21 Dalla correlazione alla causalità
- Controfattuali: l’effetto causale è la differenza tra ciò che accade con il trattamento e ciò che accadrebbe senza.
- Confondimento: quando una terza variabile influenza sia la causa che l’effetto, la correlazione osservata può essere fuorviante.
- Randomizzazione: assegnare casualmente il trattamento rende i gruppi comparabili, permettendo di stimare effetti causali.
- Mediazione vs confondimento: distinguere quando una variabile spiega il meccanismo causale da quando lo distorce.
Panoramica del capitolo
- Comprendere cosa significa “effetto causale” in termini controfattuali.
- Distinguere tra associazione osservata e effetto causale.
- Riconoscere il confondimento e capire perché è problematico.
- Introdurre le simulazioni come strumento per visualizzare questi concetti.
- Distinguere tra confondimento, mediazione e moderazione.
- Leggere l’introduzione dell’articolo “The curious case of the cross-sectional correlation” (Hamaker, 2024).
- Leggere il primo capitolo di Hernan & Robins (2023) “A Definition of Causal Effect”.
21.1 Intuizioni quotidiane di causalità
Nella vita di tutti i giorni formuliamo continuamente inferenze causali, spesso in modo implicito e inconsapevole. Quando uno studente si chiede: “Se ripasso mentalmente quell’argomento prima dell’esame, mi sentirò meno ansioso?”, sta ponendo una vera e propria domanda causale. È presente un’azione potenziale, il ripasso mentale, che in termini statistici può essere interpretato come un trattamento, e un esito di interesse, il livello di ansia.
Queste intuizioni spontanee non sono vaghe o imprecise, ma riflettono una struttura logica ben definita che la statistica moderna ha formalizzato attraverso il concetto di controfattuale. L’idea, nella sua essenza, è semplice ma estremamente potente.
Per stabilire se il ripasso mentale causa una riduzione dell’ansia, dovremmo poter confrontare due scenari alternativi riferiti allo stesso studente e allo stesso momento:
- Scenario A: lo studente effettua il ripasso mentale e osserviamo il suo livello di ansia.
- Scenario B: lo stesso studente, nelle medesime condizioni, non effettua il ripasso e osserviamo il suo livello di ansia.
La differenza tra i livelli di ansia osservati in questi due scenari rappresenterebbe l’effetto causale del ripasso mentale.
Il problema fondamentale dell’inferenza causale è che solo uno di questi due scenari può essere osservato: lo studente o ripassa, oppure non lo fa. L’altro scenario rimane inevitabilmente non osservabile, ovvero controfattuale. Proprio questa impossibilità, ovvero osservare simultaneamente ciò che è accaduto e ciò che sarebbe accaduto in alternativa, è al cuore delle difficoltà metodologiche dell’analisi causale e motiva lo sviluppo di strumenti statistici più sofisticati, che verranno introdotti nei capitoli successivi.
Per ogni individuo possiamo osservare solo uno dei due esiti potenziali. L’altro rimane invisibile. Questo è chiamato il problema fondamentale dell’inferenza causale (Holland, 1986).
21.2 Formalizzare i controfattuali
La statistica rende esplicita l’intuizione quotidiana appena discussa traducendola in un linguaggio formale. Per ogni individuo esposto a una possibile azione o intervento, che chiameremo trattamento, possiamo concettualmente distinguere due esiti potenziali:
- \(Y^{(1)}\): l’esito che si osserverebbe se l’individuo ricevesse il trattamento;
- \(Y^{(0)}\): l’esito che si osserverebbe se lo stesso individuo non ricevesse il trattamento.
Questi due esiti rappresentano i possibili risultati alternativi associati alle due condizioni di interesse. Naturalmente, per ciascun individuo possiamo osservare al più uno di questi due esiti.
Se indichiamo con \(A\) il trattamento effettivamente ricevuto, dove \(A = 1\) se l’individuo riceve il trattamento e \(A = 0\) altrimenti, l’esito osservato \(Y\) può essere scritto come:
\[ Y = \begin{cases} Y^{(1)} & \text{se } A = 1, \ Y^{(0)} & \text{se } A = 0. \end{cases} \]
Questa relazione esprime il principio di consistenza: l’esito che osserviamo coincide con l’esito potenziale corrispondente al trattamento effettivamente ricevuto. In altre parole, non esiste ambiguità tra ciò che accade e il modo in cui definiamo gli esiti potenziali: l’osservazione è semplicemente una realizzazione di uno dei due scenari controfattuali possibili.
Questo formalismo costituisce il punto di partenza per tutta l’inferenza causale moderna e rende esplicita, in termini matematici, l’idea intuitiva secondo cui ogni domanda causale implica un confronto tra ciò che è accaduto e ciò che sarebbe potuto accadere in condizioni alternative.
21.2.1 Effetto causale individuale e medio
A livello individuale, l’effetto causale di un trattamento può essere definito come la differenza tra i due esiti potenziali associati allo stesso individuo:
\[ \tau_i = Y_i^{(1)} - Y_i^{(0)} . \]
Questa quantità rappresenta ciò che accadrebbe a una persona se potessimo confrontare direttamente la sua esperienza sotto trattamento con quella che avrebbe avuto in assenza di trattamento. Tuttavia, come abbiamo visto, per ogni individuo possiamo osservare solo uno dei due esiti potenziali. Di conseguenza, l’effetto causale individuale rimane, nella pratica, non osservabile.
Per superare questo limite, l’analisi causale si sposta a un livello aggregato e considera l’effetto medio del trattamento su una popolazione. Questa quantità è nota come effetto causale medio (Average Causal Effect, ACE) ed è definita come:
\[ \text{ACE} = \mathbb{E}[Y^{(1)}] - \mathbb{E}[Y^{(0)}]. \]
In termini intuitivi, ci stiamo chiedendo: «Quale sarebbe, in media, la differenza tra un mondo in cui tutti ricevono il trattamento e un mondo in cui nessuno lo riceve?»
Questa è la quantità che la maggior parte degli studi empirici cerca di stimare.
21.2.2 L’assunzione SUTVA
Affinché queste definizioni siano coerenti e interpretabili, è necessario assumere alcune condizioni di base, riassunte nell’acronimo SUTVA (Stable Unit Treatment Value Assumption). In una formulazione intuitiva, SUTVA include due idee fondamentali:
Assenza di interferenza L’esito di un individuo non deve dipendere dal trattamento ricevuto da altri individui. Ad esempio, se uno studente effettua un ripasso mentale prima dell’esame, questo non dovrebbe influenzare il livello di ansia di un altro studente.
Unicità del trattamento Il trattamento deve essere definito in modo chiaro e univoco. Dire che uno studente “fa ripasso” deve avere lo stesso significato per tutti: stessa modalità, stessa intensità, stesso contesto.
Queste assunzioni possono sembrare astratte, ma hanno conseguenze pratiche rilevanti. In studi su interventi di gruppo, ad esempio, l’assenza di interferenza può essere difficile da sostenere. Allo stesso modo, una definizione vaga del trattamento può introdurre ambiguità, rendendo poco chiara l’interpretazione dell’effetto stimato.
21.3 Perché correlazione non è causalità: il salto concettuale
Una volta chiarito cosa intendiamo per effetto causale, diventa più facile comprendere perché questo concetto non coincide con la semplice associazione osservata nei dati.
21.3.1 Due domande diverse
Quando parliamo di effetto causale, stiamo formulando una domanda controfattuale che coinvolge la stessa popolazione in due scenari alternativi:
\[ \text{Effetto causale} = \mathbb{E}[Y^{(1)}] - \mathbb{E}[Y^{(0)}]. \]
Quando invece parliamo di associazione, confrontiamo ciò che osserviamo in due gruppi reali:
\[ \text{Associazione} = \mathbb{E}[Y \mid A = 1] - \mathbb{E}[Y \mid A = 0]. \]
La differenza è sottile ma cruciale. Nel caso causale immaginiamo cosa accadrebbe alla stessa popolazione sotto due condizioni alternative. Nel caso associativo, invece, confrontiamo gruppi di individui che potrebbero differire già prima del trattamento per molte altre caratteristiche rilevanti.
È proprio questa discrepanza tra “mondi ipotetici” e “gruppi osservati” che rende l’inferenza causale più complessa della semplice analisi delle correlazioni e che motiva lo sviluppo di disegni di studio e metodi statistici specificamente pensati per avvicinarsi, per quanto possibile, all’effetto causale di interesse.
21.3.2 Il problema del confondimento
Immaginiamo che a ricevere un trattamento, ad esempio una tecnica di rilassamento, siano soprattutto gli studenti che partono da livelli di ansia più elevati. In questo caso, il semplice confronto tra chi ha ricevuto il trattamento e chi non lo ha ricevuto non riflette soltanto l’effetto del trattamento, ma anche il fatto che i due gruppi erano diversi già prima dell’intervento.
Questa situazione prende il nome di confondimento. Il confondimento si verifica quando esistono variabili che:
- influenzano la probabilità di ricevere il trattamento;
- influenzano anche l’esito che stiamo osservando.
In presenza di confondimento, l’associazione osservata può:
- far apparire un effetto del trattamento quando in realtà non esiste;
- mascherare un effetto reale dietro differenze preesistenti tra i gruppi;
- oppure invertire addirittura il segno dell’effetto (come nel paradosso di Simpson).
21.4 Vedere il confondimento in azione: simulazioni
Per rendere concreti questi concetti, utilizziamo delle simulazioni in R. Le simulazioni hanno un vantaggio cruciale: ci permettono di lavorare in un contesto in cui conosciamo il vero meccanismo generativo dei dati, cosa che nella ricerca empirica reale non è mai possibile.
21.4.1 Simulazione 1: confondimento senza effetto causale
Immaginiamo una situazione in cui il trattamento — ad esempio l’uso di una strategia di reappraisal per ridurre l’ansia — viene scelto più spesso da chi è naturalmente più ansioso. Assumiamo però che il trattamento, di per sé, non abbia alcun effetto causale sull’esito.
In questo scenario:
- l’ansia di tratto influenza sia la probabilità di trattamento sia l’esito;
- il trattamento non ha alcun effetto diretto su \(Y\).
Nonostante ciò, il confronto tra trattati e non trattati produrrà un’associazione apparente.
set.seed(42)
N <- 1000
# Generiamo ansia di tratto (confondente)
ansia_tratto <- rnorm(N, mean = 50, sd = 10)
# Probabilità di trattamento aumenta con l'ansia di tratto
prob_tratt <- plogis((ansia_tratto - 50)/10)
A <- rbinom(N, 1, prob_tratt)
# L'esito dipende SOLO dall'ansia di tratto (non dal trattamento!)
# Effetto causale vero = 0
Y <- ansia_tratto + rnorm(N, 0, 5)
# Confronto osservazionale (sbagliato!)
assoc_obs <- mean(Y[A==1]) - mean(Y[A==0])
# Visualizzazione
par(mfrow=c(1,2))
boxplot(Y ~ A, names=c("Non trattati","Trattati"),
ylab="Esito (ansia)", main="Associazione osservata")
text(1.5, max(Y)*0.95, paste("Diff =", round(assoc_obs, 2)), col="red", cex=1.2)
plot(ansia_tratto, Y, col=ifelse(A==1, "red", "blue"), pch=19, alpha=0.5,
xlab="Ansia di tratto (confondente)", ylab="Esito (ansia)",
main="Struttura del confondimento")
legend("topleft", c("Trattati","Non trattati"), col=c("red","blue"), pch=19)
Cosa osserviamo? I soggetti trattati mostrano un livello di ansia più elevato rispetto ai non trattati. Tuttavia, questo non significa che il trattamento sia dannoso: riflette semplicemente il fatto che chi si tratta è già più ansioso. L’associazione osservata è quindi fuorviante, perché confonde effetto causale e differenze iniziali.
21.4.2 Simulazione 2: il ruolo della randomizzazione
Ripetiamo ora la stessa simulazione, ma assegniamo il trattamento in modo casuale, indipendentemente dal livello di ansia di tratto.
set.seed(43)
N <- 1000
# Stessa struttura di prima
ansia_tratto <- rnorm(N, mean = 50, sd = 10)
# MA ORA: trattamento assegnato casualmente!
A <- rbinom(N, 1, 0.5)
# Esito come prima: dipende solo dall'ansia di tratto
Y <- ansia_tratto + rnorm(N, 0, 5)
# Confronto osservazionale
assoc_rand <- mean(Y[A==1]) - mean(Y[A==0])
# Visualizzazione
par(mfrow=c(1,2))
boxplot(Y ~ A, names=c("Non trattati","Trattati"),
ylab="Esito (ansia)", main="Con randomizzazione")
text(1.5, max(Y)*0.95, paste("Diff =", round(assoc_rand, 2)), col="darkgreen", cex=1.2)
plot(ansia_tratto, Y, col=ifelse(A==1, "red", "blue"), pch=19, alpha=0.5,
xlab="Ansia di tratto", ylab="Esito (ansia)",
main="Randomizzazione: bilanciamento")
legend("topleft", c("Trattati","Non trattati"), col=c("red","blue"), pch=19)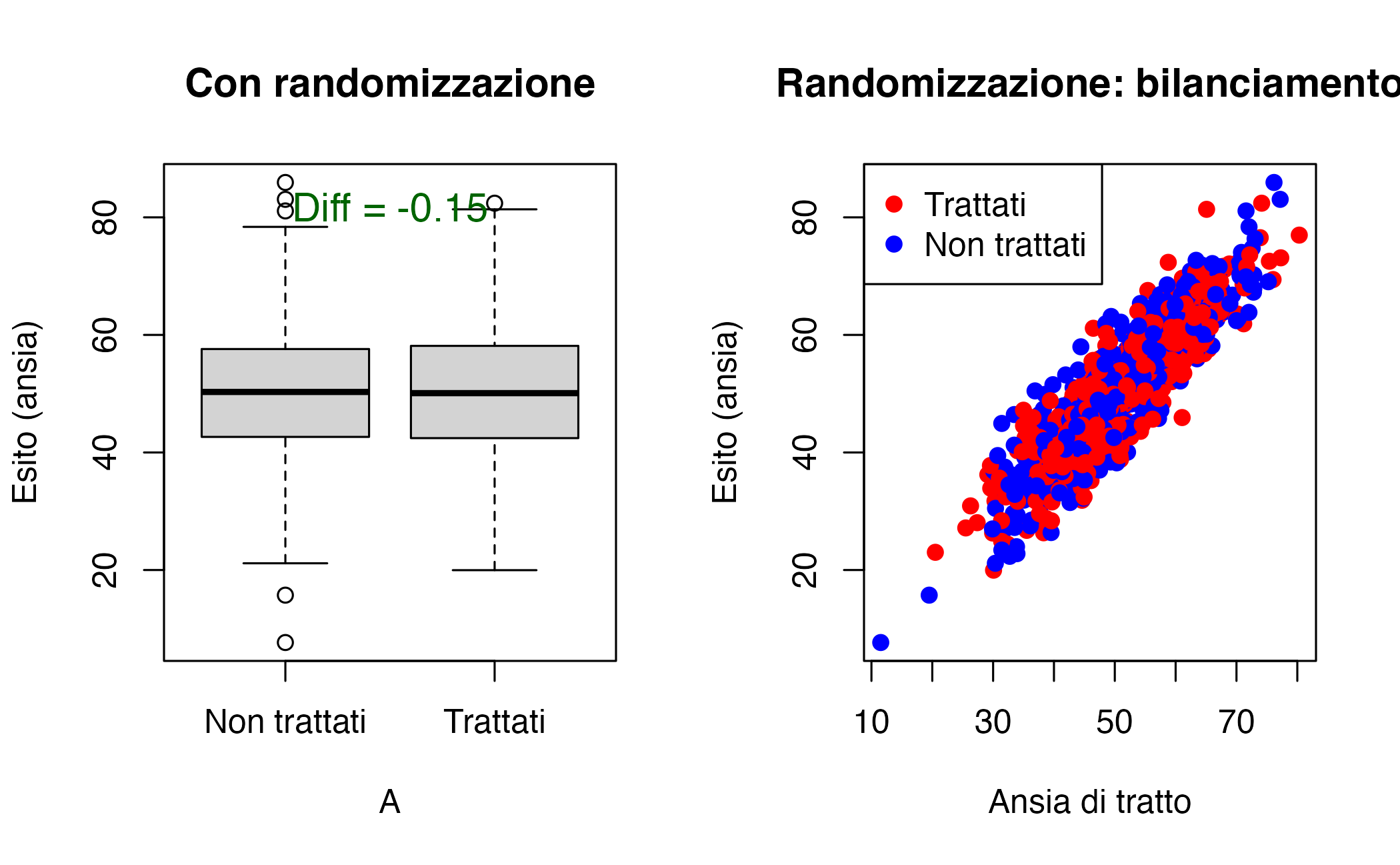
Cosa cambia? Con la randomizzazione, i due gruppi sono comparabili in media: l’ansia di tratto è distribuita in modo simile tra trattati e non trattati. Di conseguenza, la differenza osservata nell’esito è ora molto vicina a zero, riflettendo correttamente il vero effetto causale (che è nullo).
La randomizzazione elimina il confondimento perché spezza il legame sistematico tra trattamento e caratteristiche preesistenti.
La randomizzazione è lo strumento più potente per l’inferenza causale perché:
- rende i gruppi comparabili in media su tutte le caratteristiche, anche quelle non osservate;
- fa sì che l’associazione osservata rifletta l’effetto causale medio;
- rappresenta il gold standard degli studi sperimentali.
21.4.3 Simulazione 3: confondimento e paradosso di Simpson
Un caso particolarmente istruttivo è il paradosso di Simpson, che mostra come il confondimento possa produrre risultati apparentemente contraddittori.
Supponiamo di avere due sottogruppi di studenti:
- uno con bassa ansia di tratto;
- uno con alta ansia di tratto.
Assumiamo che:
- il trattamento abbia lo stesso effetto negativo in entrambi i gruppi (riduce l’esito di −0.3);
- la probabilità di ricevere il trattamento sia maggiore tra gli studenti più ansiosi;
- gli studenti ad alta ansia abbiano esiti mediamente più elevati, indipendentemente dal trattamento.
set.seed(123)
N <- 4000
gruppo <- rbinom(N, 1, 0.5) # 0 = bassa ansia, 1 = alta ansia
# Prevalenze diverse di trattamento
A <- ifelse(gruppo==1, rbinom(N,1,0.7), rbinom(N,1,0.3))
# Effetto causale vero = -0.3 in ENTRAMBI i gruppi
tau <- -0.3
mu <- ifelse(gruppo==1, 0.8, 0.2) # baseline diversi
Y0 <- mu + rnorm(N, 0, 1)
Y1 <- Y0 + tau
Y <- ifelse(A==1, Y1, Y0)
# Calcolo effetti
eff_g0 <- mean(Y[gruppo==0 & A==1]) - mean(Y[gruppo==0 & A==0])
eff_g1 <- mean(Y[gruppo==1 & A==1]) - mean(Y[gruppo==1 & A==0])
eff_marginale <- mean(Y[A==1]) - mean(Y[A==0])
# Visualizzazione
par(mfrow=c(1,2))
# Grafico 1: effetti nei sottogruppi vs marginale
barplot(height = c(eff_g0, eff_g1, eff_marginale),
names.arg = c("Bassa ansia", "Alta ansia", "Totale\n(ignorando gruppo)"),
ylab = "Effetto stimato",
main = "Paradosso di Simpson",
col = c("lightblue", "lightblue", "salmon"))
abline(h = 0, lty = 2)
abline(h = tau, lty = 2, col = "darkgreen")
text(2, tau + 0.15, "Vero effetto = -0.3", col = "darkgreen")
# Grafico 2: struttura dei dati
plot(jitter(gruppo), Y, col=ifelse(A==1, "red", "blue"), pch=19,
xlab="Gruppo (0=bassa ansia, 1=alta ansia)", ylab="Esito",
main="Struttura dei dati", xaxt="n")
axis(1, at=c(0,1), labels=c("Bassa","Alta"))
legend("topleft", c("Trattati","Non trattati"), col=c("red","blue"), pch=19)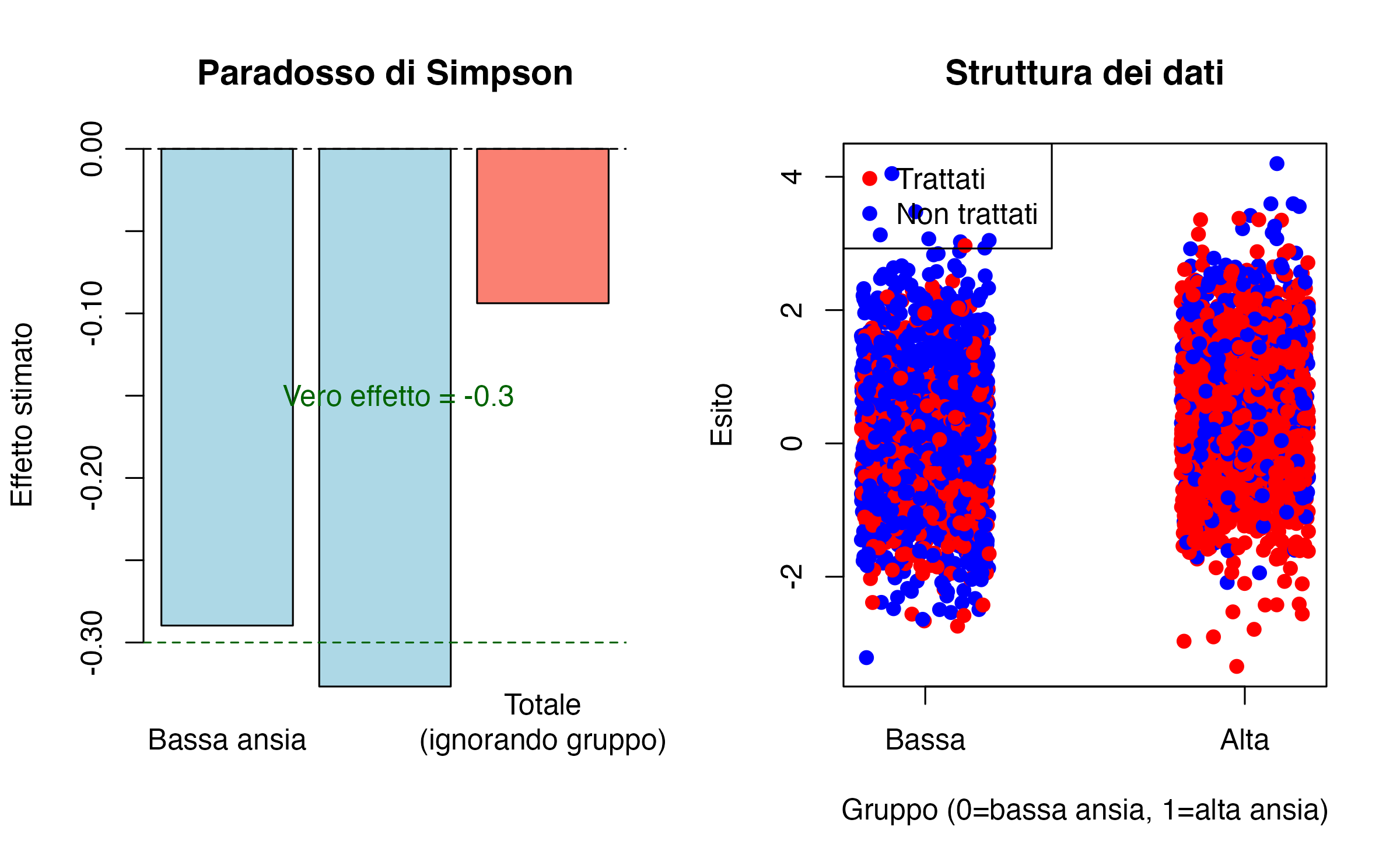
Cosa succede? All’interno di ciascun sottogruppo, il trattamento ha l’effetto atteso: riduce l’esito di circa −0.3. Tuttavia, se ignoriamo la suddivisione in gruppi e confrontiamo semplicemente trattati e non trattati sull’intero campione, l’effetto stimato diventa positivo.
L’inversione nasce perché tra i trattati è sovrarappresentato il gruppo con ansia più elevata, che ha esiti più alti per natura.
Lo stesso effetto può:
- essere coerente e stabile nei sottogruppi;
- apparire opposto a livello aggregato.
Questo mostra che:
- le associazioni osservate possono essere profondamente fuorvianti;
- identificare e controllare i confondenti è essenziale;
- l’analisi stratificata può rivelare la struttura reale dei dati.
21.4.4 Messaggio chiave
Il confondimento non è un dettaglio tecnico, ma un problema centrale dell’inferenza causale. Senza un disegno adeguato (come la randomizzazione) o senza un controllo esplicito delle variabili rilevanti, l’associazione osservata non coincide con l’effetto causale. Le simulazioni rendono evidente perché la causalità richiede strumenti concettuali e metodologici più forti della semplice comparazione tra gruppi.
21.5 Oltre il confondimento: mediazione e moderazione
Abbiamo visto che il confondimento è problematico perché altera la relazione tra trattamento ed esito, rendendo fuorviante l’interpretazione causale. Tuttavia, non tutte le cosiddette terze variabili svolgono questo ruolo. A seconda di come una variabile si colloca rispetto a trattamento ed esito, essa può avere significati molto diversi.
È quindi fondamentale distinguere tra confondimento, mediazione e moderazione. Sebbene questi concetti vengano talvolta confusi, essi rispondono a domande scientifiche profondamente diverse.
21.5.1 Variabili di confondimento
Una variabile di confondimento è una variabile che influisce sia sul trattamento sia sull’esito, creando un’associazione che non riflette un legame causale diretto.
Esempio (psicologico). Studiamo la relazione tra uso dei social media e sintomi depressivi negli adolescenti. La solitudine può agire come confondente perché:
- gli adolescenti più soli tendono a usare maggiormente i social media;
- la solitudine è anche un fattore di rischio per la depressione.
Solitudine
↙ ↘
Social media → Depressione?Se non teniamo conto della solitudine, potremmo concludere erroneamente che l’uso dei social media causa la depressione, quando in realtà entrambi sono in parte conseguenze di una stessa condizione di base.
Quando c’è confondimento Per stimare correttamente l’effetto causale è necessario controllare per il confondente, ad esempio includendolo nel modello statistico, stratificando o utilizzando tecniche di matching.
21.5.2 Variabili mediatrici
Una variabile mediatrice non distorce la relazione causale, ma ne rappresenta il meccanismo. È il passaggio attraverso cui il trattamento esercita il suo effetto sull’esito.
Esempio (psicologico). Studiamo l’effetto dello stress sul rendimento agli esami. La qualità del sonno può fungere da mediatore:
Stress → Qualità del sonno → RendimentoLo stress peggiora il sonno, e un sonno di scarsa qualità compromette la performance accademica. Il sonno non è una fonte di distorsione, ma il canale attraverso cui lo stress agisce.
Quando c’è mediazione Se vogliamo stimare l’effetto totale dello stress sul rendimento, non dobbiamo controllare per il mediatore. Farlo significherebbe rimuovere proprio il meccanismo causale. Il controllo del mediatore ha senso solo quando l’obiettivo è stimare l’effetto diretto.
21.5.3 Variabili moderatrici
Una variabile moderatrice non è parte della catena causale, ma modifica l’intensità o la direzione dell’effetto del trattamento sull’esito. Risponde alla domanda: per chi o in quali condizioni l’effetto è più forte o più debole?
Esempio (psicologico). Studiamo l’effetto di un intervento di mindfulness sull’ansia. Il livello iniziale di ansia può essere un moderatore:
- nei soggetti con ansia elevata, l’intervento è molto efficace;
- nei soggetti con ansia bassa, l’effetto è ridotto o nullo.
Mindfulness → Ansia
↑
Ansia iniziale
(modera l’effetto)Quando c’è moderazione È appropriato includere termini di interazione nei modelli statistici (ad esempio mindfulness × ansia_iniziale) per verificare se l’effetto varia in funzione del moderatore. Questo permette di capire per chi il trattamento funziona meglio.
21.5.4 Riepilogo concettuale
- Confondimento: distorce l’effetto → va controllato.
- Mediazione: spiega l’effetto → va interpretata, non rimossa (se interessa l’effetto totale).
- Moderazione: specifica quando e per chi l’effetto cambia → va modellata tramite interazioni.
Il grafico seguente riassume visivamente questi tre ruoli distinti delle terze variabili.
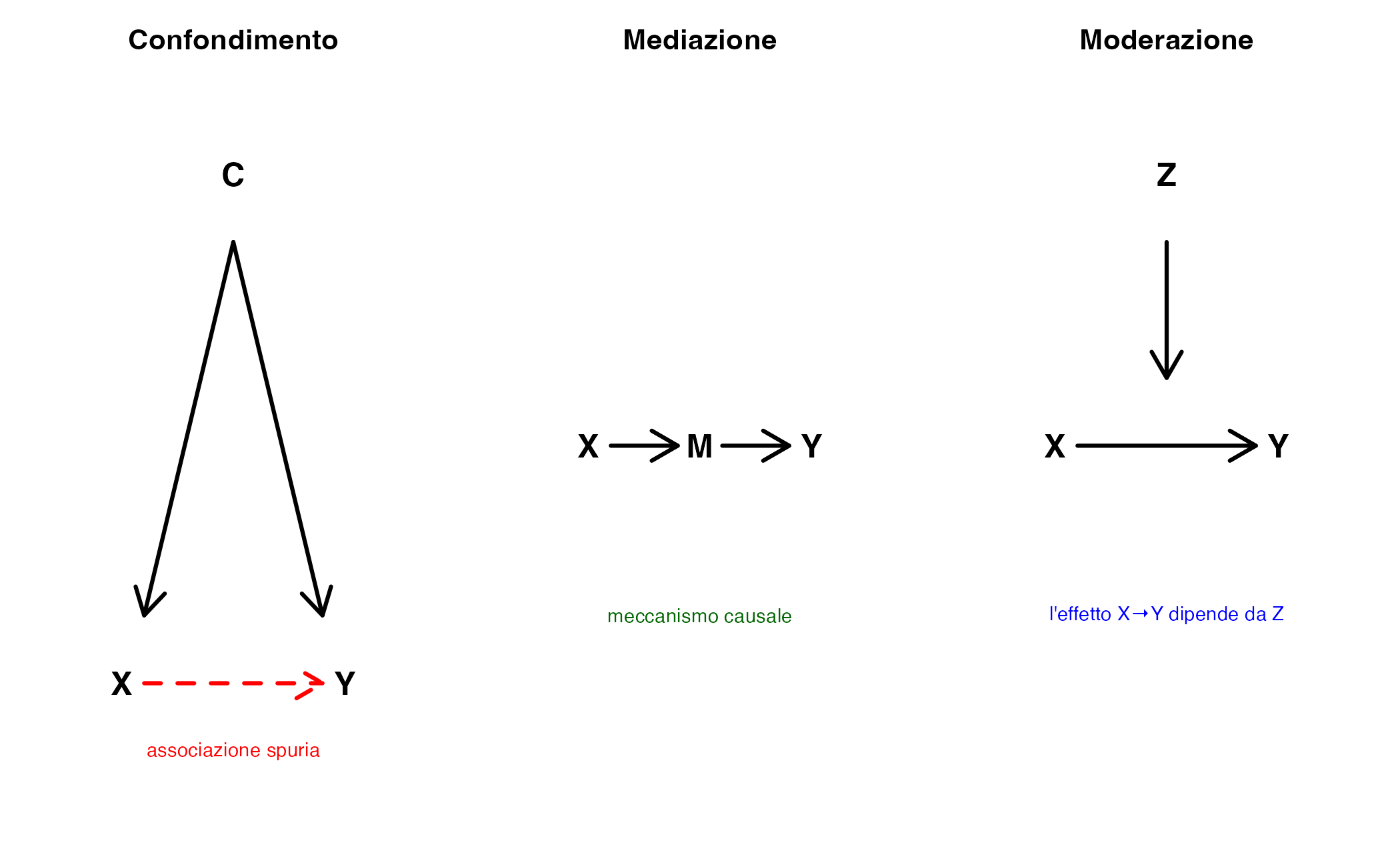
21.5.5 Messaggio chiave
Non tutte le “terze variabili” sono un problema. Il vero errore metodologico non è la loro presenza, ma non riconoscerne il ruolo. Distinguere correttamente tra confondimento, mediazione e moderazione è essenziale per formulare domande causali sensate e per scegliere strategie di analisi coerenti con gli obiettivi della ricerca. Ecco una versione migliorata, più fluida e didatticamente più incisiva, mantenendo l’esempio numerico e il codice invariati ma chiarendo meglio il messaggio causale:
21.6 Un esempio numerico: quando l’associazione inganna
Torniamo ora a un esempio numerico per osservare il confondimento in modo concreto. Immaginiamo di voler stimare se lo studio pomeridiano (\(X\)) migliori il rendimento a un test (\(Y\)). Supponiamo però che esista una terza variabile rilevante: la motivazione (\(U\)).
In particolare, assumiamo che:
- gli studenti più motivati tendano più spesso a studiare nel pomeriggio;
- gli stessi studenti ottengano più frequentemente buoni risultati al test;
- lo studio pomeridiano, di per sé, non abbia alcun effetto causale sul rendimento.
Se ignoriamo la motivazione, il confronto tra chi studia e chi non studia rischia quindi di essere profondamente fuorviante.
21.6.1 Simulazione dei dati
Simuliamo questa situazione in R:
set.seed(123)
n <- 200
motivazione <- rbinom(n, 1, 0.5) # 0 = bassa, 1 = alta
# La motivazione influenza sia lo studio che il rendimento
studio <- rbinom(n, 1, 0.3 + 0.4*motivazione)
rendimento <- rbinom(n, 1, 0.2 + 0.5*motivazione)
# Tabella di contingenza
cat("Tabella studio × rendimento:\n")
#> Tabella studio × rendimento:
print(table(studio, rendimento))
#> rendimento
#> studio 0 1
#> 0 52 43
#> 1 45 60
cat("\n\nProporzioni condizionate (per riga):\n")
#>
#>
#> Proporzioni condizionate (per riga):
print(prop.table(table(studio, rendimento), 1))
#> rendimento
#> studio 0 1
#> 0 0.547 0.453
#> 1 0.429 0.57121.6.2 Interpretazione ingenua
Osservando i dati aggregati, potremmo concludere che:
- tra chi studia nel pomeriggio, circa il 62% supera il test;
- tra chi non studia, solo circa il 29% ottiene un buon risultato.
Una lettura superficiale suggerirebbe che lo studio pomeridiano quasi raddoppia la probabilità di successo.
21.6.3 La vera struttura dei dati
In realtà, in questa simulazione lo studio pomeridiano non ha alcun effetto causale sul rendimento. L’intera associazione osservata è dovuta al fatto che gli studenti più motivati:
- studiano di più;
- performano meglio, indipendentemente dallo studio pomeridiano.
Per verificarlo, analizziamo i dati separatamente per livello di motivazione:
cat("Studenti a BASSA motivazione:\n")
#> Studenti a BASSA motivazione:
low_mot <- motivazione == 0
print(prop.table(table(studio[low_mot], rendimento[low_mot]), 1))
#>
#> 0 1
#> 0 0.652 0.348
#> 1 0.794 0.206
cat("\n\nStudenti ad ALTA motivazione:\n")
#>
#>
#> Studenti ad ALTA motivazione:
high_mot <- motivazione == 1
print(prop.table(table(studio[high_mot], rendimento[high_mot]), 1))
#>
#> 0 1
#> 0 0.269 0.731
#> 1 0.254 0.746All’interno di ciascun livello di motivazione, l’associazione tra studio pomeridiano e rendimento scompare o diventa trascurabile. Questo conferma che la relazione osservata nel campione complessivo era spuria, generata dal confondimento.
Senza controllare per i confondenti, le associazioni osservate possono essere profondamente ingannevoli. Solo stratificando per la motivazione — o includendola esplicitamente in un modello statistico — possiamo distinguere una correlazione spuria da una relazione causale reale.
Questo esempio mostra perché l’inferenza causale non può basarsi su confronti grezzi: capire da dove provengono le differenze tra i gruppi è tanto importante quanto misurare l’associazione stessa.
21.7 Misure di effetto: scale diverse per comunicare i risultati
Quando descriviamo un effetto causale, non esiste un’unica misura “corretta” in assoluto. La scelta della misura dipende dalla domanda di ricerca, dal contesto applicativo e dal pubblico a cui vogliamo comunicare i risultati. Diverse misure mettono in evidenza aspetti diversi dello stesso fenomeno.
Consideriamo un esempio concreto. Supponiamo che, in un esperimento randomizzato:
- tra i trattati, il 20% sviluppi un attacco d’ansia;
- tra i controlli, il 10% sviluppi un attacco d’ansia.
21.7.1 Differenza di rischi (Risk Difference, RD)
La differenza di rischi misura l’effetto in termini assoluti:
\[ \text{RD} = P(Y=1 \mid A=1) - P(Y=1 \mid A=0) = 0.20 - 0.10 = 0.10. \]
Interpretazione. Il trattamento aumenta il rischio di 10 punti percentuali. In altre parole, su 100 persone trattate, ci aspettiamo 10 casi in più rispetto a uno scenario in cui nessuno fosse trattato.
Quando usarla. La RD è particolarmente utile quando interessa valutare l’impatto concreto di un intervento, ad esempio in ambito clinico o di salute pubblica, dove le decisioni dipendono dal numero assoluto di eventi evitati o indotti.
21.7.2 Rapporto di rischi (Risk Ratio, RR)
Il rapporto di rischi esprime l’effetto in termini relativi:
\[ \text{RR} = \frac{P(Y=1 \mid A=1)}{P(Y=1 \mid A=0)} = \frac{0.20}{0.10} = 2.0. \]
Interpretazione. Il rischio di sviluppare un attacco d’ansia è doppio nei trattati rispetto ai controlli.
Quando usarla. La RR è utile quando si vuole enfatizzare quanto il rischio aumenti o diminuisca proporzionalmente. È spesso intuitiva e facilmente comunicabile, ma può risultare fuorviante se non accompagnata da informazioni sul rischio assoluto.
21.7.3 Odds ratio (OR)
L’odds ratio confronta le odds dell’evento nei due gruppi:
\[ \text{OR} = \frac{P(Y=1 \mid A=1) / P(Y=0 \mid A=1)} {P(Y=1 \mid A=0) / P(Y=0 \mid A=0)} = \frac{0.20 / 0.80}{0.10 / 0.90} \approx 2.25. \]
Interpretazione. Le odds di sviluppare un attacco d’ansia sono circa 2.25 volte più alte nei trattati rispetto ai controlli.
Quando usarla. L’OR è la misura naturale nei modelli di regressione logistica. Ha proprietà matematiche convenienti, ma è meno intuitiva: quando gli eventi non sono rari, l’OR tende a sovrastimare l’effetto rispetto al rapporto di rischi.
21.7.4 Confronto tramite simulazione
set.seed(7)
n <- 10000
p1 <- 0.20 # rischio tra trattati
p0 <- 0.10 # rischio tra controlli
A <- rbinom(n, 1, 0.5)
Y <- ifelse(A==1, rbinom(n, 1, p1), rbinom(n, 1, p0))
p_hat1 <- mean(Y[A==1])
p_hat0 <- mean(Y[A==0])
RD <- p_hat1 - p_hat0
RR <- p_hat1 / p_hat0
OR <- (p_hat1/(1-p_hat1)) / (p_hat0/(1-p_hat0))
cat(sprintf("Differenza di rischi (RD) = %.3f\n", RD))
#> Differenza di rischi (RD) = 0.095
cat(sprintf("Rapporto di rischi (RR) = %.2f\n", RR))
#> Rapporto di rischi (RR) = 1.91
cat(sprintf("Odds ratio (OR) = %.2f\n", OR))
#> Odds ratio (OR) = 2.13La simulazione mostra come lo stesso effetto causale possa essere espresso in modi numericamente diversi a seconda della scala scelta.
Non esiste una risposta universale:
- RD è preferibile per comunicare l’impatto assoluto e supportare decisioni pratiche;
- RR è utile per enfatizzare l’aumento o la riduzione relativa del rischio;
- OR è spesso inevitabile nei modelli logistici, ma richiede attenzione interpretativa.
La scelta non è solo tecnica, ma anche comunicativa: l’importante è essere consapevoli della misura utilizzata e dichiararla chiaramente.
Riflessioni conclusive
In questo capitolo abbiamo compiuto un passaggio concettuale fondamentale, passando dalla semplice osservazione delle associazioni alla formulazione di domande causali. I punti chiave possono essere riassunti come segue:
Correlazione ≠ causalità Un’associazione statistica tra due variabili, per quanto robusta, non implica automaticamente un legame causale. Senza considerare la struttura dei dati e le variabili confondenti, l’interpretazione può risultare profondamente fuorviante.
Controfattuali Ragionare in termini causali significa confrontare scenari alternativi: ciò che è accaduto con ciò che sarebbe potuto accadere in assenza del trattamento. Questo confronto, pur non essendo osservabile direttamente a livello individuale, fornisce il fondamento logico dell’inferenza causale.
Confondimento Il confondimento rappresenta il principale ostacolo all’inferenza causale negli studi osservazionali. Le simulazioni hanno mostrato come il confondimento possa generare associazioni spurie, mascherare effetti reali o addirittura invertire il segno delle relazioni osservate.
Randomizzazione La randomizzazione è lo strumento più efficace per affrontare il confondimento, in quanto spezza il legame sistematico tra trattamento e caratteristiche preesistenti. Per questo motivo costituisce il punto di riferimento degli studi sperimentali.
Mediazione e moderazione Non tutte le “terze variabili” sono un problema da eliminare. Alcune spiegano come un effetto si produce (mediazione), altre indicano per chi o in quali condizioni l’effetto cambia (moderazione). Saper distinguere questi ruoli è essenziale per formulare e interpretare correttamente le domande di ricerca.
Nel lavoro empirico, in particolare in psicologia, è difficile fare affidamento esclusivo su esperimenti perfettamente randomizzati. Per questo motivo, l’inferenza causale richiede un approccio esplicito e critico: è necessario identificare i potenziali fattori di confusione, chiarire le ipotesi causali sottostanti e scegliere strumenti statistici coerenti con tali ipotesi.
Questo capitolo ha introdotto le intuizioni concettuali di base. Nei capitoli successivi del manuale principale verranno presentati strumenti più formali per l’inferenza causale, tra cui:
- Grafi aciclici diretti (DAG), per rappresentare e rendere esplicite le ipotesi causali;
- Backdoor criterion, per identificare in modo sistematico quali variabili controllare;
- Metodi per dati osservazionali, come matching, pesatura tramite propensity score e regressione in prospettiva causale;
- Inferenza bayesiana, per quantificare l’incertezza sulle stime causali e integrare informazioni a priori.
Questi strumenti permetteranno di passare dalle intuizioni introdotte qui a un’analisi causale più rigorosa e formalizzata.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] bridgesampling_1.2-1 htmlwidgets_1.6.4 curl_7.0.0
#> [22] pkgbuild_1.4.8 RColorBrewer_1.1-3 abind_1.4-8
#> [25] multcomp_1.4-29 purrr_1.2.1 grid_4.5.2
#> [28] stats4_4.5.2 colorspace_2.1-2 xtable_1.8-4
#> [31] inline_0.3.21 emmeans_2.0.1 scales_1.4.0
#> [34] MASS_7.3-65 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 otel_0.2.0
#> [40] RcppParallel_5.1.11-1 cachem_1.1.0 stringr_1.6.0
#> [43] splines_4.5.2 parallel_4.5.2 vctrs_0.6.5
#> [46] V8_8.0.1 Matrix_1.7-4 sandwich_3.1-1
#> [49] jsonlite_2.0.0 arrayhelpers_1.1-0 glue_1.8.0
#> [52] codetools_0.2-20 distributional_0.5.0 lubridate_1.9.4
#> [55] stringi_1.8.7 gtable_0.3.6 QuickJSR_1.8.1
#> [58] pillar_1.11.1 htmltools_0.5.9 Brobdingnag_1.2-9
#> [61] R6_2.6.1 textshaping_1.0.4 rprojroot_2.1.1
#> [64] evaluate_1.0.5 lattice_0.22-7 backports_1.5.0
#> [67] memoise_2.0.1 broom_1.0.11 snakecase_0.11.1
#> [70] rstantools_2.5.0 gridExtra_2.3 coda_0.19-4.1
#> [73] nlme_3.1-168 checkmate_2.3.3 xfun_0.55
#> [76] zoo_1.8-15 pkgconfig_2.0.3