4 Significatività statistica
- comprendere la logica del test di ipotesi frequentista;
- interpretare correttamente il valore-\(p\);
- riconoscere i limiti e i fraintendimenti comuni legati alla significatività statistica.
- Leggere il capitolo Hypothesis Testing di Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition).
- Aver compreso le distribuzioni campionarie e gli intervalli di confidenza.
4.1 La logica del test d’ipotesi
4.1.1 Elementi fondamentali
Il test d’ipotesi frequentista si fonda sul confronto tra due modelli inferenziali contrapposti, formulati a priori:
- il modello basato sull’ipotesi nulla (\(H_0\)), che rappresenta una situazione di riferimento, tipicamente caratterizzata dall’assenza di un effetto, di una differenza o di un’associazione;
- il modello basato sull’ipotesi alternativa (\(H_1\)), che descrive la presenza dell’effetto oggetto di studio.
È importante sottolineare che, nel paradigma frequentista, il test non confronta direttamente la plausibilità relativa di \(H_0\) e \(H_1\). L’intero procedimento è invece costruito condizionatamente all’assunzione che \(H_0\) sia vera. Il problema inferenziale viene così riformulato in termini controfattuali: quanto sono compatibili i dati osservati con il mondo descritto dall’ipotesi nulla?
Per rispondere a questa domanda si introduce una statistica test, ossia una funzione dei dati campionari progettata per misurare la discrepanza tra quanto osservato e quanto ci si attenderebbe sotto \(H_0\). Esempi comuni di statistiche test sono la statistica \(t\), la statistica \(z\) o la statistica \(\chi^2\), a seconda del contesto analitico.
Sotto l’ipotesi che \(H_0\) sia corretta, la statistica test possiede una distribuzione campionaria nota, che può essere dedotta teoricamente. Confrontando il valore osservato della statistica con questa distribuzione si ottiene il valore-p, definito come:
la probabilità di osservare un valore della statistica test uguale o più estremo di quello effettivamente ottenuto, assumendo che l’ipotesi nulla sia vera.
Il valore-\(p\) quantifica dunque un grado di incompatibilità tra i dati e il modello rappresentato da \(H_0\), ma non la probabilità che l’ipotesi nulla sia vera.
La decisione inferenziale è formalizzata confrontando il valore-\(p\) con un livello di significatività prefissato \(\alpha\) (per convenzione spesso pari a 0.05). Se \(p \leq \alpha\), il risultato è considerato sufficientemente raro sotto \(H_0\) da giustificare il rifiuto dell’ipotesi nulla; se \(p > \alpha\), non si dispone di evidenza sufficiente per respingerla.
Dal punto di vista epistemologico, è cruciale notare che il test d’ipotesi non produce una dimostrazione né una conferma dell’ipotesi alternativa. Esso fornisce piuttosto una regola decisionale basata su probabilità di lungo periodo, coerente con l’impostazione frequentista dell’inferenza.
4.1.2 Tipi di errore
Il test d’ipotesi frequentista, in quanto procedura decisionale basata su probabilità di lungo periodo, comporta inevitabilmente la possibilità di errori inferenziali. Poiché la decisione viene presa sulla base di un campione finito e di una soglia convenzionale, non esiste una regola che garantisca simultaneamente l’assenza di errori in tutti i casi.
Si distinguono due tipi fondamentali di errore:
Errore di tipo I: consiste nel rifiutare l’ipotesi nulla \(H_0\) quando essa è in realtà vera. La probabilità di commettere questo errore è controllata dal livello di significatività \(\alpha\), fissato a priori. In altri termini, \(\alpha\) rappresenta la frequenza massima tollerata di falsi positivi nel lungo periodo.
Errore di tipo II: consiste nel non rifiutare l’ipotesi nulla quando essa è falsa, ossia nel non rilevare un effetto che è effettivamente presente nella popolazione. La probabilità di questo errore è indicata con \(\beta\).
La potenza del test, definita come \(1 - \beta\), misura la capacità del test di individuare un effetto quando esso esiste realmente. Dal punto di vista inferenziale, la potenza quantifica la sensibilità della procedura decisionale ed è influenzata da diversi fattori, tra cui la dimensione dell’effetto, la variabilità dei dati, il livello di significatività \(\alpha\) e la dimensione campionaria.
È importante sottolineare che, nel paradigma frequentista, sia \(\alpha\) sia \(\beta\) sono proprietà della procedura di test sotto ripetizione del campionamento, non del singolo studio osservato. La scelta del livello di significatività implica quindi un compromesso: ridurre la probabilità di errore di tipo I tende ad aumentare la probabilità di errore di tipo II, a meno di intervenire su altri aspetti del disegno sperimentale, come la numerosità del campione.
Questa tensione tra i due tipi di errore costituisce uno dei nodi centrali della metodologia dei test di ipotesi e anticipa alcune delle criticità che verranno discusse nelle sezioni successive.
4.2 Il test del Chi-Quadrato
Per illustrare in modo concreto la logica del test d’ipotesi, consideriamo il test del chi-quadrato di indipendenza, uno strumento largamente utilizzato per valutare se due variabili categoriali siano statisticamente associate oppure possano essere considerate indipendenti.
Questo test incarna in modo particolarmente chiaro la filosofia frequentista: l’inferenza non riguarda la probabilità che esista un’associazione, ma la probabilità di osservare una discrepanza tra dati e modello di riferimento assumendo vera l’ipotesi di indipendenza.
4.2.1 Il concetto di indipendenza
Due variabili categoriali si dicono indipendenti quando la distribuzione di una non dipende dal valore assunto dall’altra. In termini probabilistici, se (A) e (B) sono due eventi, l’indipendenza implica:
\[ P(A \cap B) = P(A) \cdot P(B). \]
Trasposto nel contesto di una tabella di contingenza, questo significa che la frequenza attesa in ciascuna cella è determinata unicamente dalle distribuzioni marginali, e non da un legame sistematico tra le categorie delle due variabili.
L’ipotesi nulla del test del chi-quadrato formalizza esattamente questa idea:
\[ H_0:\ \text{le due variabili sono indipendenti}. \]
4.2.2 Un esempio concreto
Supponiamo di condurre uno studio psicologico volto a indagare la relazione tra livello di stress percepito e qualità del sonno in un campione di adulti.
Le due variabili categoriali considerate sono:
- Stress percepito: Basso / Alto.
- Qualità del sonno: Buona / Scarsa.
I dati osservati sono riassunti nella seguente tabella di contingenza 2×2:
| Sonno buono | Sonno scarso | |
|---|---|---|
| Stress basso | 42 | 40 |
| Stress alto | 19 | 39 |
La domanda di ricerca è:
Il livello di stress percepito è indipendente dalla qualità del sonno, oppure esiste un’associazione tra le due variabili?
4.2.3 Valori attesi sotto l’ipotesi nulla
Sotto l’ipotesi nulla di indipendenza, possiamo calcolare quali frequenze ci aspetteremmo di osservare nella tabella se non esistesse alcuna associazione tra le variabili.
Il procedimento segue una logica rigorosamente probabilistica:
- si calcolano i totali marginali di riga e di colonna;
- la frequenza attesa in ciascuna cella è data dal prodotto dei totali marginali, normalizzato per il totale generale.
Formalmente, per la cella nella riga \(i\) e colonna \(j\), il valore atteso \(E_{ij}\) è:
\[ E_{ij} = \frac{(\text{totale riga } i) \times (\text{totale colonna } j)}{\text{totale generale}} = \frac{R_i \times C_j}{N}. \]
Questa formula deriva direttamente dalla definizione di indipendenza: se le variabili sono indipendenti, la probabilità congiunta è il prodotto delle probabilità marginali.
4.2.4 Calcolo manuale dei valori attesi
Calcoliamo dapprima i totali marginali:
-
Totali di riga:
- Stress basso = 42 + 40 = 82
- Stress alto = 19 + 39 = 58
-
Totali di colonna:
- Sonno buono = 42 + 19 = 61
- Sonno scarso = 40 + 39 = 79
Totale generale: \(N = 140\)
Ad esempio, il valore atteso per la cella (Stress basso, Sonno buono) è:
\[ E_{\text{SB, buono}} = \frac{82 \times 61}{140} = \frac{5002}{140} \approx 35.7 \]
Per la cella (Stress alto, Sonno scarso) abbiamo:
\[ E_{\text{SA, scarso}} = \frac{58 \times 79}{140} = \frac{4582}{140} \approx 32.7 \]
La tabella completa dei valori attesi è:
| Sonno buono | Sonno scarso | |
|---|---|---|
| Stress basso | 35.7 | 46.3 |
| Stress alto | 25.3 | 32.7 |
4.2.5 La statistica del Chi-Quadrato
Per quantificare la discrepanza complessiva tra frequenze osservate e attese utilizziamo la statistica del chi-quadrato di Pearson:
\[ \chi^2 = \sum_{i=1}^{r} \sum_{j=1}^{c} \frac{(O_{ij} - E_{ij})^2}{E_{ij}}, \] dove:
- \(O_{ij}\) è la frequenza osservata,
- \(E_{ij}\) è la frequenza attesa,
- \(r\) è il numero di righe,
- \(c\) è il numero di colonne.
Questa statistica aggrega, su tutte le celle, la distanza tra il valore osservato e il valore atteso, normalizzata rispetto alla scala delle frequenze attese.
L’interpretazione è intuitiva:
- valori piccoli di \(\chi^2\) indicano buona compatibilità con l’ipotesi di indipendenza;
- valori grandi indicano una discrepanza difficilmente attribuibile al solo caso.
4.2.6 Calcolo manuale della statistica
Calcoliamo il contributo di alcune celle:
- Stress basso, Sonno buono: \(O = 42\), \(E \approx 35.7\)
\[ \frac{(42 - 35.7)^2}{35.7} \approx \frac{(6.3)^2}{35.7} \approx 1.11 \]
- Stress alto, Sonno buono: \(O = 19\), \(E \approx 25.3\)
\[ \frac{(19 - 25.3)^2}{25.3} \approx \frac{(-6.3)^2}{25.3} \approx 1.57 \]
Sommando i contributi di tutte le celle:
4.2.7 Distribuzione di riferimento e gradi di libertà
Sotto l’ipotesi nulla e in presenza di frequenze attese sufficientemente grandi, la statistica \(\chi^2\) segue approssimativamente una distribuzione chi-quadrato con:
\[ \text{df} = (r - 1)(c - 1). \]
Nel nostro caso:
\[ \text{df} = (2 - 1)(2 - 1) = 1. \]
4.2.8 Il valore-\(p\)
Il valore-p è definito come la probabilità di osservare un valore della statistica \(\chi^2\) almeno altrettanto grande di quello ottenuto, assumendo vera l’ipotesi nulla di indipendenza.
Graficamente, corrisponde all’area sotto la curva \(\chi^2\) (con 1 grado di libertà) a destra del valore osservato, ed è confrontabile con il livello di significatività \(\alpha = 0.05\).
Nel nostro esempio, il valore-\(p\) risulta circa 0.03 ed è inferiore al livello di significatività convenzionale \(\alpha = 0.05\). Questo indica che la discrepanza osservata sarebbe rara se le variabili fossero davvero indipendenti.
4.2.9 Decisione inferenziale
Poiché la statistica test cade nella regione di rifiuto dell’ipotesi nulla (equivalentemente, poiché \(p < \alpha\)), rifiutiamo \(H_0\) e concludiamo che:
esiste un’associazione statisticamente significativa tra stress percepito e qualità del sonno nel campione osservato.
4.2.10 Verifica con R
chisq.test(osservati, correct = FALSE)
#>
#> Pearson's Chi-squared test
#>
#> data: osservati
#> X-squared = 5, df = 1, p-value = 0.03(La correzione di continuità è disattivata per mantenere coerenza con il calcolo manuale e con la rappresentazione grafica della distribuzione \(\chi^2\).)
4.2.11 Distribuzione \(\chi^2\), valore-\(p\), \(\alpha\) e regione critica
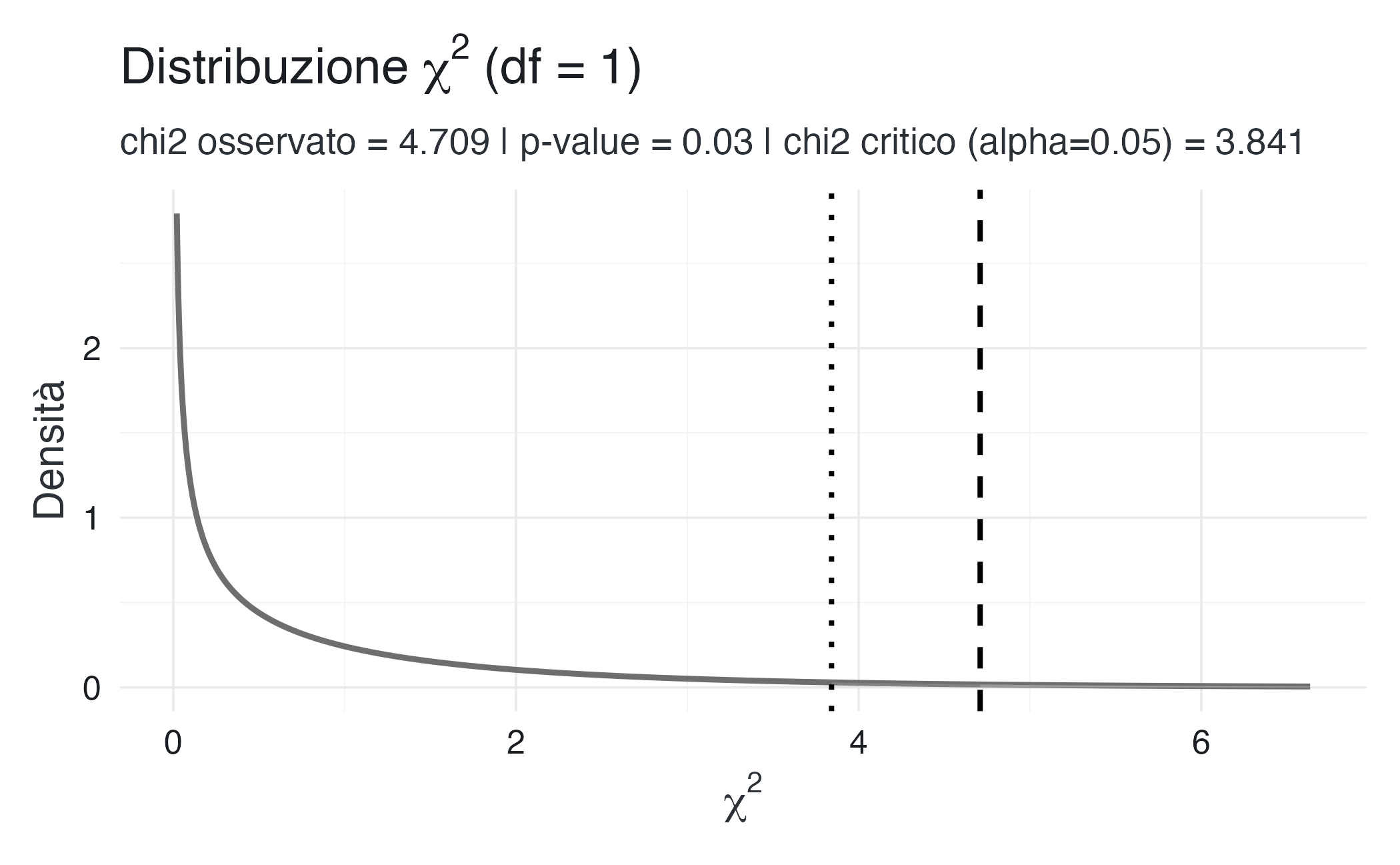
La linea punteggiata delimita la regione di rifiuto dell’ipotesi nulla: l’area sottesa alla curva a destra del valore di \(x\) individuato da tale linea, fino a \(+\infty\), è pari ad \(\alpha\). La linea tratteggiata indica invece la posizione della statistica test.
Poiché la statistica test cade all’interno della regione di rifiuto dell’ipotesi nulla, l’ipotesi \(H_0\) viene rifiutata. L’area compresa tra il valore osservato della statistica test e \(+\infty\) rappresenta il valore-\(p\).
Quando il valore-\(p\) è minore di \(\alpha\), si rifiuta \(H_0\). I due criteri, ovvero il confronto con la regione critica e confronto tra valore-\(p\) e \(\alpha\), sono formalmente equivalenti e conducono sempre alla stessa decisione.
4.3 Il test per una media
Passiamo ora a considerare il caso di dati continui. Una delle domande inferenziali più comuni nelle scienze psicologiche consiste nel verificare se la media di una popolazione differisca da un valore di riferimento noto. Esempi tipici includono:
- un trattamento ha modificato i punteggi rispetto a una norma prestabilita?
- un gruppo clinico differisce dalla popolazione generale?
- una prestazione media è superiore (o inferiore) a un valore soglia teoricamente rilevante?
Dal punto di vista frequentista, queste domande vengono affrontate valutando la compatibilità dei dati osservati con un’ipotesi nulla che specifica un valore preciso della media.
4.3.1 Il punto di partenza: la distribuzione campionaria della media
La logica del test per una media si fonda direttamente sulla distribuzione campionaria della media. Se estraiamo ripetutamente campioni di dimensione \(n\) da una popolazione con media \(\mu\) e deviazione standard \(\sigma\), allora, per campioni sufficientemente grandi, le medie campionarie \(\bar{X}\) seguono una distribuzione approssimativamente normale con:
- media: \(\mu_{\bar{X}} = \mu\);
- errore standard: \(\sigma_{\bar{X}} = \dfrac{\sigma}{\sqrt{n}}\).
Questo risultato, garantito dal teorema del limite centrale, ci fornisce un modello probabilistico per valutare quanto una media campionaria osservata sia “estrema” rispetto a ciò che ci aspetteremmo sotto una data ipotesi sulla popolazione.
4.3.2 Un esempio concreto
Un ricercatore vuole verificare se i punteggi di benessere psicologico di un gruppo di studenti universitari differiscano dalla media normativa della popolazione, pari a \(\mu_0 = 24\). I punteggi osservati in un campione di 10 studenti sono:
Calcoliamo la media campionaria:
La media osservata è pari a 23.8, leggermente inferiore al valore di riferimento. La domanda inferenziale diventa quindi:
questa differenza è spiegabile come fluttuazione casuale del campionamento, oppure indica una differenza reale nella popolazione?
4.3.3 La logica del test: il caso ideale con \(\sigma\) nota
Per chiarire la logica del test, consideriamo inizialmente una situazione ideale in cui la deviazione standard della popolazione sia nota. Supponiamo che studi precedenti abbiano stabilito \(\sigma = 4\).
4.3.3.1 Formulazione delle ipotesi
Poiché il ricercatore ipotizza un benessere superiore alla norma, impostiamo un test monodirezionale:
- \(H_0\): \(\mu = 24\) (la media della popolazione è uguale alla norma);
- \(H_1\): \(\mu > 24\) (la media della popolazione è superiore alla norma).
4.3.3.2 Distribuzione campionaria sotto \(H_0\)
Assumendo vera \(H_0\), la distribuzione delle medie campionarie sarebbe normale con:
- media: \(\mu_{\bar{X}} = 24\);
- errore standard: \[ \sigma_{\bar{X}} = \frac{4}{\sqrt{10}} = \frac{4}{3.162} \approx 1.265. \]
4.3.3.3 La statistica \(Z\): standardizzare la media osservata
Per valutare quanto la media osservata sia estrema rispetto a questa distribuzione, calcoliamo la statistica:
\[ Z = \frac{\bar{X} - \mu_0}{\sigma_{\bar{X}}} = \frac{\bar{X} - \mu_0}{\sigma / \sqrt{n}}. \]
Questa è una standardizzazione della media campionaria, del tutto analoga allo z-score di un punteggio individuale, ma applicata alla distribuzione delle medie.
Calcoliamo il valore di \(Z\) per il nostro esempio:
\[ Z = \frac{23.8 - 24}{1.265} = \frac{-0.2}{1.265} \approx -0.158 \]
4.3.3.4 Il valore-\(p\)
Poiché il test è monodirezionale (\(H_1\): \(\mu > 24\)), il valore-p è la probabilità, sotto \(H_0\), di osservare una media almeno altrettanto grande di quella ottenuta. In termini della statistica \(Z\), questo equivale a calcolare l’area sotto la curva normale standard a destra del valore \(Z\) osservato.
Un valore-\(p\) di circa 0.56 indica che, se \(H_0\) fosse vera, risultati come quello osservato sarebbero molto comuni. I dati sono quindi perfettamente compatibili con l’ipotesi nulla.
Nota che il valore-\(p\) è così alto perché la media osservata è addirittura inferiore al valore ipotizzato, mentre il test cercava evidenze in direzione opposta.
4.3.4 Il problema realistico: \(\sigma\) è sconosciuta
Nel ragionamento precedente abbiamo assunto di conoscere la deviazione standard della popolazione, \(\sigma = 4\). Nella pratica della ricerca, tuttavia, questo valore è quasi sempre ignoto e deve essere stimato dai dati stessi.
La soluzione naturale è sostituire \(\sigma\) con la deviazione standard campionaria \(s\):
L’errore standard stimato diventa:
\[ SE = \frac{s}{\sqrt{n}} = \frac{4.211}{\sqrt{10}} \approx 1.332 \]
4.3.5 Dalla statistica \(Z\) alla statistica \(t\)
Sostituendo \(\sigma\) con \(s\), la statistica diventa:
\[ t = \frac{\bar{X} - \mu_0}{s / \sqrt{n}}. \]
La formula è identica a quella della statistica \(Z\), con l’unica differenza che utilizziamo la stima campionaria \(s\) invece del valore noto \(\sigma\). Potrebbe sembrare un dettaglio minore, ma ha una conseguenza importante: introduciamo ulteriore incertezza nel nostro calcolo.
Il valore di \(s\) che calcoliamo dal campione è esso stesso una stima, soggetta a variabilità campionaria. A volte sovrastimerà \(\sigma\), altre volte lo sottostimerà. Questa incertezza aggiuntiva si propaga nella statistica test, rendendola più variabile di quanto sarebbe se conoscessimo il vero valore di \(\sigma\).
4.3.6 La distribuzione \(t\) di Student
Per tenere conto di questa maggiore incertezza, la statistica \(t\) segue una distribuzione t di Student, caratterizzata da:
- forma simile alla normale;
- code più pesanti, che riflettono la variabilità introdotta dalla stima di \(\sigma\);
- dipendenza dai gradi di libertà.
In altre parole, la distribuzione \(t\) è più “cauta” della normale: assegna maggiore probabilità a risultati lontani dal centro.
x <- seq(-4, 4, length.out = 200)
df_plot <- data.frame(
x = rep(x, 4),
densita = c(dnorm(x), dt(x, df = 3), dt(x, df = 9), dt(x, df = 30)),
distribuzione = rep(c("Normale", "t (df=3)", "t (df=9)", "t (df=30)"), each = 200)
)
ggplot(df_plot, aes(x = x, y = densita, color = distribuzione)) +
geom_line(linewidth = 1) +
labs(x = "Valore", y = "Densità", color = "Distribuzione") 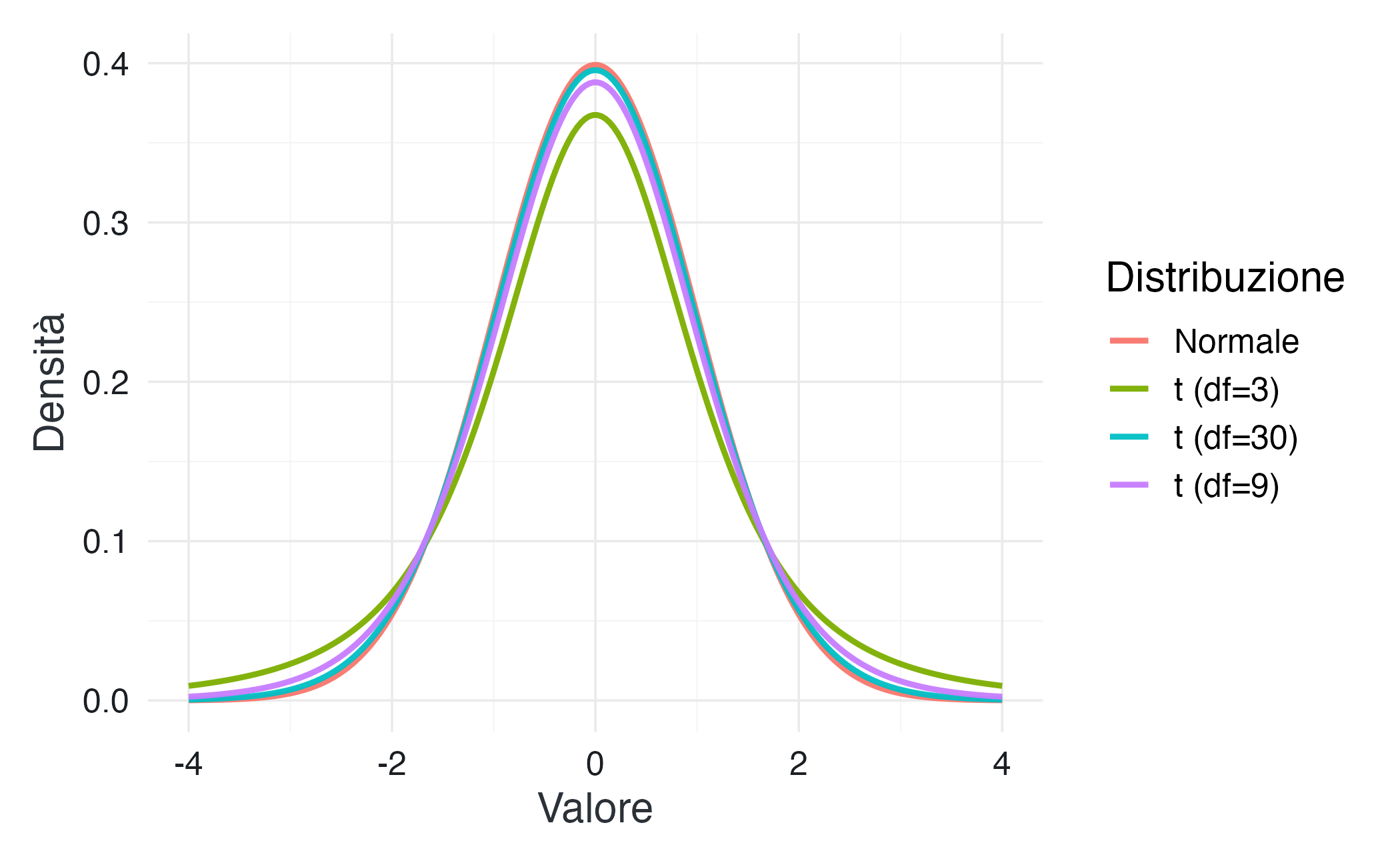
4.3.7 I gradi di libertà
Una caratteristica distintiva della distribuzione \(t\) è che la sua forma dipende dai gradi di libertà (df), che nel caso del test per una media sono pari a \(n - 1\):
\[ \text{df} = n - 1. \]
Nel nostro esempio, con 10 osservazioni, abbiamo \(\text{df} = 9\).
I gradi di libertà determinano quanto le code della distribuzione \(t\) siano pesanti:
- con pochi gradi di libertà (campioni piccoli), l’incertezza nella stima di \(\sigma\) è elevata, e la distribuzione \(t\) ha code molto più pesanti della normale;
- con molti gradi di libertà (campioni grandi), la stima di \(\sigma\) diventa più precisa, e la distribuzione \(t\) converge progressivamente verso la normale standard.
Questo comportamento ha perfettamente senso: con un campione di 10 osservazioni, la nostra stima di \(\sigma\) è piuttosto incerta; con un campione di 1000 osservazioni, possiamo fidarci molto di più della stima.
4.3.8 Calcolo della statistica \(t\) e del valore-\(p\)
Applichiamo ora questi concetti al nostro esempio:
Per il test monodirezionale (\(H_1\): \(\mu > 24\)), il valore-\(p\) è l’area sotto la curva della distribuzione \(t\) con 9 gradi di libertà, a destra del valore osservato:
4.3.9 Interpretazione
Il valore-\(p\) di circa 0.56 ci dice che, se la vera media della popolazione fosse 24, avremmo circa il 56% di probabilità di osservare una media campionaria pari o superiore a 23.8. Questo risultato è completamente compatibile con l’ipotesi nulla: i dati non forniscono alcuna evidenza che il benessere degli studenti sia superiore alla norma.
4.3.10 Verifica con R
La funzione t.test() esegue automaticamente tutti questi calcoli. Per un test monodirezionale in cui l’ipotesi alternativa è \(\mu > 24\):
t.test(punteggi, mu = 24, alternative = "greater")
#>
#> One Sample t-test
#>
#> data: punteggi
#> t = -0.1, df = 9, p-value = 0.6
#> alternative hypothesis: true mean is greater than 24
#> 95 percent confidence interval:
#> 21.3 Inf
#> sample estimates:
#> mean of x
#> 23.8I risultati confermano i nostri calcoli manuali: \(t = -0.15\), \(\text{df} = 9\), \(p = 0.56\).
4.3.11 Il test bidirezionale
Se il ricercatore non avesse una direzione specifica in mente e volesse semplicemente verificare se la media differisce da 24 (in qualsiasi direzione), dovrebbe formulare un test bidirezionale:
- \(H_0\): \(\mu = 24\)
- \(H_1\): \(\mu \neq 24\)
In questo caso, il valore-\(p\) considera entrambe le code della distribuzione:
t.test(punteggi, mu = 24, alternative = "two.sided")
#>
#> One Sample t-test
#>
#> data: punteggi
#> t = -0.1, df = 9, p-value = 0.9
#> alternative hypothesis: true mean is not equal to 24
#> 95 percent confidence interval:
#> 20.8 26.8
#> sample estimates:
#> mean of x
#> 23.8Anche in questo caso, il valore-\(p\) elevato (0.88) indica che i dati sono perfettamente compatibili con l’ipotesi nulla.
4.4 Interpretazione corretta del valore-\(p\)
È essenziale ribadire che il valore-p:
- non è la probabilità che \(H_0\) sia vera;
- non misura l’importanza o la grandezza dell’effetto;
- non quantifica la probabilità di replicazione del risultato.
Il valore-\(p\) esprime esclusivamente quanto sarebbero rari dati come quelli osservati assumendo vera l’ipotesi nulla. Un valore elevato non “conferma” \(H_0\): indica semplicemente che i dati non sono sufficientemente incompatibili con essa.
4.5 Limiti del test di ipotesi frequentista
Pur essendo storicamente e operativamente centrale nella pratica scientifica, il test d’ipotesi frequentista presenta limiti rilevanti, soprattutto quando lo si interpreta come strumento generale per valutare l’evidenza empirica. Molte criticità non riguardano singole scelte tecniche, ma discendono dalla struttura logica del procedimento: un’inferenza costruita attorno a decisioni di lungo periodo, formalizzate tramite soglie convenzionali.
Decisione dicotomica e soglia convenzionale. L’esito del test è tipicamente binario (rifiuta / non rifiuta \(H_0\)) e dipende da una soglia () scelta per convenzione. Ne consegue una discontinuità interpretativa: valori-\(p\) quasi identici ma situati su lati opposti della soglia (ad esempio 0.049 vs 0.051) producono conclusioni formalmente opposte, pur corrispondendo a evidenza empirica praticamente indistinguibile.
Dipendenza dalla dimensione campionaria. A parità di effetto reale, la statistica test tende a crescere con l’aumento di (n), perché l’errore standard diminuisce. Con campioni molto grandi, anche differenze minime possono diventare “significative”, amplificando la distanza tra significatività statistica e rilevanza sostanziale (o importanza teorica/pratica). In assenza di una misura dell’effetto e della sua incertezza, il valore-\(p\) può indurre interpretazioni fuorvianti.
Asimmetria informativa dei risultati non significativi. Un valore-\(p\) elevato non fornisce evidenza a favore di \(H_0\): indica soltanto che, dato il disegno dello studio e la variabilità dei dati, non si è osservata una discrepanza sufficientemente grande rispetto al modello nullo. In molti casi, un esito “non significativo” riflette semplicemente scarsa informazione (ad esempio potenza bassa), non l’assenza di un effetto.
Problema dell’ipotesi nulla puntuale. Nella pratica si testa spesso un’ipotesi nulla del tipo \(H_0:\ \delta = 0\) (effetto esattamente nullo). Tuttavia, in molti contesti empirici questa ipotesi è ontologicamente implausibile: è raro che un intervento, una manipolazione o una differenza tra gruppi produca un effetto esattamente pari a zero. Il test finisce così per rispondere a una domanda formalmente precisa ma talvolta scientificamente marginale: se l’effetto è esattamente nullo, non se sia piccolo, trascurabile o irrilevante.
Dipendenza dal piano di campionamento e “controfattualità” del valore-p. Il valore-\(p\) è definito rispetto a ciò che sarebbe accaduto sotto ripetizione del campionamento e quindi dipende dal piano sperimentale e dalle regole procedurali (ad esempio stop rule, numero di confronti, strategia di raccolta dati). In altre parole, esso incorpora anche esiti “possibili” ma non osservati: la misura di evidenza dipende, in parte, da ciò che il ricercatore avrebbe potuto osservare se le circostanze fossero state diverse.
Nel loro insieme, questi limiti suggeriscono che il test d’ipotesi e il valore-\(p\) funzionano bene come strumenti di controllo procedurale degli errori nel lungo periodo, ma sono meno adatti quando l’obiettivo è esprimere in modo diretto e graduato l’evidenza empirica o la plausibilità di ipotesi scientifiche. È in questo spazio che si collocano molte delle motivazioni storiche e concettuali che hanno alimentato l’interesse per approcci alternativi, in particolare quelli di matrice bayesiana.
4.6 Verso un approccio migliore
Una comunicazione statistica più informativa e scientificamente solida dovrebbe andare oltre il semplice esito dicotomico del test di ipotesi. In particolare, la presentazione dei risultati dovrebbe includere intervalli di confidenza, stime delle dimensioni dell’effetto e una discussione esplicita dell’incertezza associata alle stime, evitando l’uso rigido di soglie convenzionali per distinguere tra risultati “significativi” e “non significativi”.
In questa prospettiva, l’attenzione si sposta dal quesito “l’effetto esiste?” a domande più rilevanti sul piano scientifico, quali “quanto è grande l’effetto?”, “con quale precisione è stimato?” e “quanto è compatibile con le ipotesi teoriche in gioco?”. Questo cambiamento di enfasi favorisce interpretazioni più graduali e cumulative dell’evidenza empirica.
L’approccio bayesiano offre, in questo contesto, una cornice concettuale alternativa che risponde in modo diretto ad alcune delle criticità del frequentismo. Esso consente di formulare affermazioni probabilistiche sui parametri e sulle ipotesi, condizionate ai dati osservati, e di integrare esplicitamente informazioni pregresse, teoriche o empiriche, nel processo inferenziale. Inoltre, distingue in modo concettualmente chiaro tra assenza di evidenza e evidenza a favore dell’assenza di un effetto, una distinzione che risulta difficile da articolare nel linguaggio dei test di significatività.
Nel complesso, questo approccio promuove una visione dell’inferenza statistica come processo di aggiornamento razionale della conoscenza, piuttosto che come meccanismo decisionale basato su soglie arbitrarie. Senza sostituire automaticamente gli strumenti frequentisti, esso offre un quadro interpretativo più flessibile e spesso più aderente alle domande che guidano la ricerca scientifica.
Riflessioni conclusive
In questo capitolo abbiamo analizzato il test di ipotesi frequentista come strumento per valutare la compatibilità tra dati empirici e un modello teorico di riferimento, formalizzato attraverso l’ipotesi nulla. È emerso con chiarezza che il valore-p possiede un significato molto più circoscritto di quanto suggeriscano molte interpretazioni correnti: esso non fornisce la probabilità che \(H_0\) sia vera, né misura direttamente la forza di un effetto, ma quantifica esclusivamente quanto sarebbero rari dati come quelli osservati assumendo valida l’ipotesi nulla.
Questa limitazione interpretativa, unita alla natura dicotomica della decisione inferenziale e alla dipendenza della significatività statistica da fattori come la dimensione campionaria, mette in luce una distanza strutturale tra significatività statistica e rilevanza pratica o teorica dei risultati. In molti contesti applicativi, tali vincoli rendono il test di ipotesi poco adatto a rispondere in modo diretto alle domande che guidano la ricerca scientifica.
Per queste ragioni, appare opportuno sostituire il test di significatività con strumenti inferenziali più informativi e interpretabili, capaci di esprimere in modo graduale l’incertezza e di fornire stime direttamente utilizzabili sul piano teorico e applicativo. L’approccio bayesiano rappresenta una di queste alternative: esso propone una concezione diversa della probabilità e dell’inferenza, consentendo di formulare affermazioni probabilistiche sui parametri e di integrare in modo esplicito l’informazione disponibile.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.5.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.5.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3