here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(ggbeeswarm, dslabs, gridExtra, patchwork) 19 Introduzione alla distribuzione normale
Panoramica del capitolo
- Perché la distribuzione normale è importante in psicologia: collegamenti con test, questionari e fenomeni naturali.
- Proprietà visive fondamentali: la regola empirica 68-95-99.7 e il suo significato pratico.
- Z-scores e standardizzazione: come confrontare valori su scale diverse.
- Verifica della normalità: QQ-plots come strumento diagnostico.
- Ponte verso l’inferenza: come la normale prepara ai concetti inferenziali.
ConsiglioPrerequisiti
- Leggere il capitolo Exploring numerical data di Introduction to Modern Statistics (2e) di Mine Çetinkaya-Rundel e Johanna Hardin.
- Leggere il capitolo Distributions di Introduction to Data Science (Irizarry, 2024).
AttenzionePreparazione del Notebook
19.1 Perché la distribuzione normale è fondamentale in psicologia
Prima di analizzarne le proprietà matematiche, è importante comprendere perché la distribuzione normale occupi una posizione centrale nella ricerca psicologica, in particolare nell’ambito della psicometria e della valutazione standardizzata.
19.1.1 La distribuzione normale nella psicometria
Gran parte dei test psicologici standardizzati è progettata in modo tale che i punteggi, all’interno della popolazione di riferimento, seguano approssimativamente una distribuzione normale. Questa scelta non è casuale, ma risponde a precise esigenze teoriche e pratiche.
Esempi rilevanti includono:
- Test di intelligenza (QI), calibrati per avere una media pari a 100 e una deviazione standard di 15, così da facilitare il confronto tra individui e gruppi;
- Misure di personalità, come le dimensioni del modello dei Big Five, che in popolazioni non cliniche tendono a distribuirsi in modo simmetrico intorno a un valore centrale;
- Questionari clinici, quali il Beck Depression Inventory (BDI) o lo State-Trait Anxiety Inventory (STAI), ampiamente utilizzati per la valutazione dei sintomi affettivi;
- Batterie neuropsicologiche, impiegate per misurare funzioni cognitive come memoria, attenzione e funzioni esecutive, spesso normalizzate su campioni rappresentativi.
In tutti questi casi, l’assunzione di normalità consente di interpretare i punteggi individuali in termini relativi, collocandoli rispetto alla popolazione di riferimento mediante percentili, punteggi \(z\) o punteggi standardizzati. Questo rende possibile un confronto informativo e clinicamente rilevante tra soggetti, contesti e momenti di valutazione diversi.
# Simuliamo la distribuzione del QI
qi_data <- data.frame(
QI = seq(55, 145, length.out = 1000)
) |>
mutate(densita = dnorm(QI, mean = 100, sd = 15))
ggplot(qi_data, aes(x = QI, y = densita)) +
geom_line(linewidth = 1.2, color = "darkblue") +
geom_area(fill = "lightblue", alpha = 0.5) +
geom_vline(xintercept = 100, linetype = "dashed", color = "red") +
annotate("text", x = 100, y = 0.02, label = "Media = 100",
vjust = -0.5, color = "red") +
labs(title = "Distribuzione dei punteggi di QI",
subtitle = "Media = 100, Deviazione Standard = 15",
x = "Punteggio QI",
y = "Densità") 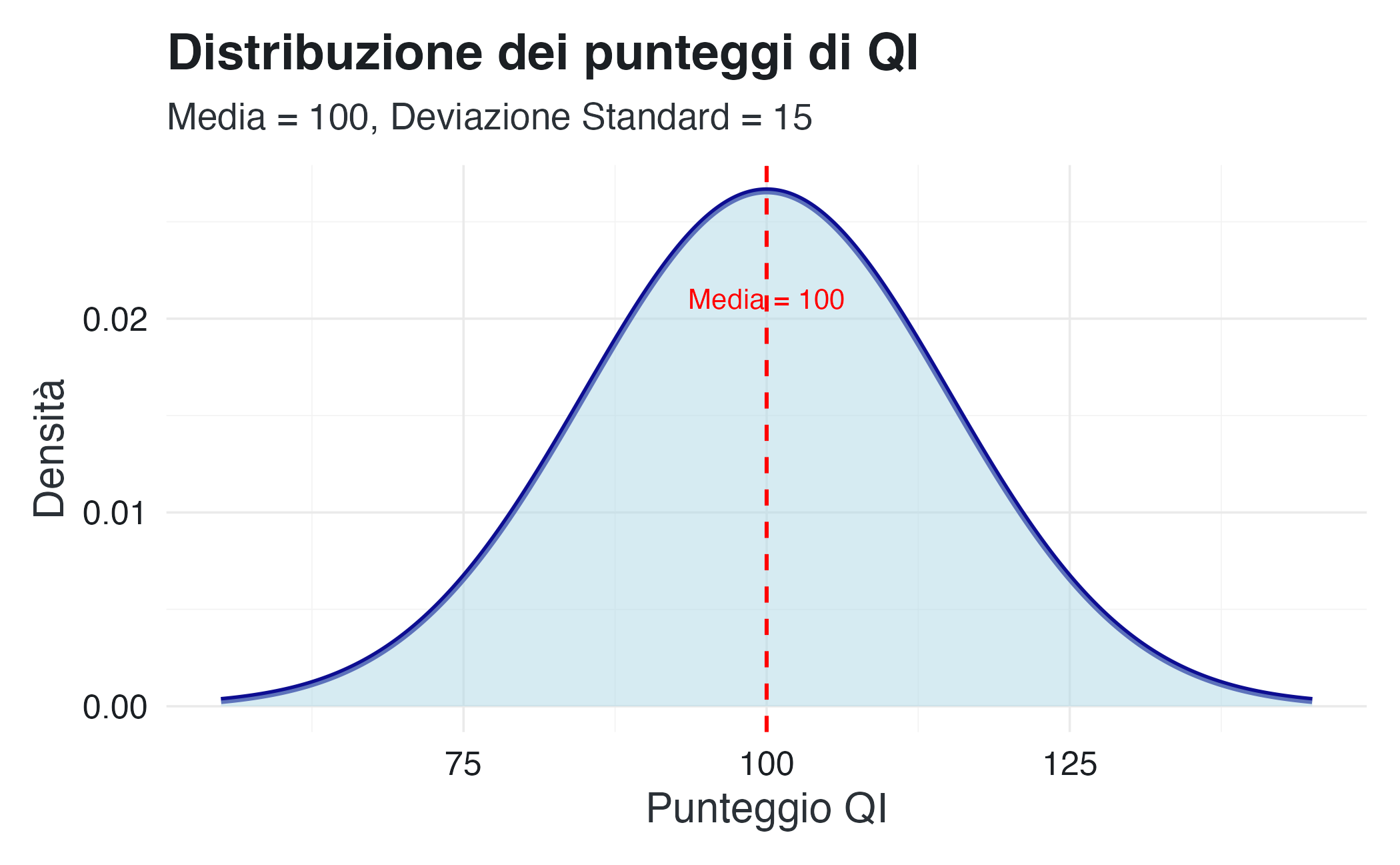
19.1.2 Fenomeni naturali e biologici
Numerose variabili biologiche e comportamentali mostrano una distribuzione approssimativamente normale quando osservate in popolazioni sufficientemente ampie. Tra gli esempi più comuni rientrano:
- Misure antropometriche, come altezza, peso o circonferenza cranica;
- Tempi di reazione, in particolare in compiti cognitivi semplici e ben controllati;
- Errori di misurazione, tipici degli esperimenti di laboratorio;
- Variabilità interindividuale in molti processi psicologici di base, quali velocità di elaborazione, attenzione o memoria di lavoro.
Questa regolarità non è casuale. Quando una variabile osservata è il risultato dell’azione combinata di numerosi fattori in larga parte indipendenti — genetici, ambientali e casuali — ciascuno dei quali contribuisce con un effetto relativamente piccolo, la distribuzione complessiva tende a convergere verso la forma normale. Questo principio, formalizzato nel Teorema del Limite Centrale, rappresenta uno dei pilastri teorici della statistica moderna e costituisce il fondamento di molte tecniche di inferenza utilizzate in psicologia.
19.1.3 La distribuzione normale come modello fondamentale nella modellazione bayesiana
Anche nell’ambito dell’inferenza bayesiana, la distribuzione normale occupa una posizione centrale, sebbene con ruoli e interpretazioni in parte differenti rispetto all’approccio frequentista. La sua importanza deriva sia da considerazioni matematiche sia da esigenze di modellazione pratica.
In particolare:
- Priors e likelihood: la distribuzione normale è spesso impiegata come prior coniugato per molti parametri di interesse e come likelihood per dati continui. Questa scelta consente, in numerosi casi, di ottenere posteriori in forma chiusa o comunque facilmente trattabili dal punto di vista analitico.
- Regolarizzazione bayesiana: l’uso di prior normali (ad esempio nella regressione ridge bayesiana) introduce una forma naturale di regolarizzazione, che riduce la varianza delle stime e contribuisce a prevenire il sovradattamento.
- Modelli gerarchici: la distribuzione normale è fondamentale per modellare la variabilità tra gruppi attraverso effetti casuali, costituendo il nucleo di molte strutture gerarchiche e multilevel.
- Approssimazioni della distribuzione a posteriori: numerosi metodi di inferenza approssimata, come la Laplace approximation o la Variational Bayes, assumono che la distribuzione a posteriori sia ben approssimabile da una normale, sfruttandone le proprietà di concentrazione e simmetria.
Comprendere a fondo le proprietà della distribuzione normale è quindi essenziale per costruire modelli bayesiani robusti, interpretare correttamente i prior coniugati e implementare algoritmi di inferenza efficienti. Nel contesto bayesiano, la normale non rappresenta tanto un’“assunzione da verificare”, quanto piuttosto una scelta di modellazione flessibile e matematicamente conveniente, da adottare consapevolmente in funzione del problema di ricerca.
ImportanteLa normale come modello, non come legge assoluta
È cruciale ricordare che i dati reali raramente seguono perfettamente una distribuzione normale. La distribuzione normale rappresenta un modello matematico che approssima in modo utile molti fenomeni reali. L’obiettivo non è quindi trovare dati “perfettamente normali”, ma valutare se l’approssimazione normale è sufficientemente buona per gli scopi specifici della nostra analisi.
19.2 La distribuzione normale: definizione e proprietà
La distribuzione normale, detta anche distribuzione gaussiana o curva a campana, è una distribuzione di probabilità continua caratterizzata da una forma unimodale, perfettamente simmetrica e definita su tutto l’insieme dei numeri reali. Essa riveste un ruolo centrale nella statistica teorica e applicata, nonché nelle scienze psicologiche e comportamentali.
La distribuzione normale è completamente determinata da due parametri:
- \(\mu\) (mu): la media della distribuzione, che ne individua il centro e coincide con il valore di massima densità;
- \(\sigma\) (sigma): la deviazione standard, che misura la dispersione dei valori intorno alla media e controlla l’ampiezza della distribuzione.
Questi due parametri sono sufficienti a descrivere sia la posizione sia la variabilità della distribuzione, rendendo la normale un modello matematico particolarmente semplice e al tempo stesso estremamente versatile.
19.2.1 Rappresentazione visiva
Ecco come appare la distribuzione normale con diversi valori di \(\mu\) e \(\sigma\):
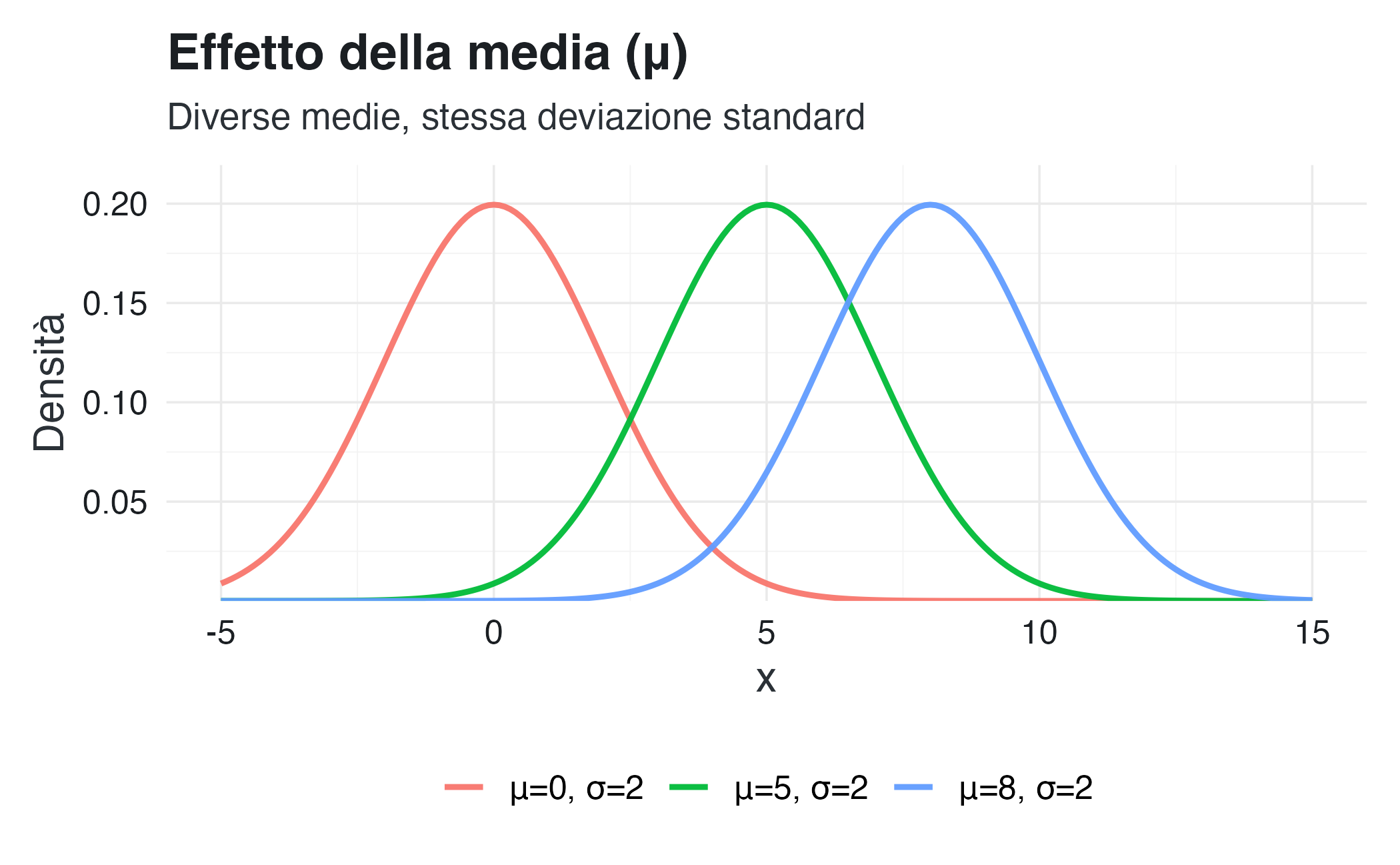
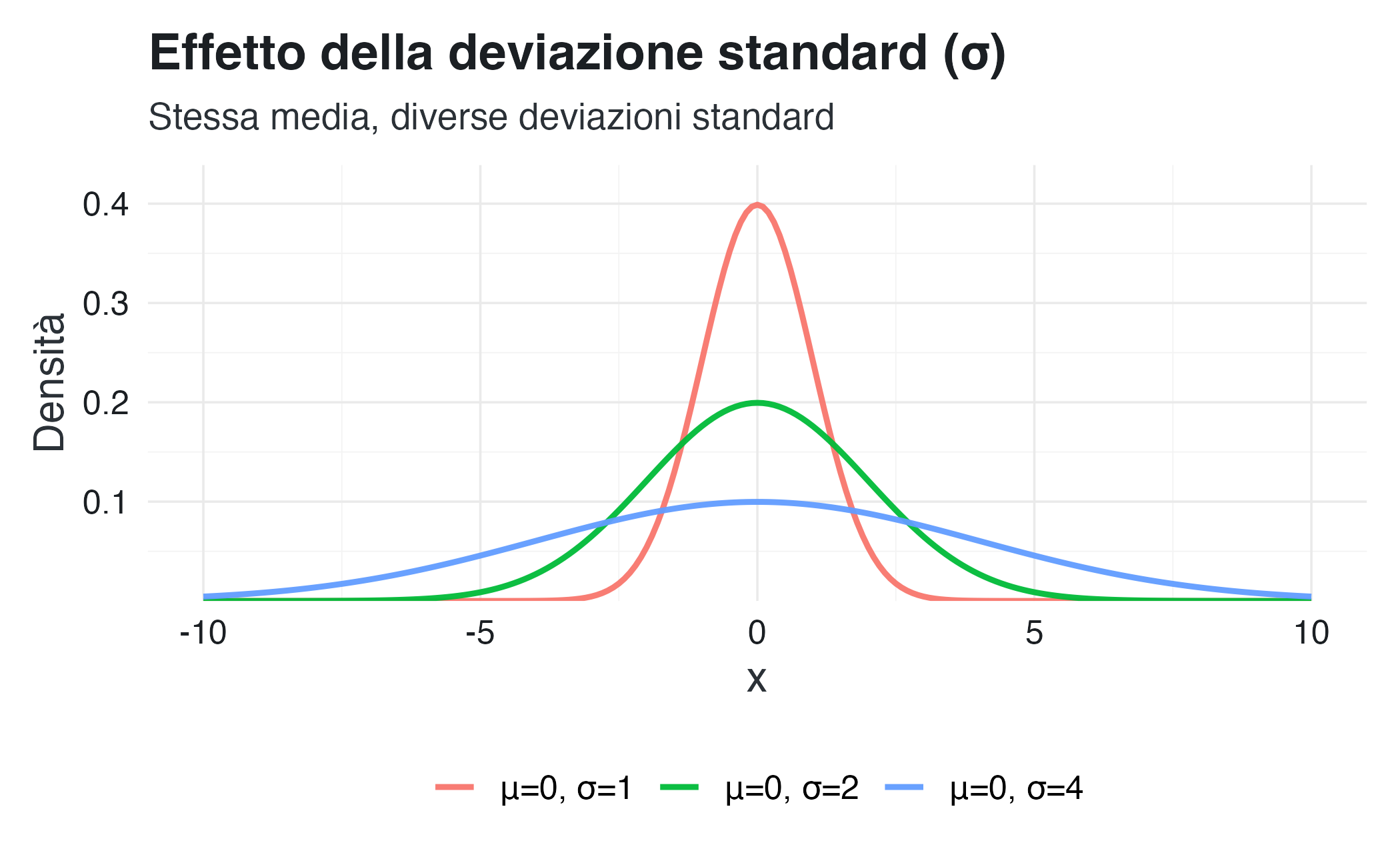
Come si può osservare:
- la media \(\mu\) sposta la curva a destra o a sinistra lungo l’asse \(x\);
-
la deviazione standard \(\sigma\) controlla quanto la curva è “allargata”:
- \(\sigma\) piccolo → curva alta e stretta (dati concentrati vicino alla media)
- \(\sigma\) grande → curva bassa e larga (dati più dispersi).
19.2.2 Proprietà fondamentali
La distribuzione normale presenta alcune proprietà strutturali fondamentali che ne definiscono il comportamento e ne giustificano l’uso diffuso come modello di riferimento:
- Simmetria: la distribuzione è perfettamente simmetrica rispetto alla media \(\mu\); per ogni valore a distanza \(d\) dalla media esiste un valore equiprobabile a distanza \(-d\).
- Unimodalità: la distribuzione presenta un unico massimo (moda), che coincide con il punto di massima densità.
- Asintoticità: le code della distribuzione si estendono indefinitamente verso \(+\infty\) e \(-\infty\) senza mai intersecare l’asse delle ascisse.
- Coincidenza degli indici di posizione: in una distribuzione normale, media, mediana e moda coincidono, riflettendo l’equilibrio perfetto della distribuzione.
Queste proprietà rendono la distribuzione normale un riferimento ideale per descrivere fenomeni continui caratterizzati da variabilità simmetrica attorno a un valore centrale.
NotaNota matematica
La forma precisa della distribuzione normale è definita da una funzione matematica (la funzione di densità) che coinvolge \(\mu\), \(\sigma\), e alcune costanti matematiche (π, e). I dettagli di questa funzione e le sue proprietà formali saranno approfonditi nel companion sulla teoria della probabilità. Per ora, è sufficiente sapere che \(\mu\) e \(\sigma\) determinano completamente la forma della distribuzione.
19.3 La regola empirica 68–95–99.7
Una delle proprietà più note e utili della distribuzione normale è la regola empirica (o regola 68–95–99.7), che fornisce una descrizione intuitiva di come i valori si distribuiscono attorno alla media in funzione della deviazione standard.
Questa regola permette di comprendere rapidamente quanta parte dei dati ci si aspetta di osservare vicino al valore centrale, senza ricorrere a calcoli complessi o a tabelle di probabilità.
19.3.1 La regola in numeri
Per qualsiasi distribuzione normale, indipendentemente dai valori specifici della media \(\mu\) e della deviazione standard \(\sigma\):
- circa il 68% delle osservazioni ricade entro una deviazione standard dalla media, nell’intervallo \([\mu - \sigma, \mu + \sigma]\);
- circa il 95% delle osservazioni si trova entro due deviazioni standard dalla media, nell’intervallo \([\mu - 2\sigma, \mu + 2\sigma]\);
- circa il 99.7% delle osservazioni cade entro tre deviazioni standard dalla media, nell’intervallo \([\mu - 3\sigma, \mu + 3\sigma]\).
Queste proporzioni forniscono una guida pratica per interpretare la variabilità dei dati e per valutare quanto un’osservazione sia tipica o estrema rispetto alla distribuzione di riferimento.
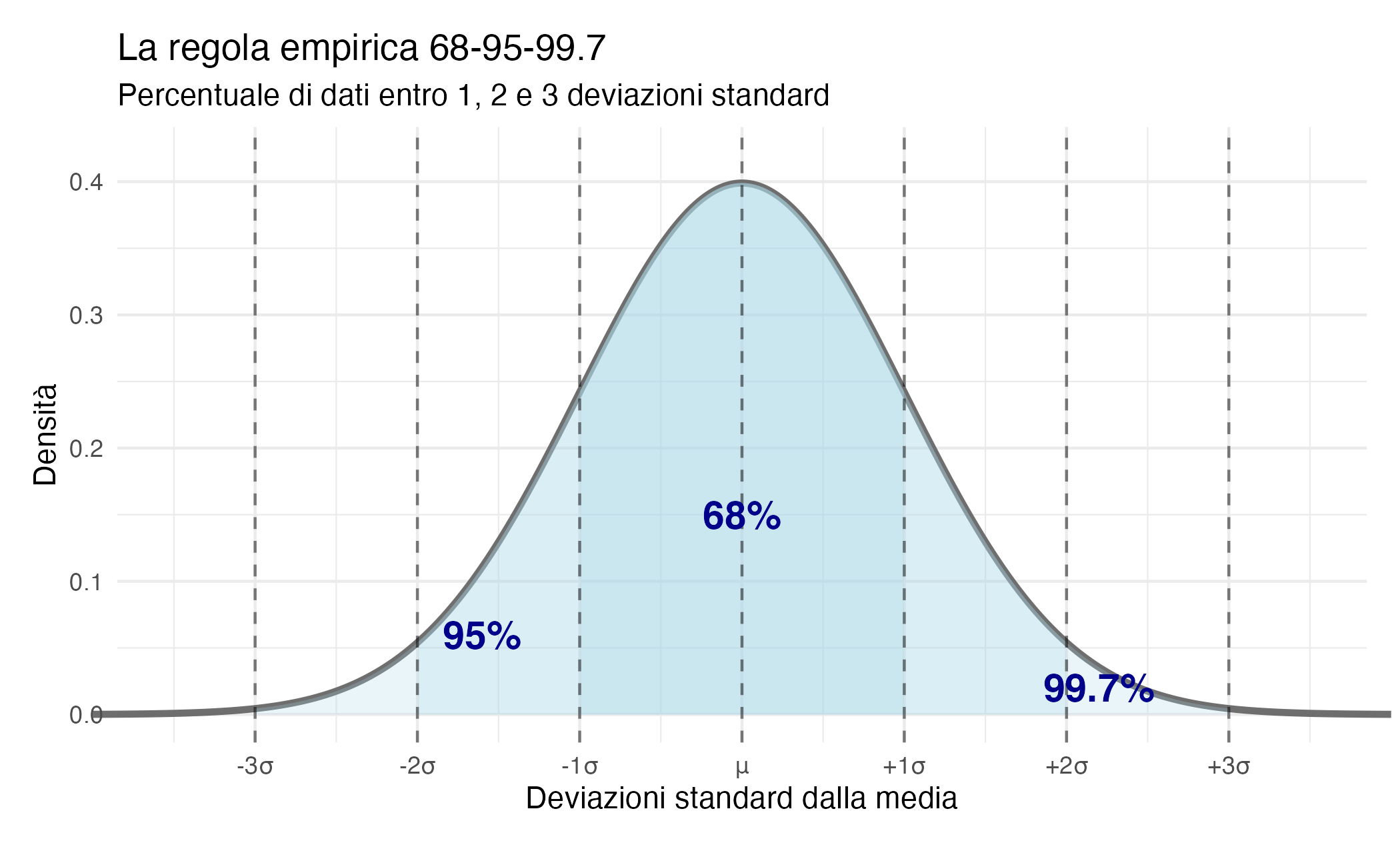
19.3.2 Applicazione pratica: Test del QI
Riprendiamo l’esempio dei punteggi di QI (media = 100, deviazione standard = 15). Applicando la regola empirica otteniamo:
| Intervallo | Limiti | Percentuale | Interpretazione |
|---|---|---|---|
| μ ± 1σ | 85 - 115 | 68% | La maggior parte delle persone |
| μ ± 2σ | 70 - 130 | 95% | Quasi tutte le persone |
| μ ± 3σ | 55 - 145 | 99.7% | Praticamente tutta la popolazione |
Questo significa che:
- circa il 68% della popolazione ha un QI tra 85 e 115;
- circa il 95% della popolazione ha un QI tra 70 e 130;
- solo circa il 2.5% ha un QI superiore a 130 (superdotati);
- solo circa il 2.5% ha un QI inferiore a 70 (difficoltà cognitive).
19.3.3 Verifica empirica con dati reali
Vediamo se la regola empirica si applica effettivamente a un dataset reale. Useremo ancora le altezze maschili dal dataset heights:
# Estraiamo le altezze maschili
index <- dslabs::heights$sex == "Male"
x <- dslabs::heights$height[index]
# Calcoliamo media e deviazione standard
m <- mean(x)
s <- sd(x)
cat("Media:", round(m, 2), "cm\n")
#> Media: 69.3 cm
cat("Deviazione standard:", round(s, 2), "cm\n\n")
#> Deviazione standard: 3.61 cm
# Verifichiamo la regola empirica
prop_1sd <- mean(abs(x - m) <= 1*s)
prop_2sd <- mean(abs(x - m) <= 2*s)
prop_3sd <- mean(abs(x - m) <= 3*s)
risultati_empirici <- data.frame(
Intervallo = c("μ ± 1σ", "μ ± 2σ", "μ ± 3σ"),
Teorico = c("68%", "95%", "99.7%"),
Osservato = paste0(round(c(prop_1sd, prop_2sd, prop_3sd) * 100, 1), "%")
)
knitr::kable(risultati_empirici,
caption = "Confronto tra proporzioni teoriche e osservate")| Intervallo | Teorico | Osservato |
|---|---|---|
| μ ± 1σ | 68% | 76% |
| μ ± 2σ | 95% | 95% |
| μ ± 3σ | 99.7% | 99.1% |
Come si può vedere, le proporzioni osservate sono molto vicine a quelle teoriche, confermando che l’altezza maschile segue approssimativamente una distribuzione normale.
ConsiglioImplicazione pratica
La regola empirica consente di attribuire un significato immediato alla deviazione standard: essa rappresenta, in modo approssimato, la distanza dalla media entro cui si colloca circa il 68% delle osservazioni. In questo modo, un parametro che appare inizialmente astratto nella sua formulazione matematica acquisisce un’interpretazione concreta e intuitiva, rendendo la deviazione standard uno strumento descrittivo molto più informativo di quanto possa sembrare a prima vista.
19.4 Un esempio pratico completo: altezza maschile
Integriamo i concetti presentati finora con un esempio pratico. Consideriamo il problema di descrivere la distribuzione delle altezze nella popolazione maschile adulta, modellizzabile tramite una distribuzione normale.
19.4.1 Stima dei parametri
Estraiamo i dati e calcoliamo media e deviazione standard:
Avviso
Nota tecnica: La funzione sd(x) effettua una divisione per \(n - 1\) invece che per \(n\) (dove \(n\) è il numero di osservazioni). Questa correzione, chiamata correzione di Bessel, serve per ottenere una stima non distorta della deviazione standard della popolazione. Quando il numero di osservazioni è elevato, la differenza tra dividere per \(n\) o per \(n-1\) è trascurabile. Approfondiremo questo aspetto quando studieremo la stima dei parametri.
19.4.2 Confronto visivo
Possiamo ora confrontare la distribuzione osservata (in blu) con la distribuzione normale teorica (in nero):
norm_dist <- tibble(
x = seq(m - 4*s, m + 4*s, length.out = 100)) |>
mutate(density = dnorm(x, m, s))
dslabs::heights |>
dplyr::filter(sex == "Male") |>
ggplot(aes(height)) +
geom_density(fill = "lightblue", alpha = 0.7) +
geom_line(aes(x, density), linewidth = 1.5,
data = norm_dist, color = "black") +
labs(title = "Distribuzione delle altezze maschili",
subtitle = "Densità osservata (blu) vs. normale teorica (nero)",
x = "Altezza (cm)",
y = "Densità") 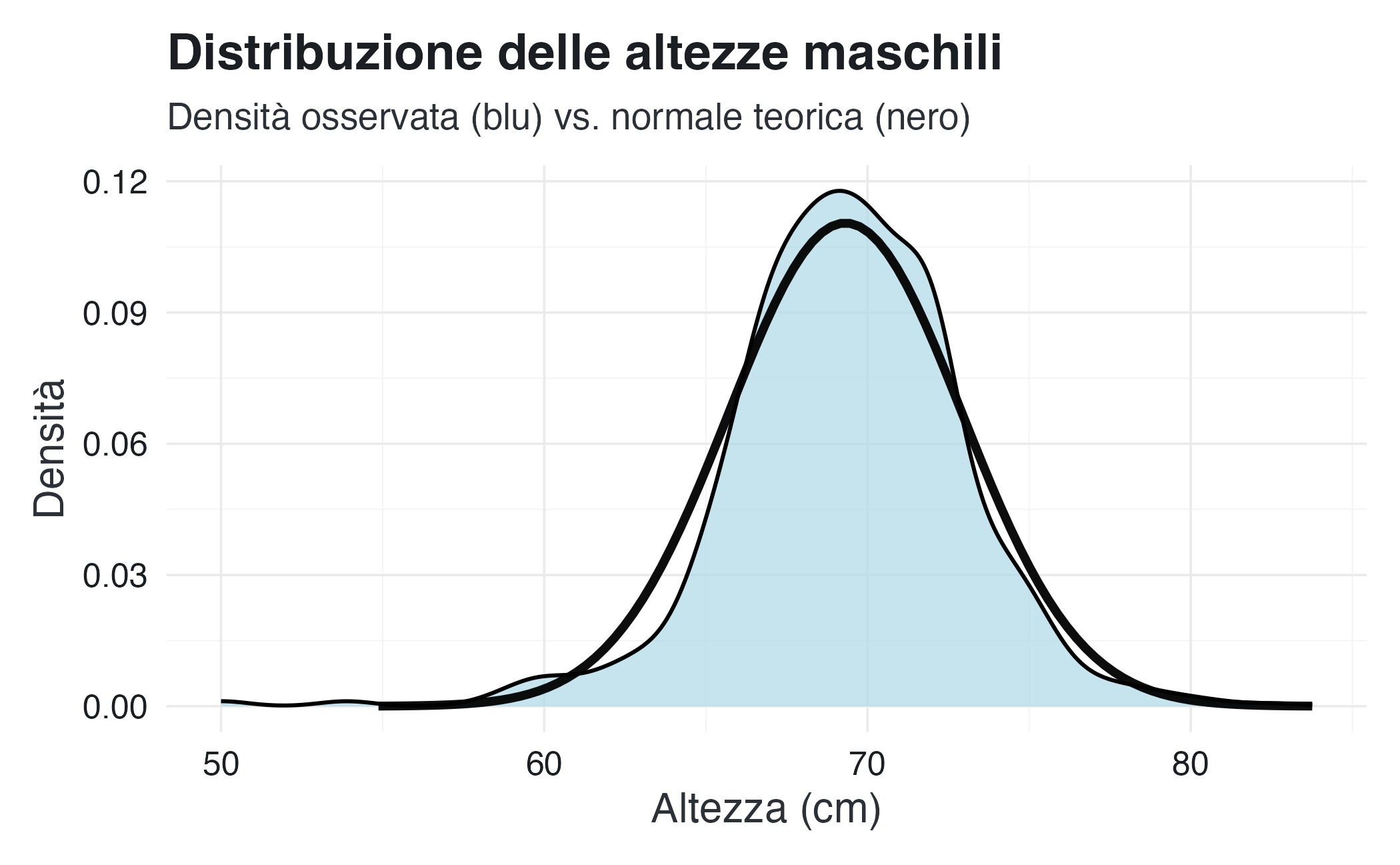
La curva normale fornisce una buona approssimazione. Questo significa che possiamo descrivere efficacemente la distribuzione usando solo due numeri: media (69.3 cm) e deviazione standard (3.6 cm).
19.5 Z-scores: standardizzazione e confronti
Quando si analizzano variabili misurate su scale diverse — ad esempio altezza in centimetri e peso in chilogrammi, oppure punteggi provenienti da test differenti — il confronto diretto dei valori grezzi risulta poco informativo o addirittura fuorviante. I punteggi standardizzati, comunemente noti come z-scores, forniscono una soluzione elegante a questo problema, consentendo di esprimere i dati su una scala comune.
19.5.1 Definizione e calcolo
Uno z-score indica di quante deviazioni standard un valore osservato si discosta dalla media della distribuzione di riferimento. Formalmente:
\[ z = \frac{x - \mu}{\sigma}, \] dove:
- \(x\) è il valore osservato;
- \(\mu\) è la media della distribuzione;
- \(\sigma\) è la deviazione standard.
Attraverso questa trasformazione, ogni osservazione viene ricollocata rispetto al centro e alla dispersione della distribuzione, rendendo i valori direttamente confrontabili.
In R, gli z-scores possono essere calcolati in modo semplice utilizzando la funzione scale():
# Z-scores delle altezze maschili
z <- scale(x) |> as.numeric()
cat("Primi 10 z-scores:\n")
#> Primi 10 z-scores:
head(z, 10) |> round(2)
#> [1] 1.57 0.19 -0.36 1.30 -2.30 -0.64 0.74 0.74 -0.09 -0.36
# Verifichiamo le proprietà
cat("\nMedia degli z-scores:", round(mean(z), 10), "\n")
#>
#> Media degli z-scores: 0
cat("Deviazione standard degli z-scores:", round(sd(z), 10), "\n")
#> Deviazione standard degli z-scores: 119.5.2 Proprietà fondamentali degli z-scores
La standardizzazione presenta alcune proprietà chiave:
- la media degli z-scores è sempre pari a 0;
- la deviazione standard degli z-scores è sempre pari a 1;
- la trasformazione preserva la forma della distribuzione originale, limitandosi a ricentrarla e riscalarla.
Queste caratteristiche rendono gli z-scores particolarmente utili per confronti trasversali tra variabili diverse e per l’interpretazione relativa delle osservazioni.
19.5.3 Interpretazione pratica
Nel contesto di una distribuzione approssimativamente normale, gli z-scores possono essere interpretati in modo immediato:
- z = 0: il valore coincide con la media;
- z = 1: il valore è una deviazione standard sopra la media;
- z = -1: il valore è una deviazione standard sotto la media;
- z = 2: il valore è due deviazioni standard sopra la media (circa nel 2.5% superiore della distribuzione);
- z = -2: il valore è due deviazioni standard sotto la media (circa nel 2.5% inferiore della distribuzione).
In questo modo, gli z-scores permettono di tradurre valori grezzi in posizioni relative all’interno della distribuzione, facilitando l’interpretazione e il confronto tra individui, variabili e contesti di misurazione diversi.
19.5.4 Esempio: confronto tra test diversi
Supponiamo che uno studente abbia ottenuto i seguenti risultati:
- QI = 115, in un test con media di popolazione pari a 100 e deviazione standard di 15;
- Punteggio di memoria = 65, in un test con media pari a 50 e deviazione standard di 10.
La domanda è: in quale dei due test lo studente ha performato meglio in termini relativi rispetto alla popolazione di riferimento?
Per rispondere, trasformiamo entrambi i punteggi in z-scores:
# Calcolo degli z-scores
z_qi <- (115 - 100) / 15
z_memoria <- (65 - 50) / 10
cat("Z-score QI:", round(z_qi, 2), "\n")
#> Z-score QI: 1
cat("Z-score Memoria:", round(z_memoria, 2), "\n")
#> Z-score Memoria: 1.5
if (z_memoria > z_qi) {
cat("\nLo studente ha performato relativamente meglio nel test di memoria\n")
} else {
cat("\nLo studente ha performato relativamente meglio nel test di QI\n")
}
#>
#> Lo studente ha performato relativamente meglio nel test di memoriaIl punteggio di QI corrisponde a uno z-score pari a 1.00, mentre il punteggio nel test di memoria corrisponde a uno z-score pari a 1.50.
Sebbene i valori grezzi (115 e 65) non siano direttamente confrontabili a causa delle diverse scale di misura, gli z-scores consentono di esprimere entrambe le prestazioni sulla stessa scala standardizzata. In questo caso, lo studente ha ottenuto una performance relativamente migliore nel test di memoria, collocandosi più lontano dalla media della popolazione di riferimento.
19.5.5 La distribuzione normale standard
Quando si standardizza una variabile che segue una distribuzione normale con media \(\mu\) e deviazione standard \(\sigma\), i corrispondenti z-scores seguono una distribuzione normale standard, caratterizzata da media pari a 0 e deviazione standard pari a 1. Questa distribuzione viene indicata come \(N(0, 1)\) oppure, più sinteticamente, come \(Z\).
La standardizzazione non altera la forma della distribuzione: essa si limita a ricentrare i dati sulla media zero e a riscalarli in unità di deviazione standard. In questo modo, qualsiasi distribuzione normale può essere ricondotta a un’unica distribuzione di riferimento, rendendo possibili confronti diretti e calcoli probabilistici uniformi.
La figura seguente illustra visivamente questo processo, mostrando una distribuzione normale originale e la corrispondente distribuzione dopo la standardizzazione.
# Dati originali e standardizzati
plot_data <- data.frame(
originale = x,
standardizzato = z
)
p1 <- ggplot(plot_data, aes(x = originale)) +
geom_histogram(aes(y = after_stat(density)), bins = 30,
fill = "lightblue", alpha = 0.7) +
stat_function(fun = dnorm, args = list(mean = m, sd = s),
linewidth = 1, color = "black") +
labs(title = "Distribuzione originale",
subtitle = paste0("μ = ", round(m, 1), ", σ = ", round(s, 1)),
x = "Altezza (cm)", y = "Densità") +
theme(plot.margin = margin(t = 12, r = 5, b = 5, l = 5))
p2 <- ggplot(plot_data, aes(x = standardizzato)) +
geom_histogram(aes(y = after_stat(density)), bins = 30,
fill = "lightgreen", alpha = 0.7) +
stat_function(fun = dnorm, args = list(mean = 0, sd = 1),
linewidth = 1, color = "black") +
labs(title = "Dopo standardizzazione",
subtitle = "μ = 0, σ = 1",
x = "Z-score", y = "Densità") +
theme(plot.margin = margin(t = 12, r = 5, b = 5, l = 5))
grid.arrange(p1, p2, ncol = 2)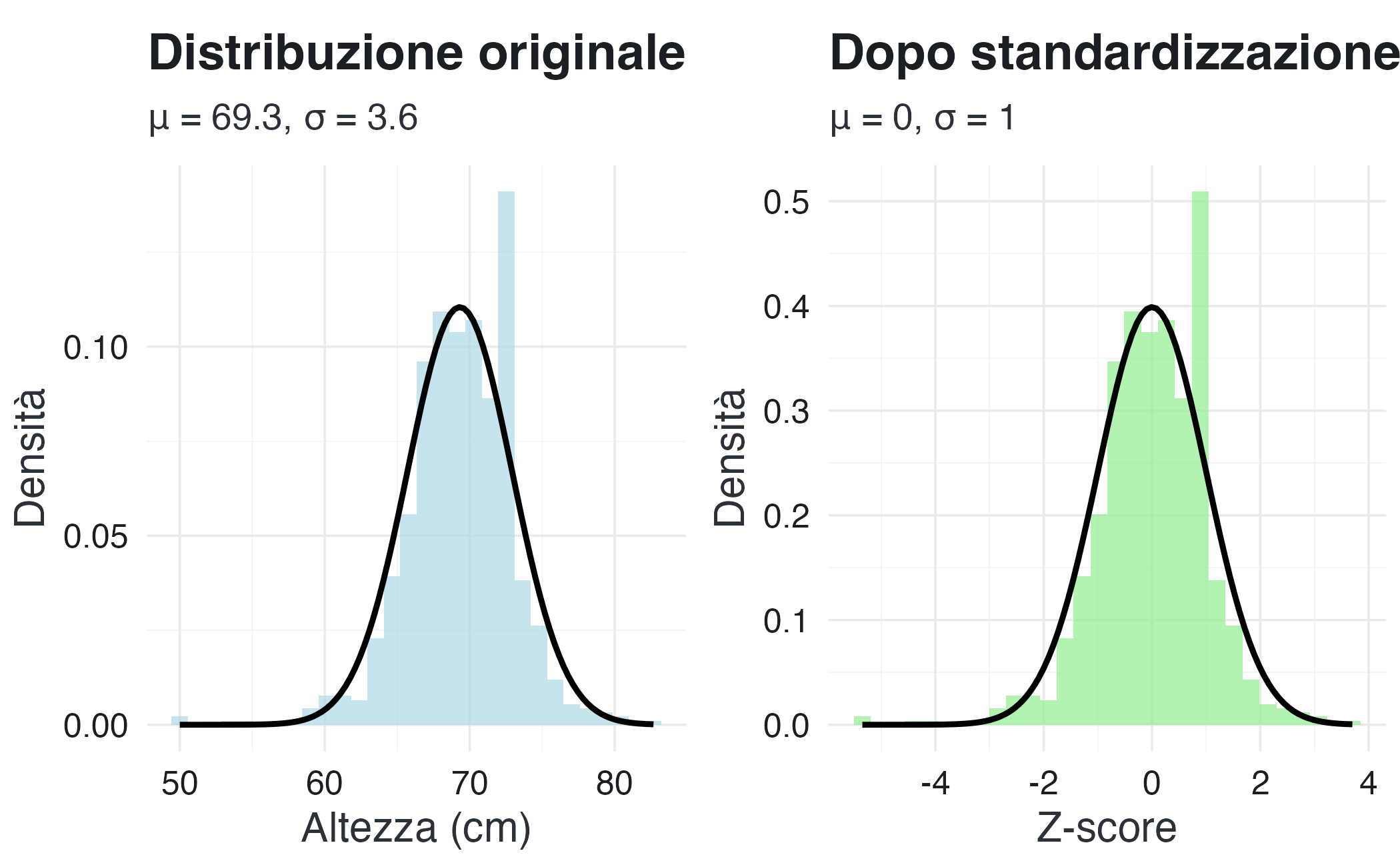
ImportanteCollegamento con l’inferenza statistica
Gli z-scores costituiscono un elemento fondamentale dell’inferenza statistica:
- i test z utilizzano direttamente la distribuzione normale standard per il calcolo delle probabilità;
- i valori-\(p\) sono spesso ottenuti convertendo una statistica test in uno z-score;
- gli intervalli di confidenza si basano sulla distribuzione degli z-scores e sui relativi quantili.
Una comprensione solida della distribuzione normale standard e degli z-scores fornisce quindi le basi concettuali necessarie per affrontare con maggiore consapevolezza i metodi inferenziali che verranno introdotti nei capitoli successivi.
19.6 Verificare la normalità: QQ-plots
Un metodo sistematico per valutare se i dati seguono approssimativamente una distribuzione normale è il QQ-plot (Quantile-Quantile plot), che confronta i quantili empirici dei dati con i quantili teorici di una distribuzione normale di riferimento.
19.6.1 Principio di funzionamento del QQ-plot
Il QQ-plot si costruisce seguendo questi passaggi:
- si ordinano i dati in senso crescente;
- per ogni osservazione, si calcola la sua posizione percentile empirica;
- si determinano i corrispondenti quantili teorici di una distribuzione normale standard;
- si rappresentano in un grafico i punti (quantile teorico, quantile osservato).
Se i dati seguono una distribuzione normale, i punti si disporranno approssimativamente lungo una retta diagonale.
19.6.2 Creazione di un QQ-plot in R
Con ggplot2, un QQ-plot può essere generato nel modo seguente:
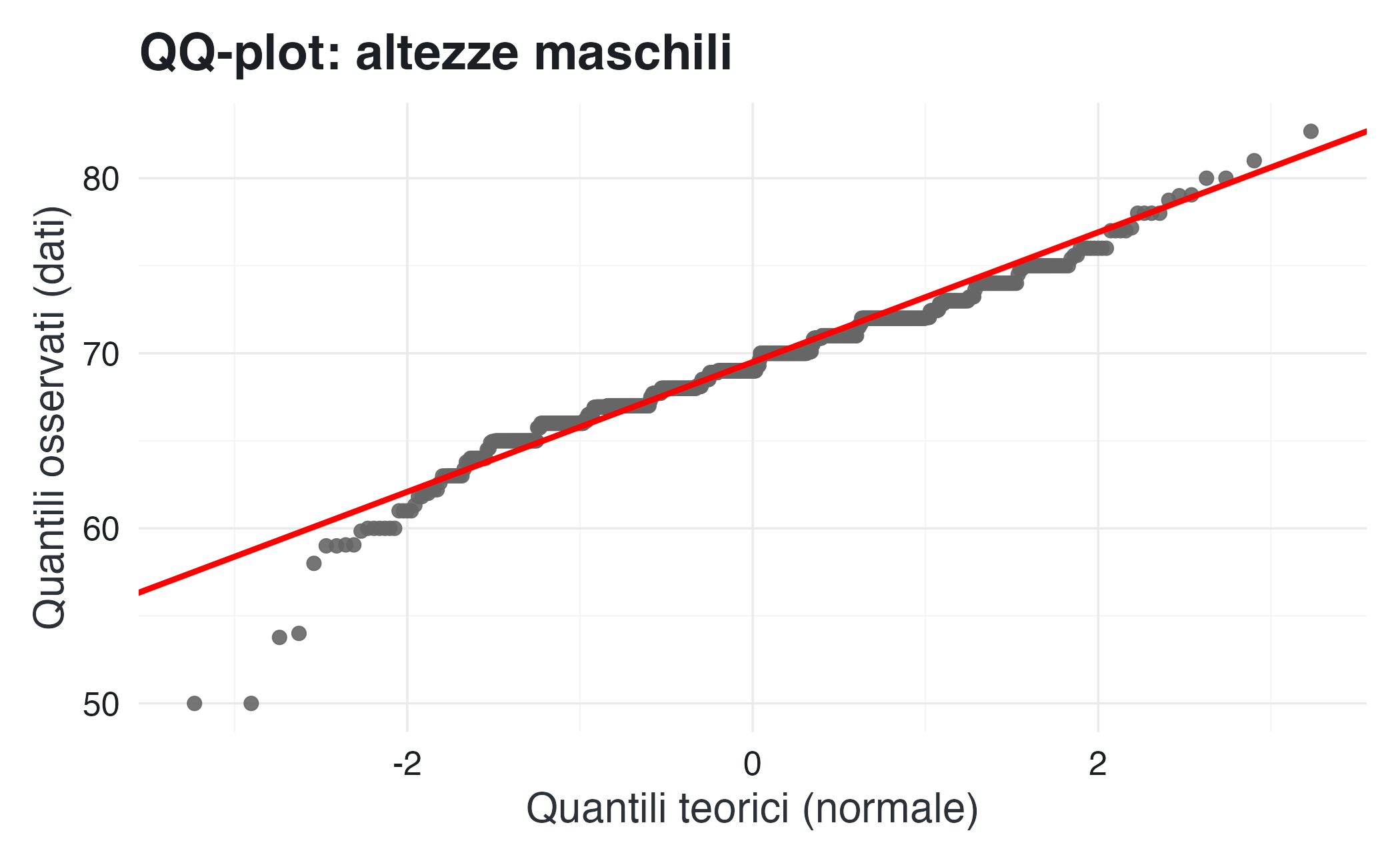
In questo caso, i punti si allineano bene lungo la linea rossa, confermando che la distribuzione delle altezze maschili è approssimativamente normale.
19.6.3 Interpretare deviazioni dalla normalità
Il QQ-plot rivela diversi tipi di non-normalità.
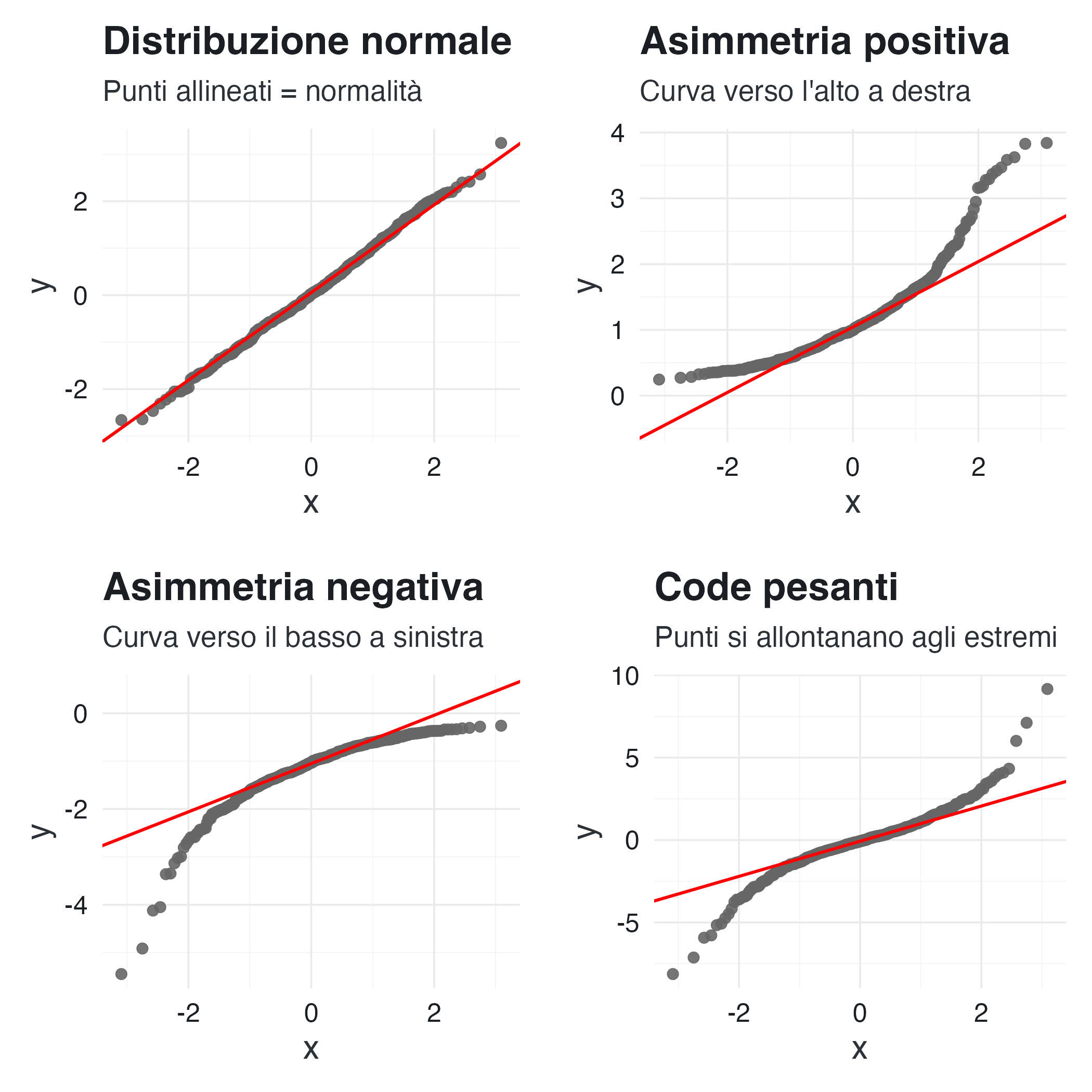
Come interpretare i pattern:
- Punti sulla linea: distribuzione normale ✓
- Curva a S: asimmetria (skewness)
- Punti che si allontanano agli estremi: code pesanti (più outlier del previsto)
- Punti che si avvicinano agli estremi: code leggere (meno variabilità del previsto)
19.6.4 Test formali di normalità
Oltre ai QQ-plots, esistono test statistici formali per verificare la normalità. Il più comune è il test di Shapiro-Wilk:
# Test di Shapiro-Wilk
shapiro_test <- shapiro.test(x)
cat("Test di Shapiro-Wilk\n")
#> Test di Shapiro-Wilk
cat("Statistica W:", round(shapiro_test$statistic, 4), "\n")
#> Statistica W: 0.964
cat("P-value:", round(shapiro_test$p.value, 4), "\n\n")
#> P-value: 0
if (shapiro_test$p.value > 0.05) {
cat("Interpretazione: I dati non mostrano deviazioni significative dalla normalità\n")
} else {
cat("Interpretazione: I dati mostrano deviazioni significative dalla normalità\n")
}
#> Interpretazione: I dati mostrano deviazioni significative dalla normalità
AvvisoAttenzione ai test di normalità
I test formali di normalità (come Shapiro-Wilk) hanno due limitazioni:
- Con campioni piccoli: hanno poco potere, quindi anche deviazioni importanti potrebbero non essere rilevate.
- Con campioni grandi: diventano troppo sensibili, rilevando deviazioni minime che non hanno importanza pratica
Per questo motivo, la valutazione visiva tramite QQ-plot è spesso più utile del test formale.
19.7 Ponte verso la modellazione bayesiana
I concetti introdotti in questo capitolo costituiscono i mattoni concettuali fondamentali per la costruzione, la comprensione e l’interpretazione dei modelli bayesiani che verranno sviluppati nei capitoli successivi. Lontani dall’essere nozioni puramente descrittive, essi anticipano direttamente le scelte di modellazione, di specificazione dei prior e di valutazione dei modelli. Riassumiamo di seguito le connessioni più rilevanti.
19.7.1 1. Dalle distribuzioni ai prior coniugati
Abbiamo visto come la distribuzione normale sia completamente descritta da due parametri, \(\mu\) e \(\sigma\). Nel contesto bayesiano:
- la distribuzione normale può essere utilizzata come prior su parametri continui, quali coefficienti di regressione, effetti di trattamento o differenze tra gruppi;
- l’uso di prior coniugati (ad esempio, una normale come prior combinata con una likelihood normale) consente di ottenere una distribuzione a posteriori della stessa famiglia, semplificando l’analisi e l’interpretazione;
- i posterior rappresentano una conoscenza aggiornata alla luce dei dati osservati, e i relativi intervalli di credibilità (come il 95% HDI) possono essere interpretati direttamente come regioni di plausibilità del parametro.
In questo senso, la distribuzione normale diventa uno strumento naturale per formalizzare l’incertezza sui parametri.
19.7.2 2. Dalla normalità ai modelli gerarchici
La distribuzione normale non svolge un ruolo centrale solo come likelihood per i dati osservati, ma anche come meccanismo di modellazione della variabilità:
- nei modelli gerarchici, è comune assumere che gli effetti specifici di gruppi, soggetti o condizioni siano distribuiti normalmente attorno a un valore medio comune;
- questi effetti sono governati da iperparametri, che regolano il grado di variabilità tra unità e determinano quanto le stime individuali vengano “attratte” verso la media di gruppo.
Questo approccio realizza in modo naturale un compromesso tra pooling completo e stima completamente separata degli effetti, introducendo una forma di regolarizzazione intrinseca tipica della modellazione bayesiana.
19.7.3 3. Standardizzazione e interpretazione degli effetti
Gli z-scores forniscono un’intuizione cruciale che si riflette direttamente nella pratica bayesiana:
- la standardizzazione delle variabili facilita la specificazione di prior informativi deboli, ad esempio esprimendo convinzioni del tipo: “mi aspetto effetti piccoli, entro ±0.5 deviazioni standard”;
- nei modelli di regressione, lavorare su scale standardizzate rende i coefficienti direttamente confrontabili e i prior più facilmente interpretabili;
- ciò riduce il rischio di prior implicitamente troppo informativi o incoerenti con la scala dei dati.
19.7.4 4. Verifica dei modelli e diagnostica
Strumenti come il QQ-plot e la valutazione della normalità rappresentano un primo passo verso una più ampia prospettiva di diagnostica bayesiana:
- anche quando una distribuzione normale è assunta nella likelihood, è necessario esaminare i residui posteriori per valutare l’adeguatezza del modello;
- tuttavia, l’approccio bayesiano va oltre la verifica di singole assunzioni: mediante i posterior predictive checks, si valuta se l’intero modello (prior + likelihood) è in grado di generare dati compatibili con quelli osservati.
In questo quadro, la normalità non è un dogma da accettare o rifiutare, ma una ipotesi modellistica da valutare nel contesto più ampio della capacità del modello di descrivere i dati.
Nel loro insieme, questi collegamenti mostrano come i concetti di distribuzione, parametro e adeguatezza del modello introdotti in questo capitolo non siano meri strumenti descrittivi, ma costituiscano il punto di partenza per una modellazione esplicita, probabilistica e coerente dei fenomeni psicologici. È su queste basi che la modellazione bayesiana può essere intesa non solo come una tecnica statistica, ma come un vero e proprio quadro concettuale per l’inferenza scientifica.
Riflessioni conclusive
In questo capitolo abbiamo utilizzato la distribuzione normale come una lente descrittiva e come primo esempio di modello probabilistico: uno strumento compatto per riassumere dati continui e per ragionare in modo strutturato sulla loro variabilità.
Abbiamo visto che:
- quando la distribuzione normale fornisce una buona approssimazione dei dati, media e deviazione standard assumono un significato informativo preciso, descrivendo rispettivamente la posizione centrale e la dispersione, e consentendo confronti immediati tra gruppi, condizioni e contesti diversi;
- la standardizzazione tramite z-score non è un mero artificio computazionale, ma un passaggio concettuale rilevante: porta variabili eterogenee su una scala comune, rende più interpretabili i confronti e le dimensioni d’effetto e prepara il terreno a scelte di modellazione più consapevoli, ad esempio nell’ambito della regressione;
- la valutazione della normalità va intesa principalmente come un’attività diagnostica: strumenti come il QQ-plot permettono di individuare asimmetrie, code pesanti e valori anomali, segnali che spesso suggeriscono la necessità di trasformazioni, di modelli alternativi o di verosimiglianze più robuste.
Il punto centrale è che la distribuzione normale non deve essere trattata come una “legge dei dati”, ma come una ipotesi di modellazione. È uno strumento potente quando descrive adeguatamente ciò che osserviamo, ma deve poter essere messo in discussione e sostituito quando non lo fa. Questa prospettiva è fondamentale nell’analisi esplorativa dei dati e diventerà ancora più cruciale nei capitoli successivi, quando inizieremo a costruire modelli completi e a valutarne l’adeguatezza confrontando sistematicamente ciò che il modello implica con ciò che i dati mostrano.
ConsiglioCosa ci aspetta
Nei prossimi capitoli vedremo come:
- il Teorema del Limite Centrale spiega perché, in molte situazioni, le medie campionarie presentano una distribuzione approssimativamente normale, anche quando i dati individuali non lo sono;
- questa regolarità rende la distribuzione normale una descrizione utile del comportamento aggregato dei dati, soprattutto quando il campione è sufficientemente ampio;
- la distribuzione normale emerge così come un oggetto centrale della modellazione statistica, sia nei metodi classici sia in quelli bayesiani, fungendo da approssimazione, modello o componente di modelli più generali.
L’obiettivo non è giustificare automaticamente l’uso di test standard, ma comprendere perché e in quali condizioni la normalità diventa una rappresentazione informativa dei dati.
Esercizi
AttenzioneEsercizi
Parte 1: Comprensione concettuale
1. Perché la distribuzione normale è importante?
Perché la distribuzione normale è così ampiamente usata in psicologia? Fornisci almeno tre motivi specifici.
In quali situazioni reali in psicologia possiamo aspettarci che una variabile segua approssimativamente una distribuzione normale?
Cosa significa dire che la normale è un “modello” e non una “legge”?
2. La regola empirica
Spiega con parole tue la regola 68-95-99.7.
-
Un test di ansia ha media 50 e deviazione standard 10 nella popolazione. Usando la regola empirica, determina:
- Entro quale intervallo cade circa il 68% dei punteggi?
- Quale percentuale della popolazione ha un punteggio superiore a 70?
- Un punteggio di 25 è considerato estremo? Perché?
Perché la regola empirica rende la deviazione standard più interpretabile?
3. Z-scores e standardizzazione
Cos’è uno z-score e come si calcola?
Uno studente ottiene QI = 110 (media = 100, sd = 15) e un punteggio di memoria = 58 (media = 50, sd = 8). In quale test ha performato relativamente meglio? Mostra i calcoli.
Dopo la standardizzazione, quali saranno la media e la deviazione standard? Perché questo è utile?
4. QQ-plots
Spiega la logica di base di un QQ-plot.
-
Descrivi come apparirebbe un QQ-plot per ciascuna delle seguenti situazioni:
- Dati perfettamente normali
- Dati con asimmetria positiva
- Dati con code pesanti (più outlier del previsto)
Perché i QQ-plots sono spesso più utili dei test formali di normalità?
Parte 2: Applicazioni pratiche
5. Analisi di punteggi SWLS
Considera i seguenti punteggi SWLS (Satisfaction With Life Scale):
18, 22, 25, 21, 26, 19, 20, 23, 24, 17, 22, 27, 28, 21, 19Calcola media e deviazione standard manualmente (o con R).
Usando la regola empirica, determina l’intervallo entro cui dovrebbe cadere circa il 95% dei punteggi in una popolazione normale con questi parametri.
Calcola gli z-scores per i punteggi 17 e 28. Quale è più estremo?
6. Analisi con R
Usa il seguente codice per generare e analizzare dati:
set.seed(42)
# Genera dati approssimativamente normali
dati_normali <- rnorm(100, mean = 50, sd = 10)
# Genera dati asimmetrici
dati_asimmetrici <- exp(rnorm(100, mean = 3, sd = 0.5))
# Crea QQ-plots per entrambi
library(ggplot2)
ggplot(data.frame(x = dati_normali), aes(sample = x)) +
geom_qq() + geom_qq_line() + ggtitle("Dati normali")
ggplot(data.frame(x = dati_asimmetrici), aes(sample = x)) +
geom_qq() + geom_qq_line() + ggtitle("Dati asimmetrici")
# Verifica la regola empirica per dati_normali
mean(abs(scale(dati_normali)) <= 1) # Dovrebbe essere ~68%
mean(abs(scale(dati_normali)) <= 2) # Dovrebbe essere ~95%
# Test di Shapiro-Wilk
shapiro.test(dati_normali)
shapiro.test(dati_asimmetrici)Esegui il codice e interpreta i QQ-plots: quali dati sembrano più normali?
Le proporzioni osservate per i
dati_normalisono vicine ai valori teorici (68%, 95%)?Cosa indicano i risultati dei test di Shapiro-Wilk?
7. Confronto tra test standardizzati
Una studentessa ottiene i seguenti risultati:
- Test A: punteggio = 75, con media popolazione = 60 e sd = 10
- Test B: punteggio = 115, con media popolazione = 100 e sd = 20
Calcola gli z-scores per entrambi i test.
In quale test la studentessa ha performato meglio relativamente agli altri?
Se entrambi i test seguono distribuzioni normali, in quale percentile approssimativo si trova la studentessa in ciascun test? (Usa la regola empirica)
Parte 3: Riflessione e collegamenti
8. Verso l’inferenza
Spiega come la regola empirica prepara alla costruzione di intervalli di confidenza.
Perché gli z-scores sono importanti per i test statistici che studieremo?
Se i dati non sono perfettamente normali, possiamo comunque usare metodi statistici basati sulla normalità? Quando sì e quando no?
9. Caso applicato: sviluppo di un test
Immagina di sviluppare un nuovo questionario per misurare l’autoefficacia accademica:
Perché potrebbe essere desiderabile che i punteggi seguano approssimativamente una distribuzione normale?
Come useresti QQ-plots durante lo sviluppo del test?
Dopo aver raccolto dati su 500 studenti, il test di Shapiro-Wilk risulta significativo (p < 0.001). Cosa fai? Perché?
ConsiglioSoluzioni
Soluzioni Parte 1
1b. Situazioni in cui aspettarci normalità in psicologia:
- Punteggi di test standardizzati (QI, personalità)
- Misure fisiche (altezza, tempo di reazione)
- Errori di misurazione in esperimenti
- Variabili influenzate da molti fattori indipendenti
2b. Per media=50, sd=10:
- 68% cade in 40-60
- Solo ~2.5% sopra 70 (oltre 2 sd)
- Un punteggio di 25 è 2.5 sd sotto la media, molto estremo (< 0.5% della popolazione)
3b.
- Z-score QI: (110-100)/15 = 0.67
- Z-score memoria: (58-50)/8 = 1.00
- Performance migliore in memoria (z più alto)
3c. Dopo standardizzazione: media=0, sd=1 sempre.
Soluzioni Parte 2
5. Per i dati SWLS forniti:
7.
# Test A
z_a <- (75 - 60) / 10 # 1.5
# Test B
z_b <- (115 - 100) / 20 # 0.75
# La studentessa ha performato meglio nel Test A (z più alto)
# Nel Test A è circa nel 93° percentile (oltre 1 sd)
# Nel Test B è circa nell'77° percentile (tra media e +1 sd)Soluzioni Parte 3
8a. La regola empirica mostra che il 95% dei valori cade entro ±2 sd dalla media. Gli intervalli di confidenza usano questo principio: se conosciamo la distribuzione campionaria di una statistica, possiamo costruire un intervallo che “cattura” il parametro il 95% delle volte.
9c. Con n=500, il test di Shapiro-Wilk è molto sensibile e può rilevare deviazioni minime dalla normalità che non hanno importanza pratica. Azioni consigliate:
- Esaminare il QQ-plot (più informativo)
- Se il QQ-plot mostra solo piccole deviazioni agli estremi, non preoccuparsi
- Ricordare che molti metodi statistici sono robusti a piccole violazioni della normalità
- Se le deviazioni sono sostanziali, considerare trasformazioni o metodi non parametrici
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] gridExtra_2.3 dslabs_0.9.1 ggbeeswarm_0.7.3
#> [4] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [7] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [10] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [13] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [16] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [19] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [22] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [25] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [28] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] inline_0.3.21 sandwich_3.1-1 rlang_1.1.7
#> [4] magrittr_2.0.4 multcomp_1.4-29 snakecase_0.11.1
#> [7] otel_0.2.0 compiler_4.5.2 vctrs_0.6.5
#> [10] stringr_1.6.0 pkgconfig_2.0.3 arrayhelpers_1.1-0
#> [13] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
#> [16] rmarkdown_2.30 purrr_1.2.1 xfun_0.55
#> [19] cachem_1.1.0 jsonlite_2.0.0 broom_1.0.11
#> [22] parallel_4.5.2 R6_2.6.1 stringi_1.8.7
#> [25] RColorBrewer_1.1-3 lubridate_1.9.4 estimability_1.5.1
#> [28] knitr_1.51 zoo_1.8-15 pacman_0.5.1
#> [31] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [34] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
#> [37] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [40] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [43] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [46] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [49] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [52] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [55] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [58] emmeans_2.0.1 tools_4.5.2 mvtnorm_1.3-3
#> [61] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [64] nlme_3.1-168 beeswarm_0.4.0 vipor_0.4.7
#> [67] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [70] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [73] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [76] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [79] lifecycle_1.0.5 MASS_7.3-65Bibliografia
Irizarry, R. A. (2024). Introduction to Data Science: Data Wrangling and Visualization with R. CRC Press.