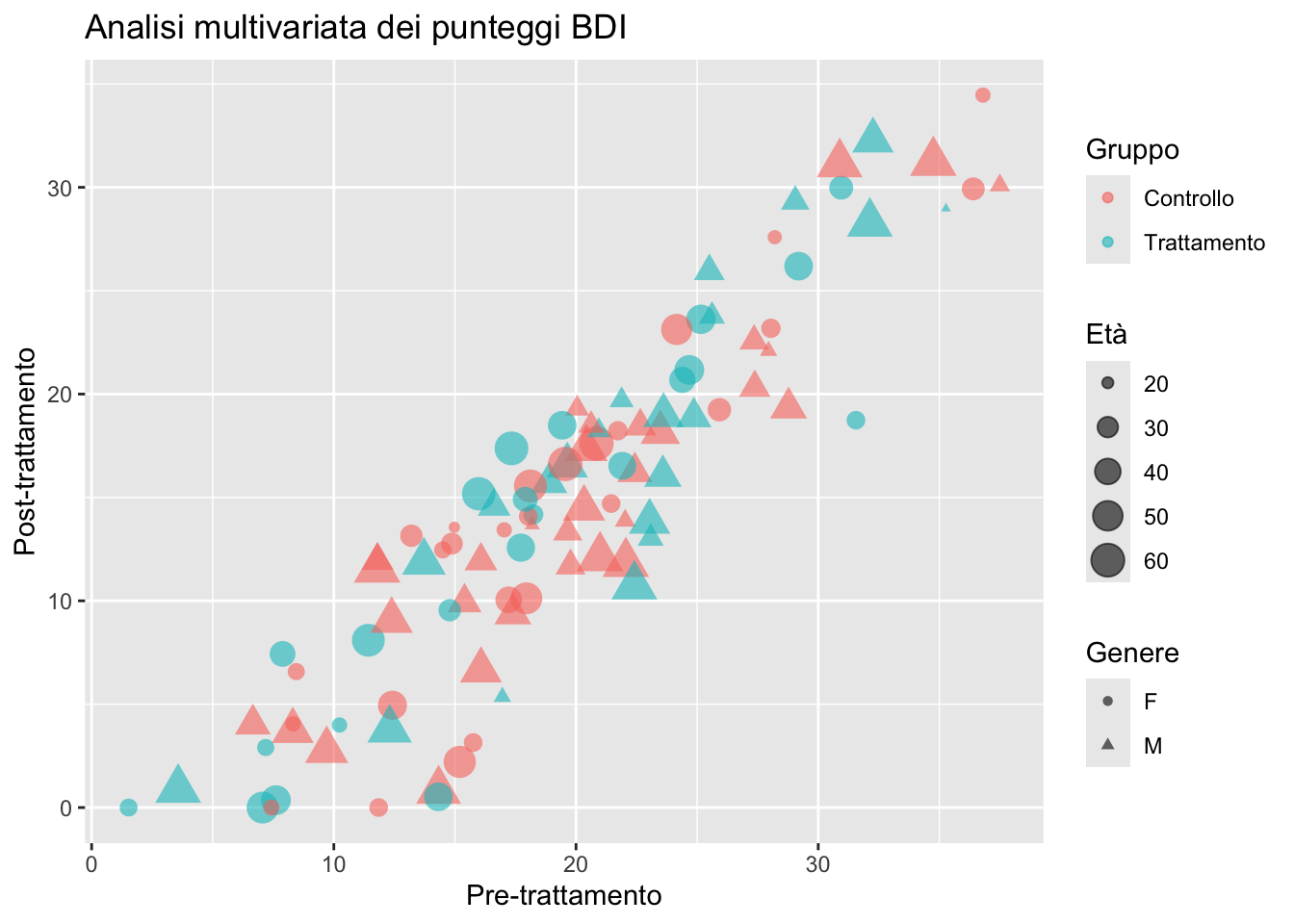
L’uso eccessivo di estetiche compromette la leggibilità. Limite pratico: 2–3 estetiche mappate simultaneamente.
11.6 Faceting: grafici multipli
Il faceting suddivide i dati in sottoinsiemi e genera un pannello grafico per ciascuno. È particolarmente utile per confronti sistematici tra gruppi.
11.6.1 facet_wrap(): griglia flessibile
ggplot(depression) +
aes(x = pre_bdi) +
geom_histogram(binwidth = 3, fill = "steelblue", color = "white") +
facet_wrap(~ gruppo + genere, ncol = 2) +
labs(
title = "Distribuzione BDI stratificata",
x = "Punteggio BDI",
y = "Frequenza"
) 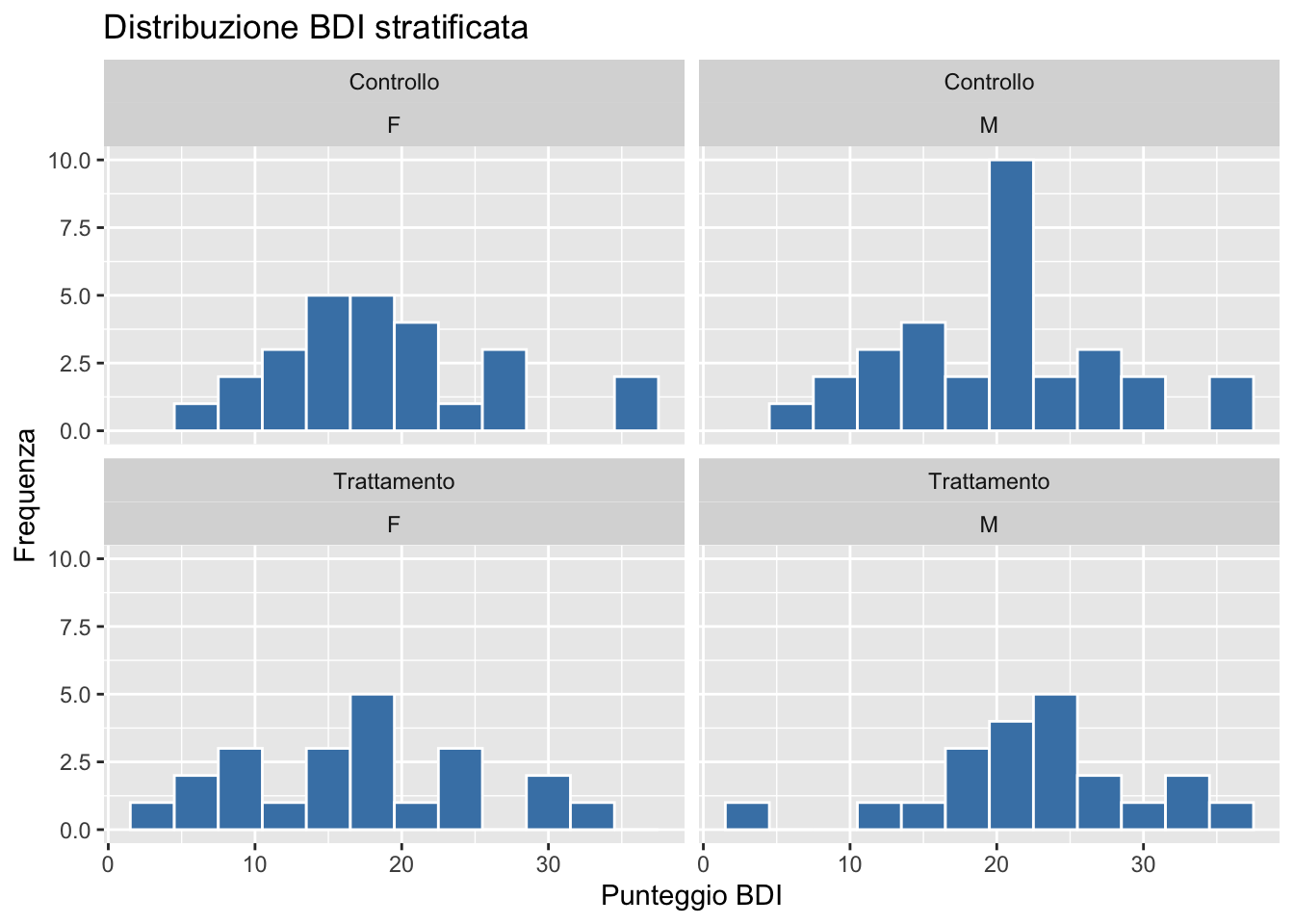
Sintassi: facet_wrap(~ variabile) oppure facet_wrap(~ var1 + var2)
11.6.2 facet_grid(): griglia strutturata
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", se = FALSE) +
facet_grid(genere ~ gruppo) +
labs(
title = "Relazione pre-post per genere e gruppo",
x = "Pre-trattamento",
y = "Post-trattamento"
) 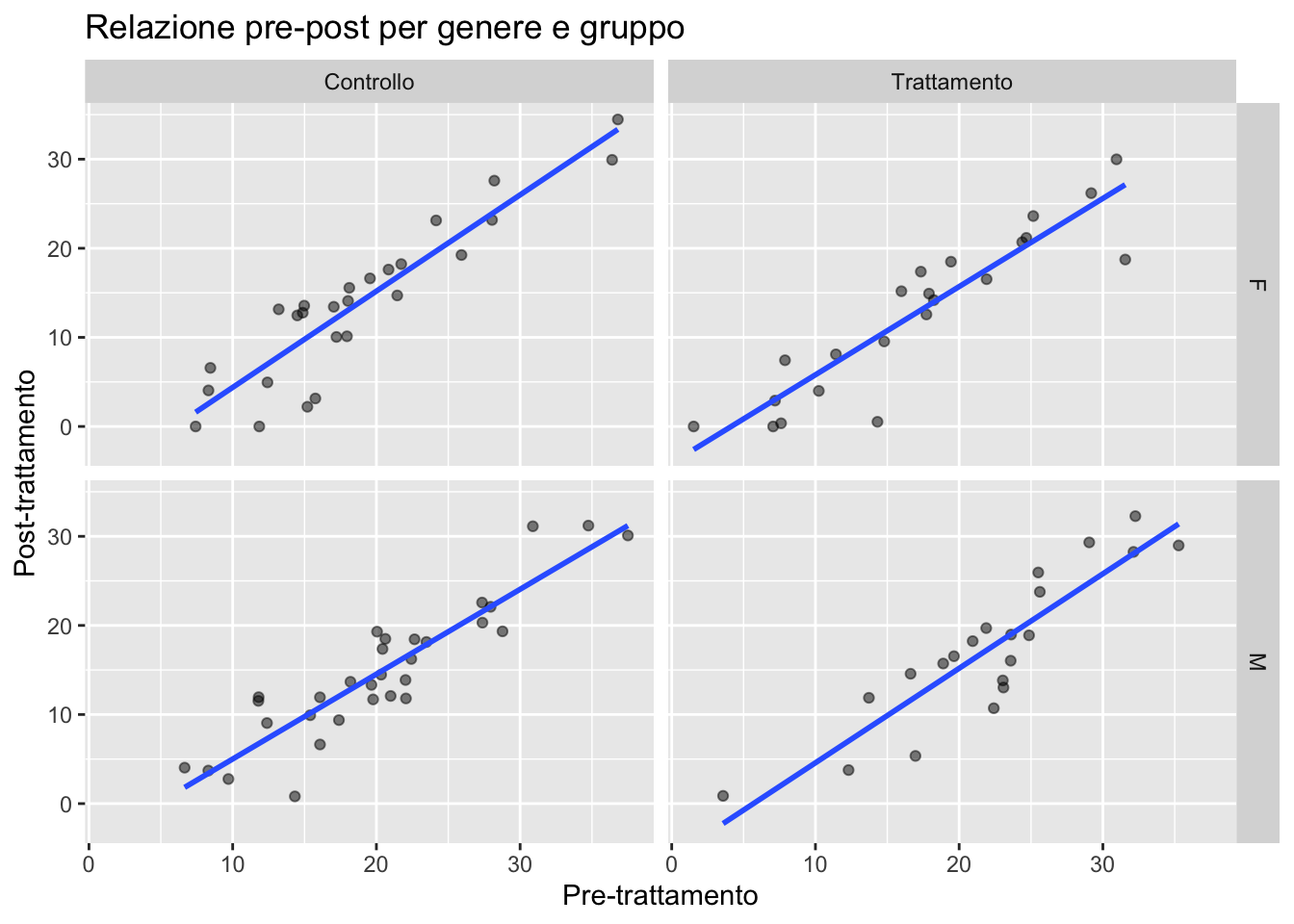
Sintassi: facet_grid(righe ~ colonne)
-
facet_wrap(): una variabile (o più variabili con impaginazione flessibile) -
facet_grid(): due variabili, con griglia esplicita righe × colonne
11.7 Temi e personalizzazione
I temi controllano gli elementi non legati ai dati (sfondo, griglie, caratteri, spaziature).
11.7.1 Temi predefiniti
base_plot <- ggplot(depression) +
aes(x = pre_bdi, y = post_bdi, color = gruppo) +
geom_point()
base_plot + theme_gray() + ggtitle("theme_gray")
base_plot + theme_minimal() + ggtitle("theme_minimal")
base_plot + theme_classic() + ggtitle("theme_classic")
base_plot + theme_bw() + ggtitle("theme_bw")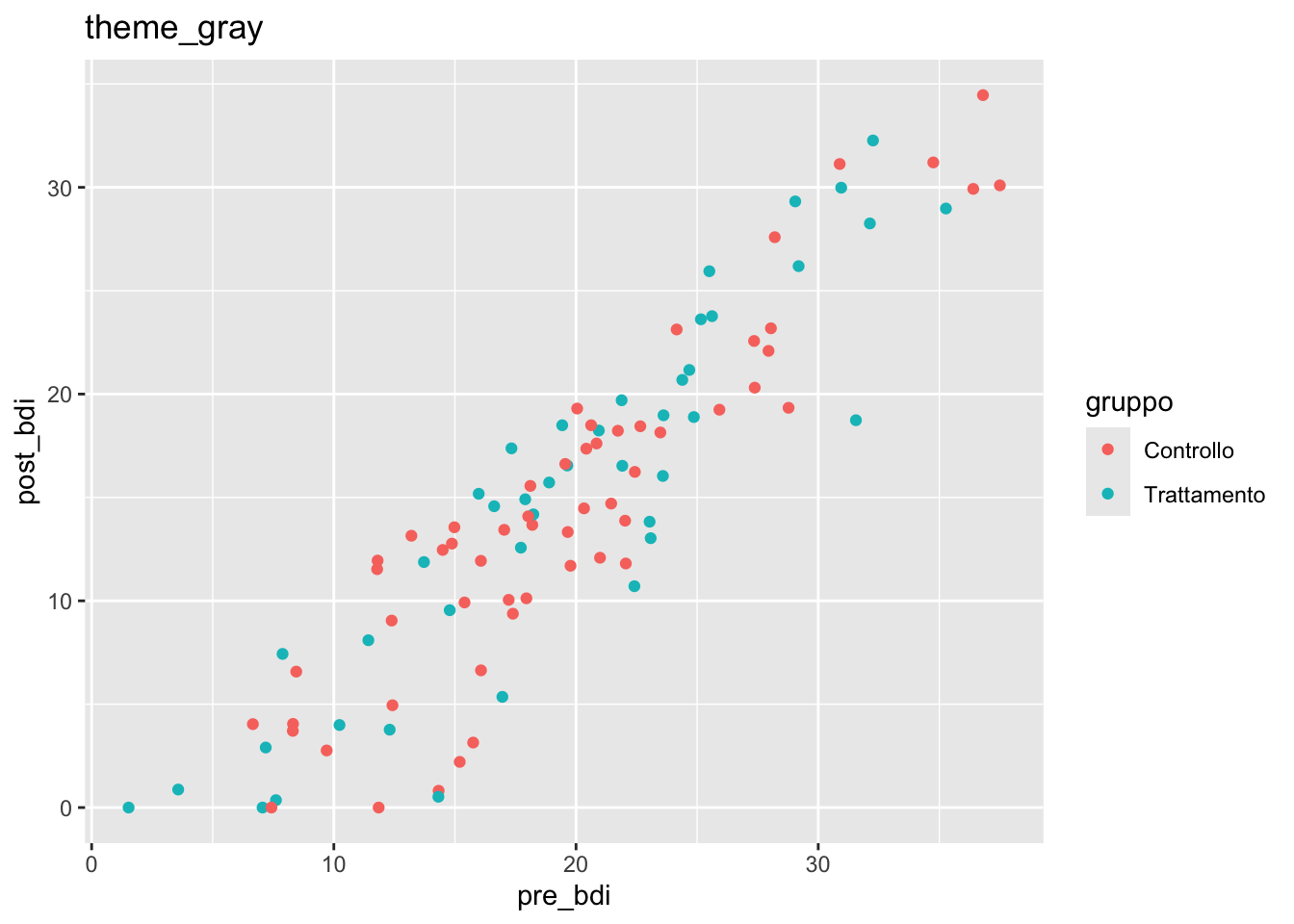
Temi comuni:
-
theme_gray(): predefinito (sfondo grigio) -
theme_minimal(): essenziale e moderno -
theme_classic(): stile “da pubblicazione” (senza griglia) -
theme_bw(): bianco e nero
11.7.2 Personalizzazione fine con theme()
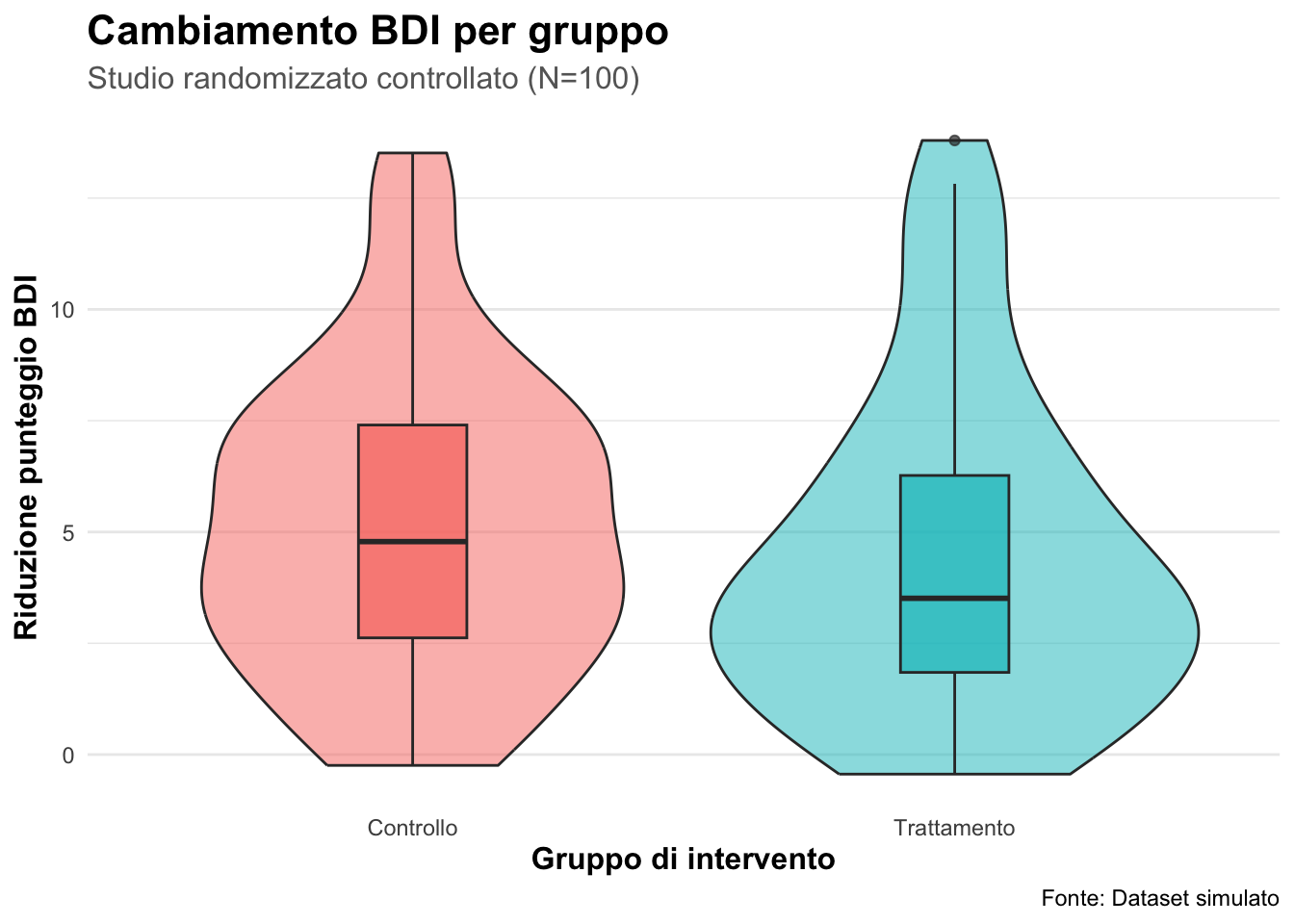
ggplot(depression) +
aes(x = gruppo, y = cambiamento, fill = gruppo) +
geom_violin(alpha = 0.5) +
geom_boxplot(width = 0.2, alpha = 0.7) + # Boxplot sovrapposto
labs(
title = "Cambiamento BDI per gruppo",
subtitle = "Studio randomizzato controllato (N=100)",
x = "Gruppo di intervento",
y = "Riduzione punteggio BDI",
caption = "Fonte: Dataset simulato"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 16, face = "bold"),
plot.subtitle = element_text(size = 12, color = "gray40"),
axis.title = element_text(size = 12, face = "bold"),
legend.position = "none", # Nasconde legenda (ridondante)
panel.grid.major.x = element_blank() # Rimuove griglia verticale
)
Elementi spesso personalizzati (esempi):
-
plot.title: titolo -
axis.text: etichette sugli assi -
legend.position: posizione della legenda ("none","bottom","right", …) -
panel.grid: griglia di sfondo
11.8 Salvare i grafici
11.8.1 Con ggsave()
#| label: save-plot
#| eval: false
# Salva l’ultimo grafico creato
ggsave("grafico.png", width = 8, height = 6, dpi = 300)
# Salva un grafico specifico
mio_plot <- ggplot(depression) + aes(x = pre_bdi) + geom_histogram()
ggsave("istogramma_bdi.pdf", plot = mio_plot, width = 10, height = 6)Parametri principali:
-
filename: nome del file (l’estensione determina il formato:.png,.pdf,.svg) -
width,height: dimensioni (in pollici) -
dpi: risoluzione (300 per stampa/pubblicazione, 150 per presentazioni) -
plot: oggettoggplotda salvare (default: l’ultimo creato)
- PNG: presentazioni e web (raster)
- PDF: articoli e stampa (vettoriale, scalabile)
- SVG: web ed editing successivo (Inkscape/Illustrator)
11.9 Scale: controllo di assi e legende
Le scale determinano come i valori dei dati vengono mappati sulle estetiche del grafico e come tale mappatura viene rappresentata tramite assi e legende.
11.9.1 Scale continue
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi, color = cambiamento) +
geom_point(size = 3) +
scale_x_continuous(
breaks = seq(0, 40, by = 10),
limits = c(0, 40)
) +
scale_y_continuous(
breaks = seq(0, 40, by = 10),
limits = c(0, 40)
) +
scale_color_gradient(
low = "blue",
high = "red",
name = "Miglioramento\n(punti)"
) +
labs(
title = "Punteggi BDI pre-post con miglioramento",
x = "Pre-trattamento",
y = "Post-trattamento"
) +
theme_minimal()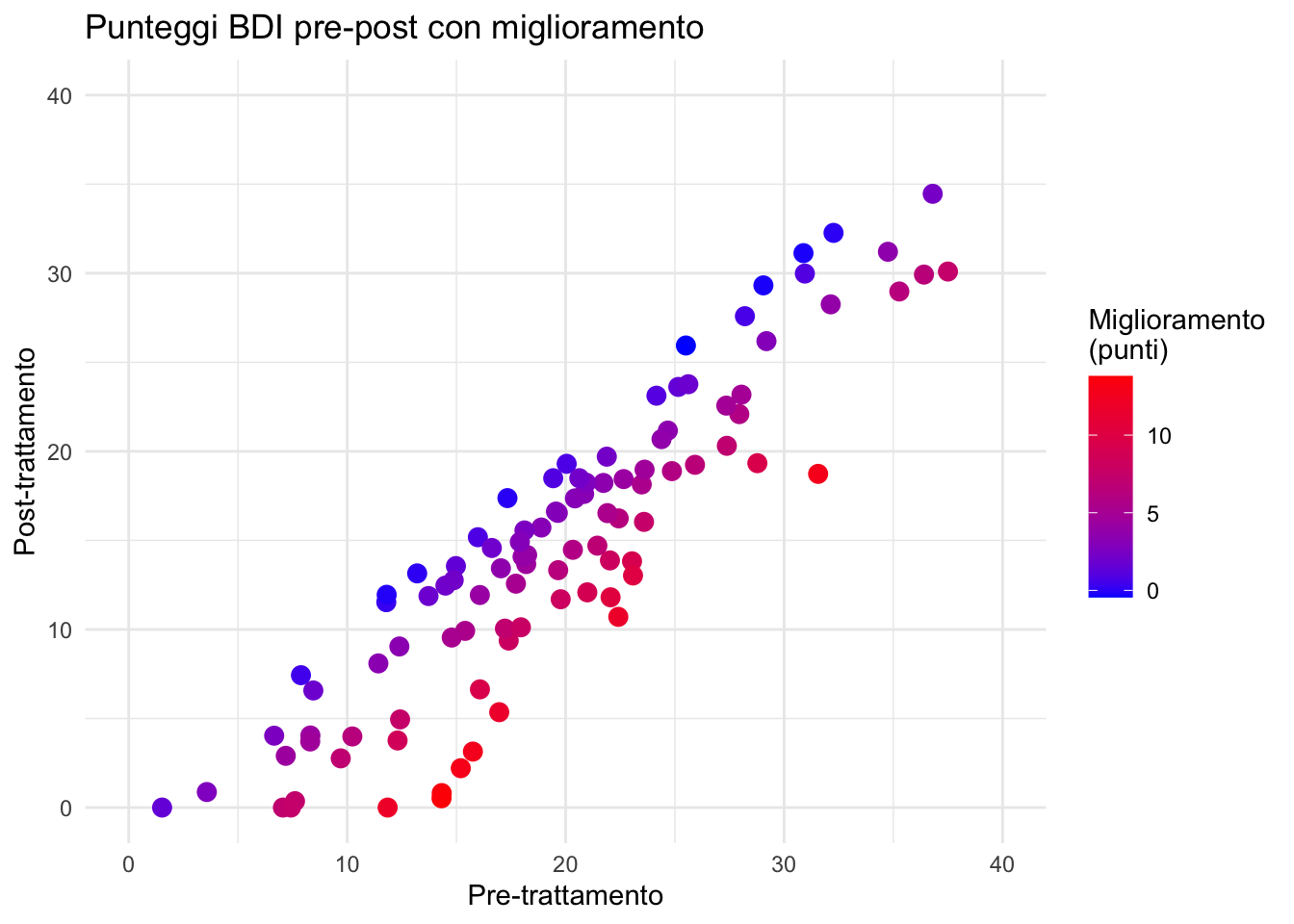
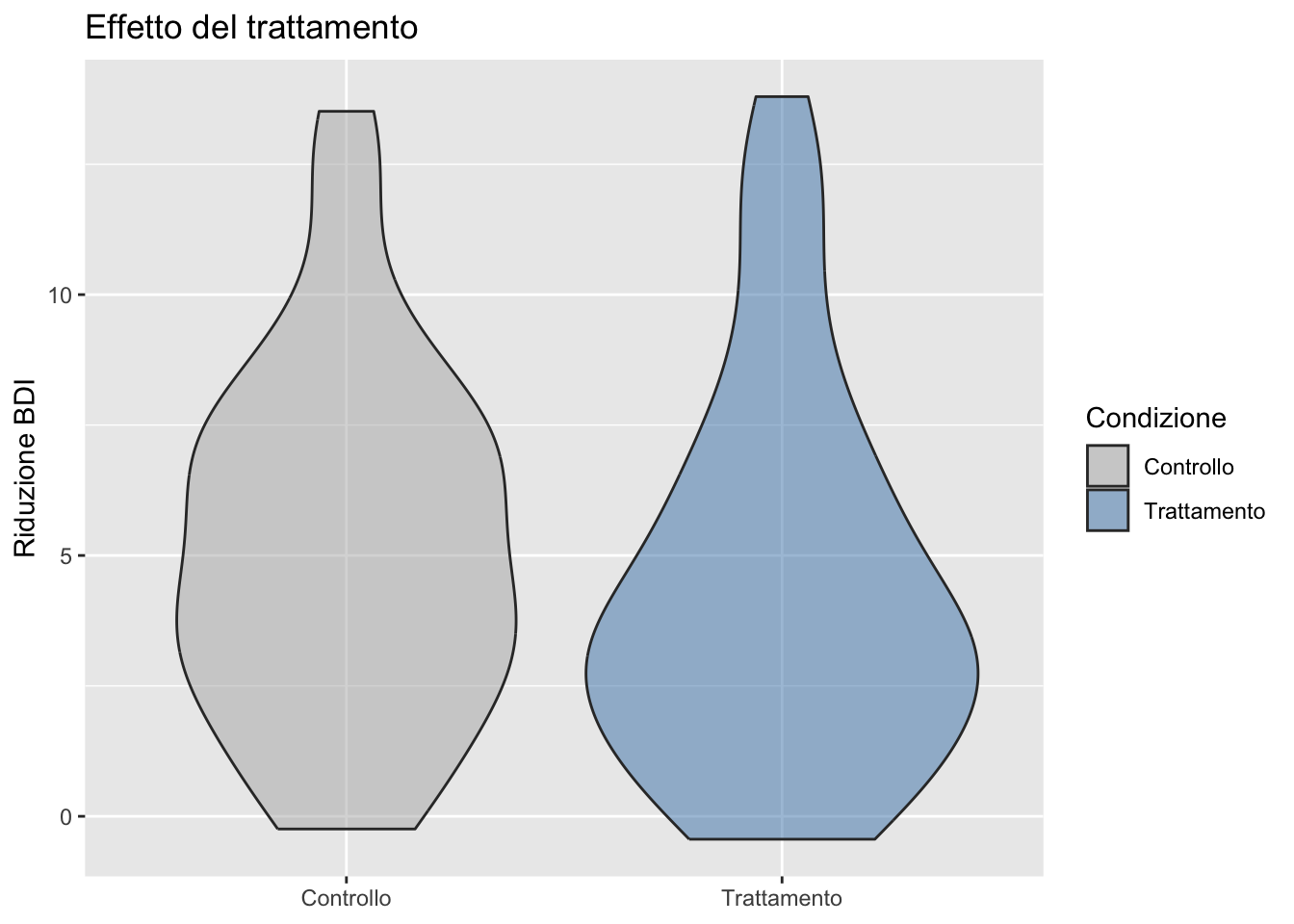
11.9.2 Scale discrete
ggplot(depression) +
aes(x = gruppo, y = cambiamento, fill = gruppo) +
geom_violin(alpha = 0.5) +
scale_fill_manual(
values = c("Controllo" = "gray70", "Trattamento" = "steelblue"),
name = "Condizione"
) +
labs(
title = "Effetto del trattamento",
x = NULL, # Rimuove etichetta asse x (ridondante con legenda)
y = "Riduzione BDI"
) 
Funzioni scale comuni:
-
scale_x_continuous(),scale_y_continuous(): assi numerici. -
scale_color_manual(),scale_fill_manual(): colori personalizzati. -
scale_color_brewer(): paletteColorBrewer(ottime per daltonici). -
scale_x_log10(): scala logaritmica.
11.10 Grafici complessi: esempio Stroop
Mettiamo insieme i diversi elementi visti finora applicandoli al dataset Stroop.
# Calcola statistiche per partecipante
stroop_summary <- stroop |>
group_by(partecipante, condizione) |>
summarise(
rt_media = mean(rt),
rt_se = sd(rt) / sqrt(n()),
.groups = "drop"
)
ggplot(stroop_summary) +
aes(x = condizione, y = rt_media, group = partecipante) +
# Linee che collegano le misure ripetute
geom_line(alpha = 0.3, color = "gray50") +
# Punti per ogni partecipante
geom_point(aes(color = condizione), size = 2, alpha = 0.6) +
# Statistiche aggregate sovrapposte
stat_summary(
fun = mean,
geom = "point",
size = 4,
color = "black",
shape = 18 # Diamante
) +
stat_summary(
fun.data = mean_se,
geom = "errorbar",
width = 0.2,
linewidth = 1,
color = "black"
) +
scale_color_manual(
values = c("Congruente" = "#2E7D32", "Incongruente" = "#C62828")
) +
labs(
title = "Effetto Stroop: Tempi di reazione per condizione",
subtitle = "Linee grigie = singoli partecipanti; diamanti neri = medie aggregate",
x = "Condizione",
y = "Tempo di reazione (ms)",
color = "Condizione"
) +
theme(
plot.title = element_text(size = 14, face = "bold"),
plot.subtitle = element_text(size = 10, color = "gray40"),
legend.position = "none" # Ridondante con asse x
)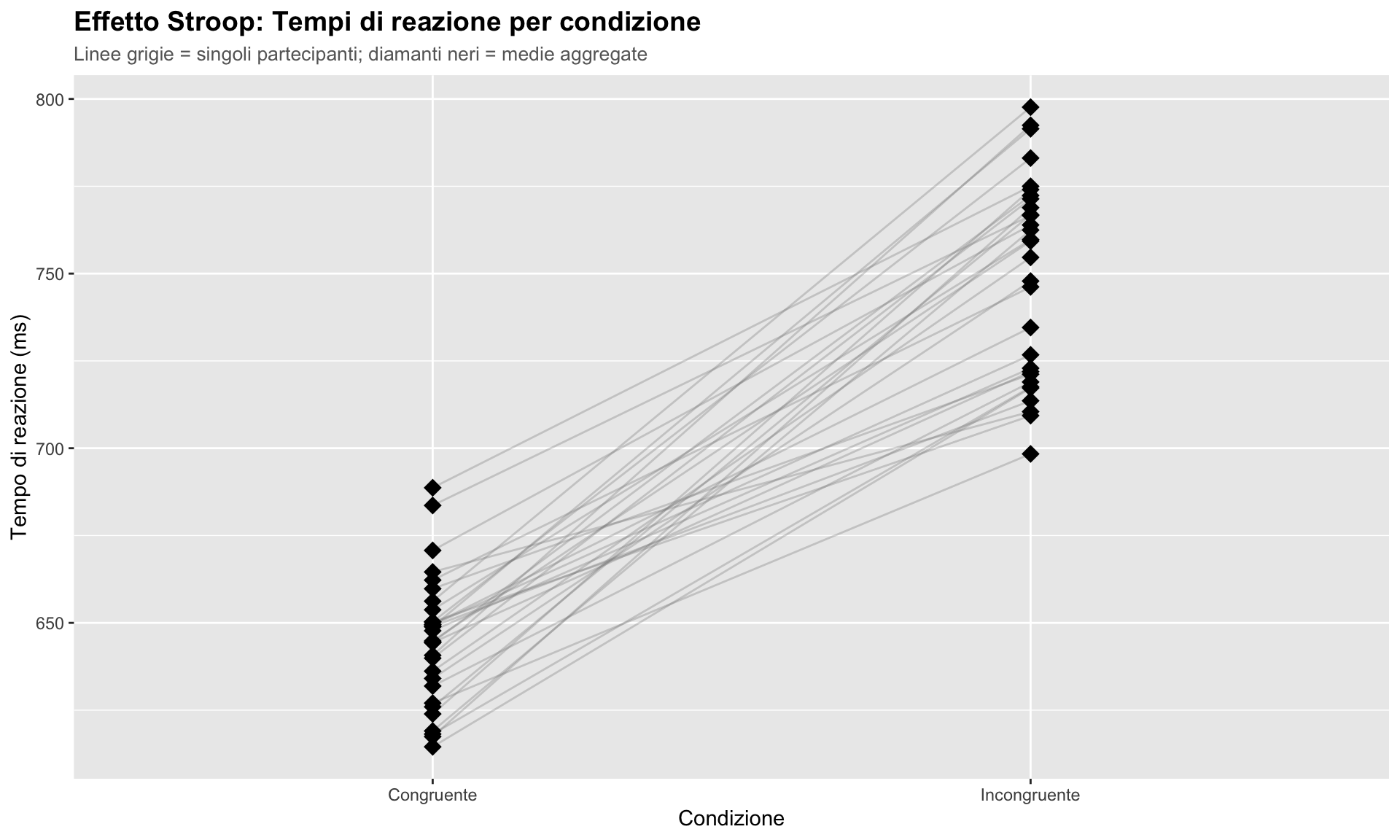
Elementi chiave:
-
geom_line(): connette misure ripetute dello stesso partecipante. -
stat_summary(): calcola e sovrappone statistiche aggregate. -
scale_color_manual(): colori semantici (verde = veloce, rosso = lento). - trasparenza (
alpha) per distinguere livelli individuali vs. aggregati.
11.11 Best practices per grafici scientifici
11.11.1 1. Chiarezza prima di tutto
✅ Buone pratiche:
- Titoli informativi e descrittivi.
- Assi chiaramente etichettati, con unità di misura.
- Legende esplicative.
- Caratteri leggibili (≥ 10 pt).
❌ Da evitare:
- Grafici sovraffollati.
- Colori difficili da distinguere.
- Eccesso di informazioni in un singolo grafico.
- Effetti tridimensionali non informativi.
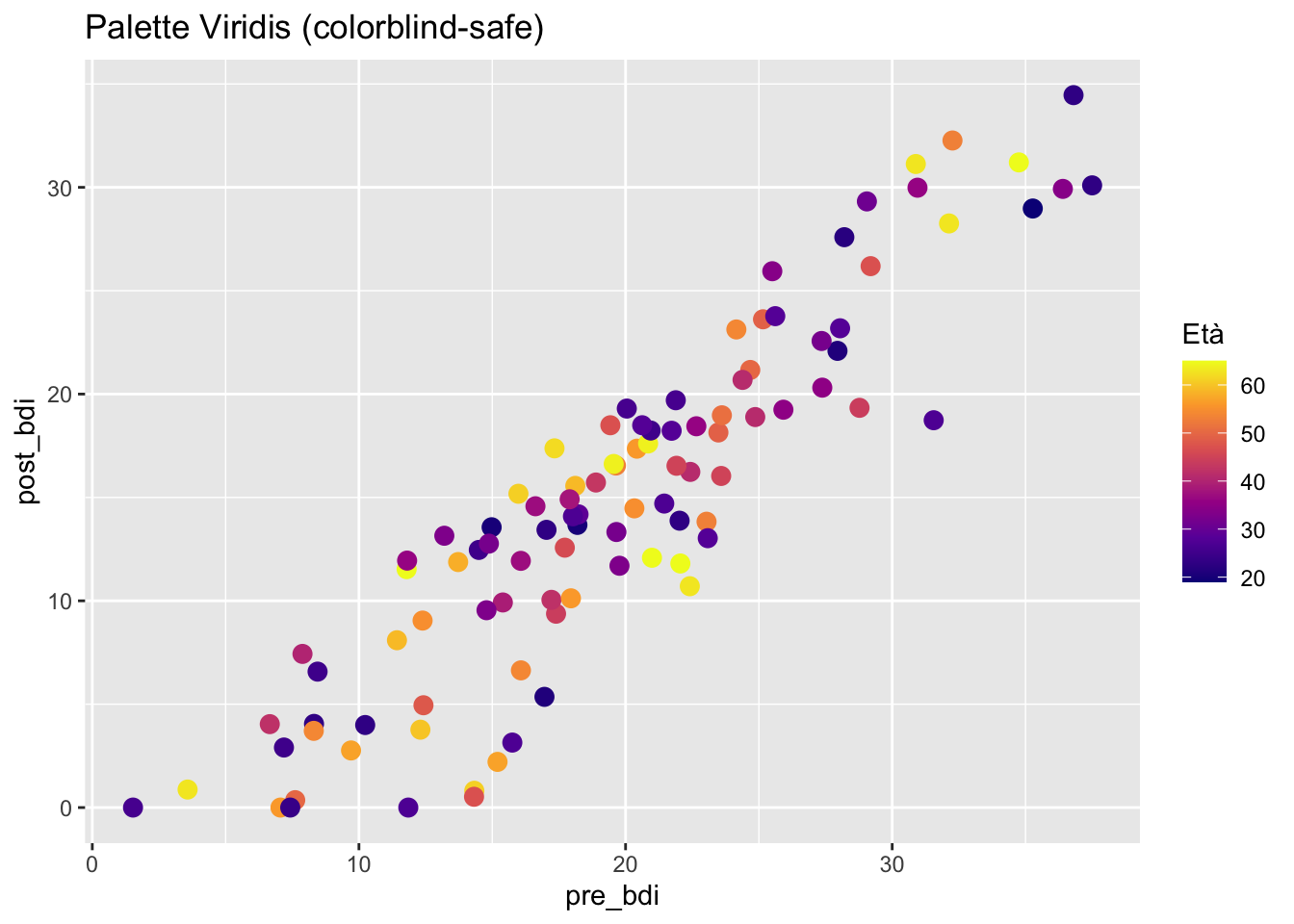
11.11.2 2. Colori accessibili
Utilizza palette adatte anche a persone con deficit di visione dei colori:
library(viridis)
ggplot(depression) +
aes(x = pre_bdi, y = post_bdi, color = eta) +
geom_point(size = 3) +
scale_color_viridis_c(option = "plasma") +
labs(
title = "Palette Viridis (colorblind-safe)",
color = "Età"
) 
Palette consigliate:
-
viridis,magma,plasma,inferno(pacchettoviridis) - Palette
ColorBrewer(es.scale_color_brewer(palette = "Set2"))
11.11.3 3. Rapporto larghezza/altezza
Dimensioni comunemente adottate nelle pubblicazioni APA:
- Colonna singola: 3.5 × 3.5 pollici.
- Due colonne: 7 × 5 pollici.
- Slide: 10 × 6 pollici (16:9) oppure 10 × 7.5 pollici (4:3).
11.11.4 4. Esportazione in formati vettoriali
Per garantire la massima qualità grafica:
11.12 Risorse aggiuntive
11.12.1 Geometrie non trattate qui
ggplot2 include numerose geometrie; alcune particolarmente utili in ambito psicologico:
-
geom_jitter(): scatterplot con jitter per ridurre la sovrapposizione. -
geom_pointrange(): punti con intervalli (effect size, CI). -
geom_tile(): heatmap. -
geom_ribbon(): bande di confidenza. -
geom_qq(): QQ-plot per la verifica della normalità.
11.12.2 Estensioni di ggplot2
Pacchetti che ampliano le funzionalità di ggplot2:
-
patchwork: composizione di grafici multipli. -
ggridges: ridge plots per distribuzioni. -
ggdist: visualizzazioni di distribuzioni bayesiane. -
gganimate: animazioni. -
plotly: grafici interattivi.
11.12.3 Libri e tutorial
- ggplot2 book di Hadley Wickham.
- R Graphics Cookbook di Winston Chang.
- Data Visualization with R di Rob Kabacoff.
11.13 Esercizi
11.13.1 🟢 Esercizio 1: Istogramma base
Crea un istogramma dei tempi di reazione nel dataset stroop. Usa binwidth = 50 e aggiungi titoli appropriati.
ggplot(stroop) +
aes(x = rt) +
geom_histogram(binwidth = 50, fill = "coral", color = "white") +
labs(
title = "Distribuzione dei tempi di reazione",
x = "Tempo di reazione (ms)",
y = "Frequenza"
) +
theme_minimal()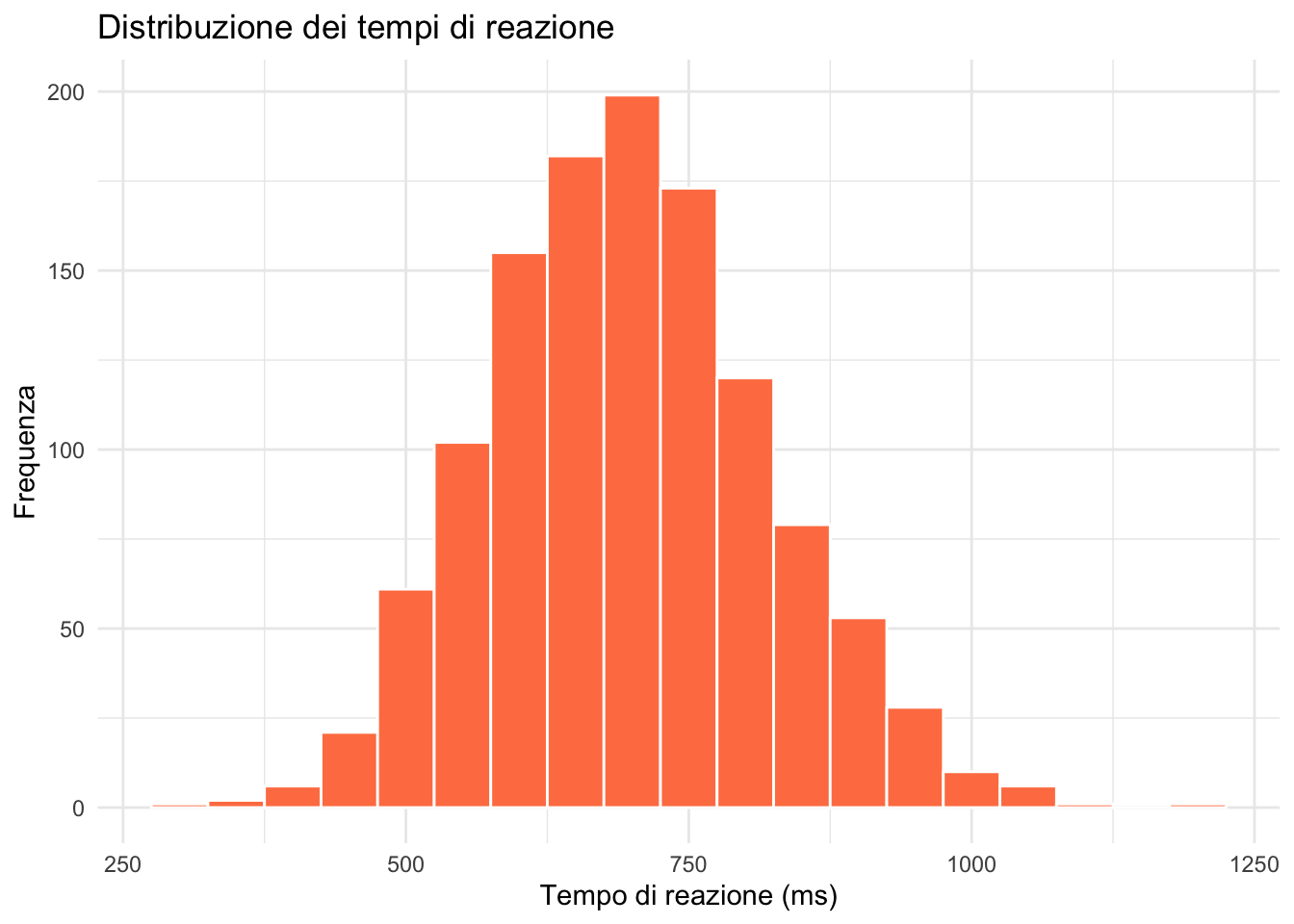
11.13.2 🟢 Esercizio 2: Boxplot per gruppo
Crea un boxplot che confronti i tempi di reazione tra condizioni congruenti e incongruenti.
ggplot(stroop) +
aes(x = condizione, y = rt, fill = condizione) +
geom_boxplot() +
labs(
title = "Confronto RT: Stroop congruente vs. incongruente",
x = "Condizione",
y = "Tempo di reazione (ms)",
fill = "Condizione"
) +
theme_minimal()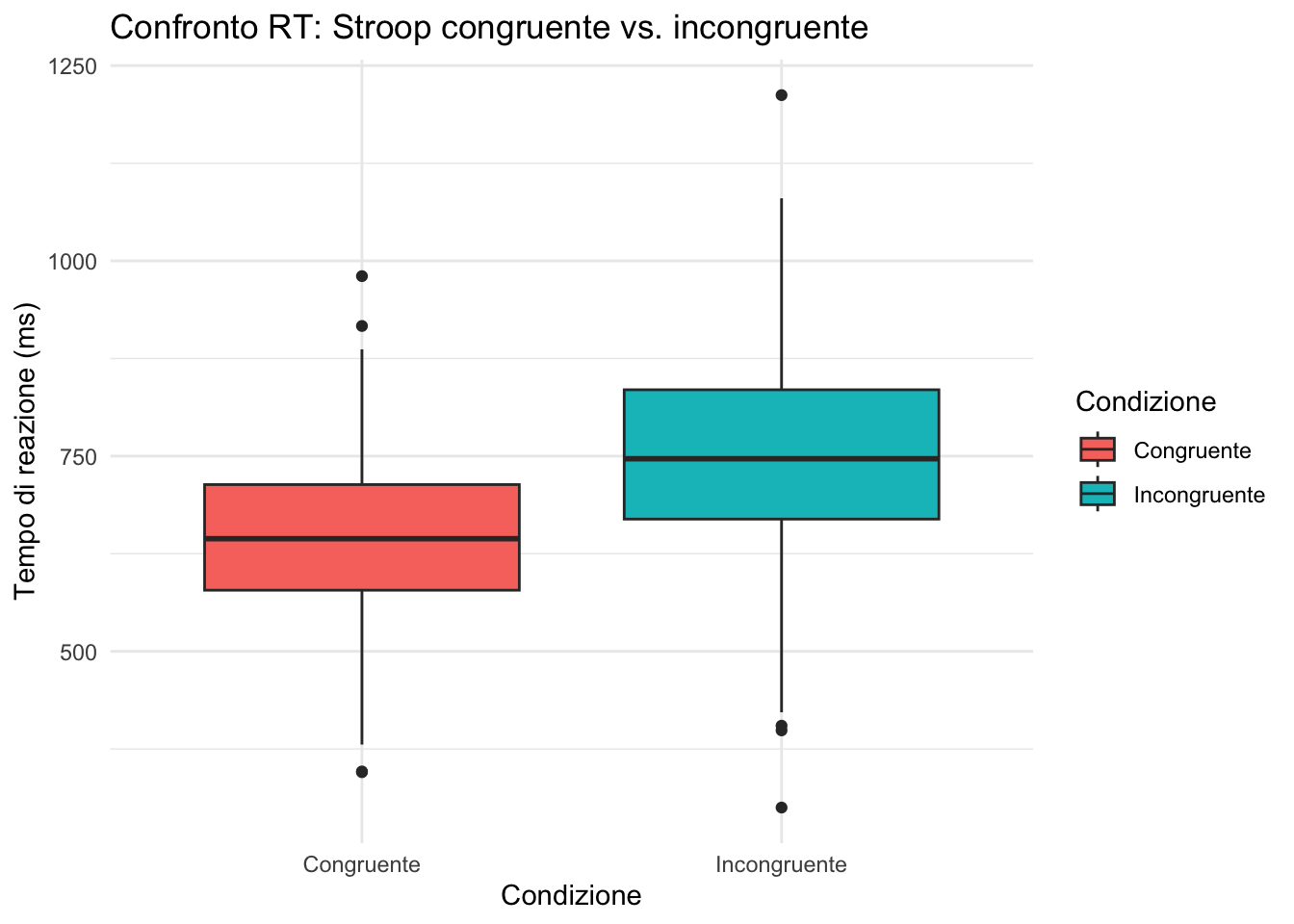
11.13.3 🟡 Esercizio 3: Scatterplot con faceting
Crea uno scatterplot della relazione tra età e cambiamento BDI (dataset depression), con faceting per gruppo e colore per genere.
ggplot(depression) +
aes(x = eta, y = cambiamento, color = genere) +
geom_point(alpha = 0.6) +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(~ gruppo) +
labs(
title = "Età e risposta al trattamento",
x = "Età (anni)",
y = "Riduzione BDI",
color = "Genere"
) +
theme_minimal()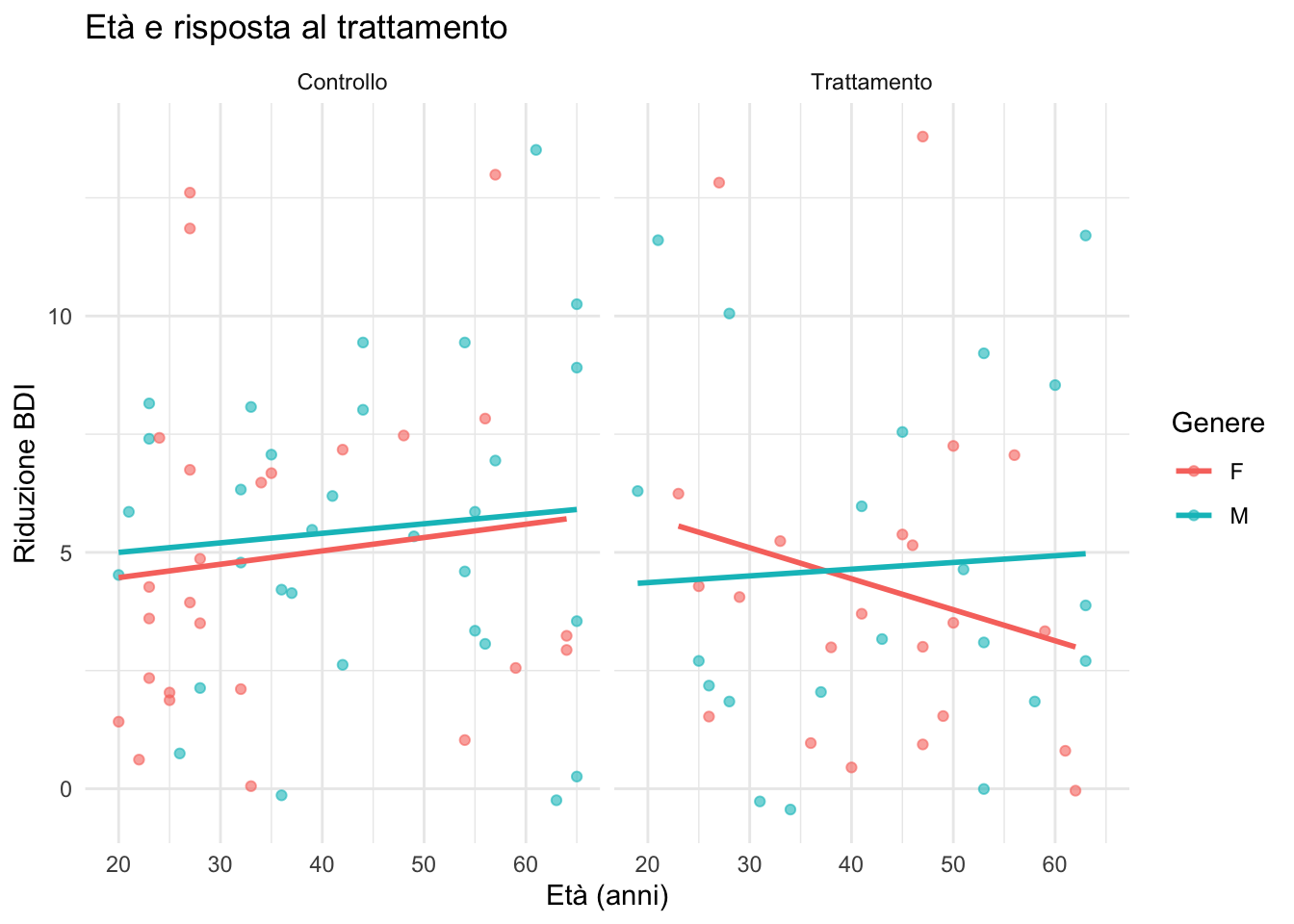
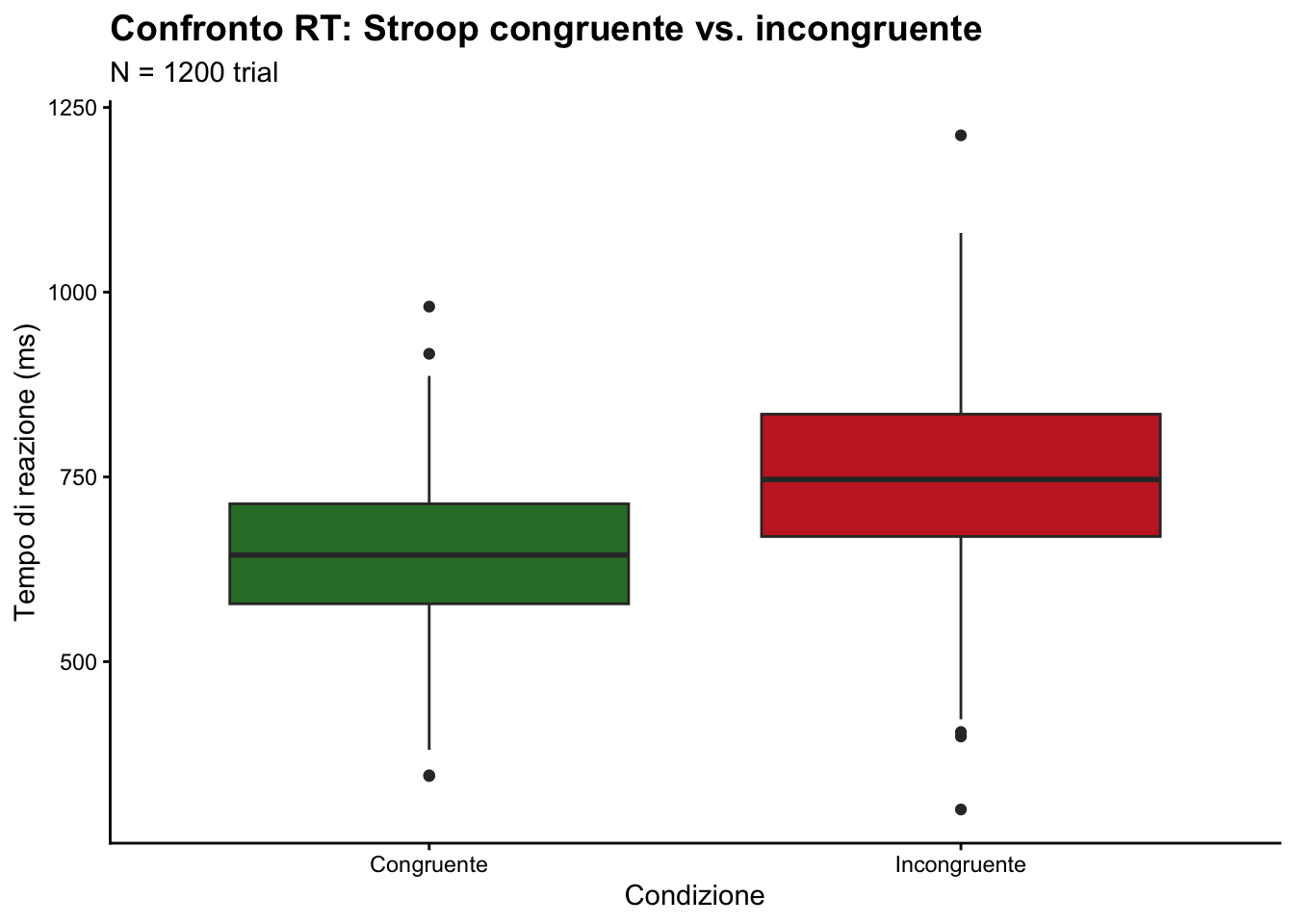
11.13.4 🟡 Esercizio 4: Personalizzazione completa
Ricrea il grafico dell’Esercizio 2 (boxplot RT) ma:
- Usa
theme_classic(). - Cambia colori in rosso (#C62828) e verde (#2E7D32).
- Aggiungi sottotitolo “N = 1200 trial”.
- Rimuovi la legenda (ridondante).
- Aumenta la dimensione del titolo a 14pt.
ggplot(stroop) +
aes(x = condizione, y = rt, fill = condizione) +
geom_boxplot() +
scale_fill_manual(
values = c("Congruente" = "#2E7D32", "Incongruente" = "#C62828")
) +
labs(
title = "Confronto RT: Stroop congruente vs. incongruente",
subtitle = "N = 1200 trial",
x = "Condizione",
y = "Tempo di reazione (ms)"
) +
theme_classic() +
theme(
plot.title = element_text(size = 14, face = "bold"),
legend.position = "none"
)
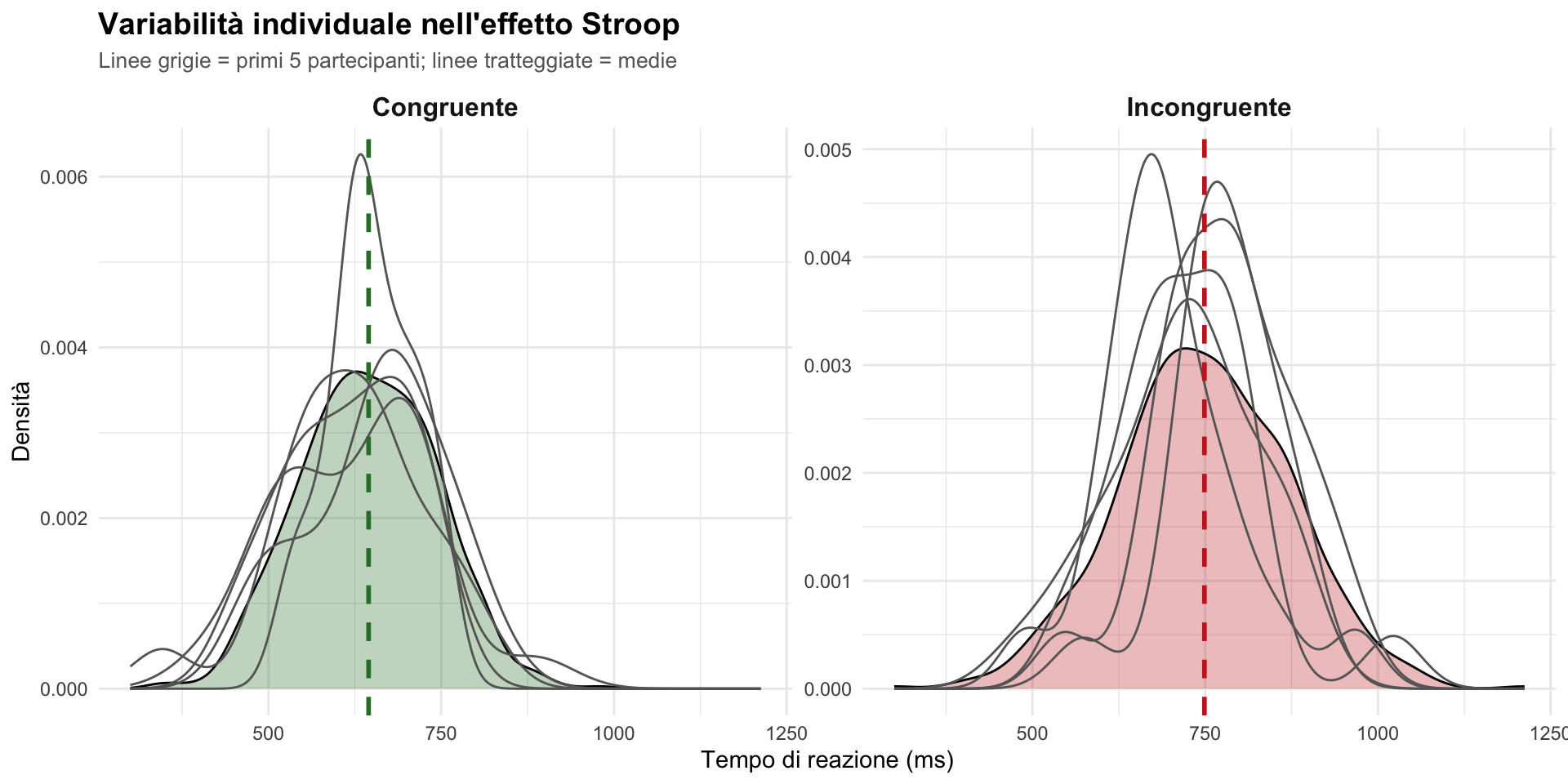
11.13.5 🔴 Esercizio 5: Grafico avanzato
Crea un grafico che mostri:
- Distribuzioni RT (densità) per condizione Stroop.
- Sovrapponi i primi 5 partecipanti come linee individuali semi-trasparenti.
- Evidenzia le medie aggregate con linee verticali tratteggiate.
- Usa faceting per separare le condizioni.
- Personalizza completamente il tema.
# Dati per linee individuali (primi 5 partecipanti)
stroop_ind <- stroop |>
filter(partecipante <= 5)
# Medie per linee aggregate
stroop_medie <- stroop |>
group_by(condizione) |>
summarise(rt_mean = mean(rt))
ggplot() +
# Densità completa
geom_density(
data = stroop,
aes(x = rt, fill = condizione),
alpha = 0.3
) +
# Densità individuale partecipanti
geom_density(
data = stroop_ind,
aes(x = rt, group = partecipante),
alpha = 0.2,
color = "gray40"
) +
# Linee verticali per medie
geom_vline(
data = stroop_medie,
aes(xintercept = rt_mean, color = condizione),
linetype = "dashed",
linewidth = 1
) +
facet_wrap(~ condizione, scales = "free_y") +
scale_fill_manual(
values = c("Congruente" = "#2E7D32", "Incongruente" = "#C62828")
) +
scale_color_manual(
values = c("Congruente" = "#2E7D32", "Incongruente" = "#C62828")
) +
labs(
title = "Variabilità individuale nell'effetto Stroop",
subtitle = "Linee grigie = primi 5 partecipanti; linee tratteggiate = medie",
x = "Tempo di reazione (ms)",
y = "Densità"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
plot.subtitle = element_text(size = 10, color = "gray40"),
legend.position = "none",
strip.text = element_text(size = 12, face = "bold")
)