3 Intervalli di fiducia
- costruire intervalli di confidenza per la media di una popolazione;
- interpretare correttamente il significato di un intervallo di confidenza;
- distinguere tra interpretazione corretta e fraintendimenti comuni.
- Leggere il capitolo Estimation, Confidence Intervals, and Bootstrapping di Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition).
- Aver compreso il concetto di distribuzione campionaria (capitolo precedente).
3.1 Costruzione dell’intervallo di confidenza
3.1.1 Caso con varianza nota
Consideriamo il caso ideale in cui la popolazione di interesse sia distribuita normalmente, con media \(\mu\) sconosciuta e varianza \(\sigma^2\) nota. Sebbene questa situazione sia rara nelle applicazioni reali, essa rappresenta un punto di partenza concettualmente semplice per comprendere la logica di costruzione degli intervalli di confidenza.
In tali condizioni, la media campionaria \(\bar{X}\), calcolata su un campione di dimensione \(n\), segue una distribuzione normale:
\[ \bar{X} \sim \mathcal{N}\!\left(\mu, \; \frac{\sigma^2}{n}\right). \]
Standardizzando la media campionaria otteniamo una variabile casuale con distribuzione normale standard:
\[ Z = \frac{\bar{X} - \mu}{\sigma / \sqrt{n}} \sim \mathcal{N}(0, 1). \]
Questa trasformazione consente di sfruttare le proprietà note della distribuzione normale standard. In particolare, fissato un livello di confidenza del 95%, esiste un valore critico \(z_{0.025} = 1.96\) tale che:
\[ P(-1.96 \leq Z \leq 1.96) = 0.95. \]
Questa probabilità va interpretata come una proprietà della variabile casuale \(Z\), e dunque della procedura di costruzione dell’intervallo, non del parametro \(\mu\).
Sostituendo l’espressione di \(Z\) e invertendo la disuguaglianza, si isola il parametro \(\mu\) all’interno di un intervallo dipendente dai dati osservati:
\[ P\!\left( \bar{X} - 1.96\,\frac{\sigma}{\sqrt{n}} \;\leq\; \mu \;\leq\; \bar{X} + 1.96\,\frac{\sigma}{\sqrt{n}} \right) = 0.95. \]
L’espressione tra parentesi definisce l’intervallo di confidenza al 95% per la media:
\[ \left( \bar{X} - 1.96\,\frac{\sigma}{\sqrt{n}}, \;\; \bar{X} + 1.96\,\frac{\sigma}{\sqrt{n}} \right). \]
Dal punto di vista frequentista, questo intervallo non assegna una probabilità al parametro (). Esso rappresenta piuttosto il risultato di una procedura inferenziale che, se ripetuta indefinitamente su campioni estratti dalla stessa popolazione, produrrebbe intervalli contenenti il valore vero di () nel 95% dei casi.
In questo senso, l’intervallo di confidenza individua l’insieme dei valori del parametro compatibili con i dati osservati, dato il modello probabilistico assunto e il livello di confidenza prescelto.
3.1.2 Caso con varianza incognita
Nella maggior parte delle applicazioni empiriche, la varianza della popolazione \(\sigma^2\) non è nota e deve essere stimata a partire dai dati. In questo caso, essa viene sostituita dalla varianza campionaria \(s^2\). Tale sostituzione introduce un’ulteriore fonte di incertezza, poiché la dispersione della popolazione non è più un parametro noto, ma una quantità stimata.
Questa incertezza aggiuntiva modifica la distribuzione della statistica standardizzata. In particolare, quando la popolazione è normale (o quando \(n\) è sufficientemente grande), la statistica
\[ T = \frac{\bar{X} - \mu}{s / \sqrt{n}} \] non segue più una distribuzione normale standard, ma una distribuzione t di Student con \(n - 1\) gradi di libertà:
\[ T \sim t_{n-1}. \]
I gradi di libertà \(n - 1\) riflettono il fatto che la varianza campionaria è calcolata utilizzando una stima della media, riducendo di un’unità l’informazione indipendente disponibile nei dati.
Fissato un livello di confidenza \(\gamma\) (ad esempio, \(\gamma = 0.95\)), l’intervallo di confidenza per la media \(\mu\) assume la forma:
\[ \left( \bar{X} - t^{*}_{,n-1},\frac{s}{\sqrt{n}}, ;; \bar{X} + t^{*}_{,n-1},\frac{s}{\sqrt{n}} \right), \] dove \(t^{*}_{,n-1}\) è il quantile della distribuzione t con \(n - 1\) gradi di libertà corrispondente al livello di confidenza scelto.
Rispetto al caso con varianza nota, l’intervallo risulta in genere più ampio. La distribuzione t presenta infatti code più pesanti rispetto alla normale standard, riflettendo la maggiore incertezza associata alla stima della varianza. Questa differenza è particolarmente rilevante per campioni di piccole dimensioni e tende a ridursi progressivamente all’aumentare di \(n\): per \(n\) grandi, la distribuzione t converge alla distribuzione normale standard, e i due intervalli diventano praticamente indistinguibili.
Dal punto di vista inferenziale, l’uso della distribuzione t consente quindi di preservare la corretta copertura dell’intervallo di confidenza anche in presenza di varianza ignota, mantenendo la coerenza interna dell’approccio frequentista.
3.2 Esempio pratico in R
Per rendere concreti i concetti introdotti, consideriamo un campione di punteggi di benessere psicologico e utilizziamolo per stimare la media della popolazione mediante un intervallo di confidenza.
# Dati campionari
punteggi <- c(28, 22, 26, 18, 30, 24, 27, 17, 21, 25)
n <- length(punteggi)
# Statistiche descrittive
media <- mean(punteggi)
dev_std <- sd(punteggi)
cat("Media campionaria:", round(media, 2), "\n")
#> Media campionaria: 23.8
cat("Deviazione standard:", round(dev_std, 2), "\n")
#> Deviazione standard: 4.26
cat("Dimensione campionaria:", n, "\n")
#> Dimensione campionaria: 10Queste quantità riassumono il campione osservato e costituiscono i mattoni di base per la costruzione dell’intervallo di confidenza. Poiché la varianza della popolazione è ignota, utilizzeremo la distribuzione t di Student con \(n − 1\) gradi di libertà.
Costruzione manuale dell’intervallo di confidenza.
Procediamo ora al calcolo esplicito di un intervallo di confidenza al 95% per la media della popolazione. Questo passaggio rende trasparente il legame tra teoria e procedura computazionale.
# Calcolo manuale dell'intervallo di confidenza al 95%
alpha <- 0.05
t_star <- qt(1 - alpha/2, df = n - 1)
errore_standard <- dev_std / sqrt(n)
margine_errore <- t_star * errore_standard
limite_inf <- media - margine_errore
limite_sup <- media + margine_errore
cat("Valore critico t*:", round(t_star, 3), "\n")
#> Valore critico t*: 2.26
cat("Errore standard:", round(errore_standard, 2), "\n")
#> Errore standard: 1.35
cat("Intervallo di confidenza al 95%: [",
round(limite_inf, 2), ", ", round(limite_sup, 2), "]\n")
#> Intervallo di confidenza al 95%: [ 20.8 , 26.9 ]Il procedimento riflette direttamente la formula teorica:
\[ \bar{X} \pm t^{*}_{n-1},\frac{s}{\sqrt{n}}. \]
Il margine di errore dipende sia dalla variabilità del campione (tramite \(s\)) sia dalla dimensione campionaria (\(n\)), ed è modulato dal valore critico della distribuzione t, che tiene conto dell’incertezza associata alla stima della varianza.
Verifica con le funzioni di R.
Il risultato ottenuto può essere verificato utilizzando la funzione t.test(), che implementa la stessa procedura inferenziale in modo automatico:
t.test(punteggi, conf.level = 0.95)
#>
#> One Sample t-test
#>
#> data: punteggi
#> t = 18, df = 9, p-value = 3e-08
#> alternative hypothesis: true mean is not equal to 0
#> 95 percent confidence interval:
#> 20.8 26.8
#> sample estimates:
#> mean of x
#> 23.8L’output conferma i limiti dell’intervallo di confidenza calcolati manualmente e fornisce, inoltre, la statistica test t e il relativo valore-p per la verifica dell’ipotesi nulla \(H_0 : \mu = \mu_0\).
3.3 Il significato del livello di copertura
Il livello di copertura è il concetto che definisce in modo rigoroso il significato di un intervallo di confidenza nel paradigma frequentista. Esso rappresenta la proporzione di intervalli che, nel lungo periodo, contengono il vero valore del parametro quando la procedura di costruzione dell’intervallo viene applicata ripetutamente a campioni estratti dalla stessa popolazione.
È essenziale sottolineare che il livello di copertura è una proprietà della procedura inferenziale, non del singolo intervallo ottenuto a partire da un campione specifico. Un intervallo di confidenza al 95% è tale perché la procedura che lo genera garantisce una copertura del 95% nel lungo periodo, non perché il singolo intervallo abbia una “probabilità del 95%” di contenere il parametro.
Questa distinzione è centrale per comprendere correttamente l’interpretazione frequentista degli intervalli di confidenza.
3.3.1 Simulazione del livello di copertura
Per rendere operativa questa idea, possiamo simulare il processo di campionamento ripetuto e verificare empiricamente la copertura degli intervalli di confidenza.
set.seed(42)
# Parametri della popolazione
mu_vero <- 50
sigma <- 10
n <- 25
n_simulazioni <- 1000
# Generazione dei campioni e calcolo degli intervalli
risultati <- replicate(n_simulazioni, {
campione <- rnorm(n, mean = mu_vero, sd = sigma)
test <- t.test(campione, conf.level = 0.95)
c(test$conf.int[1], test$conf.int[2])
})
# Verifica della copertura
contiene_mu <- (risultati[1, ] <= mu_vero) & (risultati[2, ] >= mu_vero)
copertura_empirica <- mean(contiene_mu)
cat("Copertura empirica:", round(copertura_empirica * 100, 1), "%\n")
#> Copertura empirica: 94.8 %
cat("Copertura teorica: 95%\n")
#> Copertura teorica: 95%Il valore della copertura empirica oscilla attorno al 95%, con piccole fluttuazioni dovute al numero finito di simulazioni. All’aumentare del numero di ripetizioni, la copertura empirica tende a convergere al valore teorico, illustrando il significato operativo del livello di confidenza.
3.3.2 Visualizzazione del concetto di copertura
Per rendere ancora più intuitiva questa idea, visualizziamo un sottoinsieme degli intervalli ottenuti:
# Mostriamo i primi 50 intervalli
n_mostra <- 50
df_ic <- data.frame(
id = 1:n_mostra,
lower = risultati[1, 1:n_mostra],
upper = risultati[2, 1:n_mostra],
contiene = contiene_mu[1:n_mostra]
)
ggplot(df_ic, aes(x = id)) +
geom_segment(aes(xend = id, y = lower, yend = upper, color = contiene),
linewidth = 0.5) +
geom_hline(yintercept = mu_vero, linetype = "dashed", color = "red") +
scale_color_manual(values = c("FALSE" = "red", "TRUE" = "steelblue"),
labels = c("Non contiene μ", "Contiene μ")) +
labs(title = "50 intervalli di confidenza al 95%",
subtitle = "La linea tratteggiata indica il valore reale di μ",
x = "Campione", y = "Intervallo di confidenza", color = "") +
coord_flip()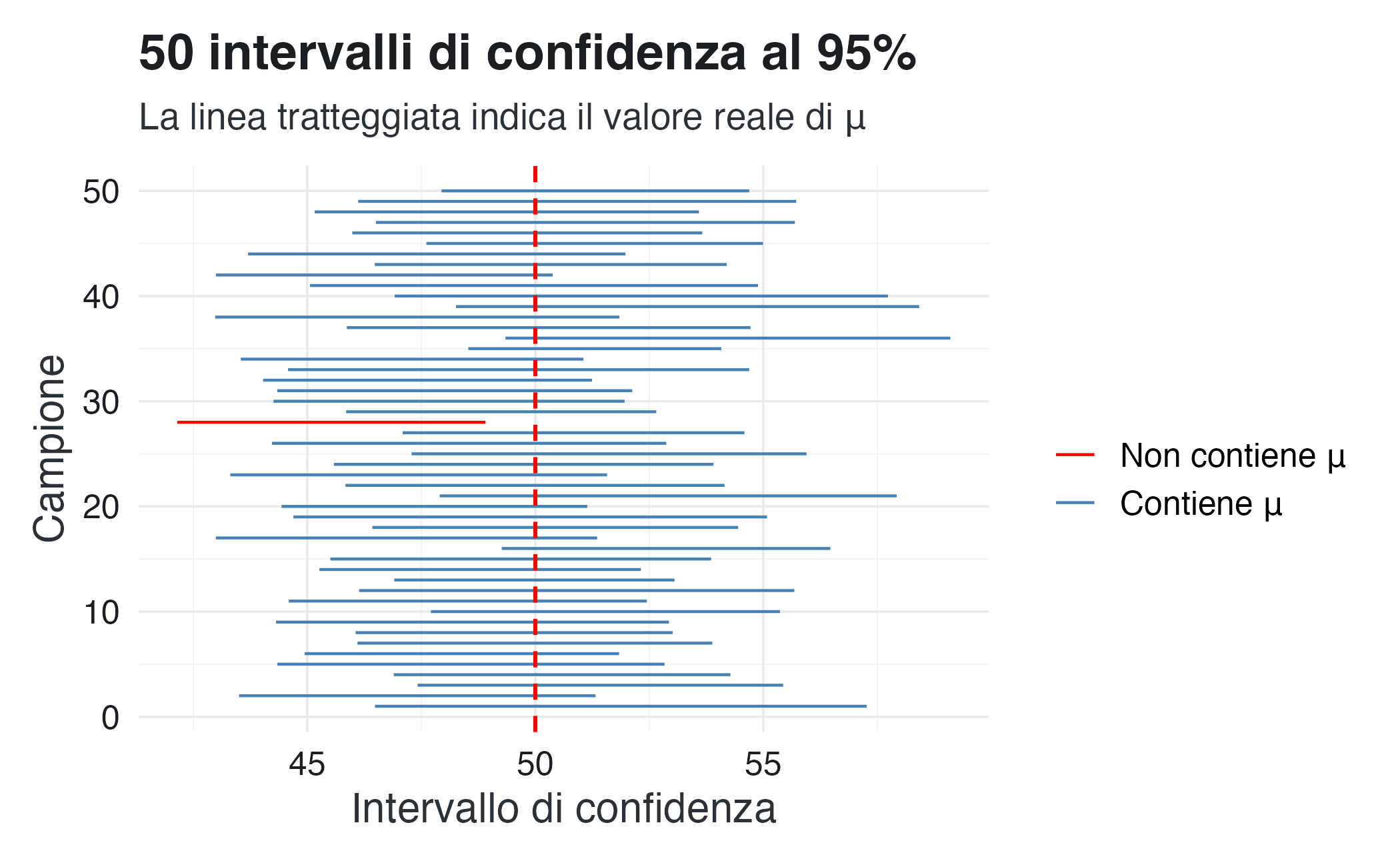
In questo grafico, ciascun segmento rappresenta un intervallo di confidenza costruito a partire da un campione diverso. La linea tratteggiata indica il valore vero del parametro \(\mu\). Come previsto, la maggior parte degli intervalli contiene \(\mu\), mentre una frazione (circa il 5%) non lo include. Non esiste alcun modo, osservando un singolo intervallo, di sapere se esso appartenga al gruppo “corretto” o a quello “errato”: questa incertezza è intrinseca all’inferenza frequentista.
3.4 Interpretazione corretta e fraintendimenti comuni
“Se ripetessimo lo stesso studio molte volte, il 95% degli intervalli costruiti con questa procedura includerebbe il vero valore del parametro.”
L’enfasi è posta sulla procedura inferenziale e sul comportamento nel lungo periodo, non sul singolo intervallo osservato.
❌ “C’è il 95% di probabilità che il parametro sia in questo intervallo.” Nel paradigma frequentista il parametro è una quantità fissa e ignota, non una variabile casuale a cui assegnare probabilità.
❌ “Il 95% dei valori della popolazione cade nell’intervallo.” L’intervallo di confidenza riguarda la stima della media (o di un altro parametro), non la dispersione dei dati individuali.
❌ “I valori centrali dell’intervallo sono più probabili.” L’intervallo di confidenza non fornisce una distribuzione di probabilità sul parametro e non attribuisce maggiore plausibilità a valori “più centrali”.
Questa sezione chiarisce uno dei punti più delicati dell’inferenza frequentista: l’intervallo di confidenza non è uno strumento probabilistico sul parametro, ma una garanzia procedurale sul comportamento a lungo termine del metodo di stima. Comprendere questa distinzione è essenziale per un uso corretto e consapevole degli intervalli di confidenza nella pratica scientifica.
3.5 Effetto del livello di confidenza
Il livello di confidenza influisce direttamente sull’ampiezza dell’intervallo. A parità di dati e di modello statistico, aumentare il livello di confidenza implica rendere l’intervallo più ampio, poiché è necessario garantire una copertura più elevata nel lungo periodo.
Questo effetto può essere illustrato confrontando intervalli di confidenza costruiti sullo stesso campione, ma con livelli di confidenza differenti:
# Confronto tra livelli di confidenza
livelli <- c(0.80, 0.90, 0.95, 0.99)
for (liv in livelli) {
test <- t.test(punteggi, conf.level = liv)
ampiezza <- test$conf.int[2] - test$conf.int[1]
cat(sprintf("IC al %d%%: [%.2f, %.2f] - Ampiezza: %.2f\n",
liv * 100, test$conf.int[1], test$conf.int[2], ampiezza))
}
#> IC al 80%: [21.94, 25.66] - Ampiezza: 3.73
#> IC al 90%: [21.33, 26.27] - Ampiezza: 4.94
#> IC al 95%: [20.75, 26.85] - Ampiezza: 6.10
#> IC al 99%: [19.42, 28.18] - Ampiezza: 8.76Come atteso, all’aumentare del livello di confidenza l’ampiezza dell’intervallo cresce progressivamente. Questo riflette un compromesso fondamentale dell’inferenza frequentista:
- livelli di confidenza più elevati garantiscono una maggiore copertura nel lungo periodo;
- tale garanzia è ottenuta al prezzo di una minore precisione, poiché l’intervallo diventa meno informativo.
In altri termini, richiedere maggiore sicurezza procedurale implica accettare una stima meno precisa del parametro.
3.6 Effetto della dimensione campionaria
Un secondo fattore cruciale che influenza l’ampiezza dell’intervallo di confidenza è la dimensione del campione. A differenza del livello di confidenza, che modifica la soglia di copertura, l’aumento di \(n\) agisce direttamente sulla variabilità della stima, riducendo l’errore standard.
Questo effetto può essere illustrato costruendo intervalli di confidenza al 95% per campioni di dimensione crescente:
set.seed(123)
dimensioni <- c(10, 30, 100, 500)
popolazione <- rnorm(10000, mean = 50, sd = 10)
for (n in dimensioni) {
campione <- sample(popolazione, n)
test <- t.test(campione, conf.level = 0.95)
ampiezza <- test$conf.int[2] - test$conf.int[1]
cat(sprintf("n = %3d: IC = [%.2f, %.2f] - Ampiezza: %.2f\n",
n, test$conf.int[1], test$conf.int[2], ampiezza))
}
#> n = 10: IC = [42.65, 54.75] - Ampiezza: 12.10
#> n = 30: IC = [47.42, 53.51] - Ampiezza: 6.09
#> n = 100: IC = [47.85, 52.08] - Ampiezza: 4.23
#> n = 500: IC = [48.48, 50.25] - Ampiezza: 1.77All’aumentare della dimensione campionaria, l’intervallo si restringe in modo sistematico. Questo comportamento è una conseguenza diretta della relazione teorica:
\[ \text{ampiezza dell’intervallo} \;\propto\; \frac{1}{\sqrt{n}}. \]
Ne segue un risultato concettualmente importante: ottenere intervalli sensibilmente più stretti richiede aumenti sostanziali della numerosità campionaria. Raddoppiare la precisione (ossia dimezzare l’ampiezza dell’intervallo) richiede, in linea teorica, quadruplicare la dimensione del campione.
3.6.1 Sintesi concettuale
Nel paradigma frequentista, la precisione di un intervallo di confidenza è determinata dall’interazione di due fattori principali:
- il livello di confidenza, che controlla la copertura procedurale;
- la dimensione campionaria, che controlla la variabilità della stima.
Questa duplice dipendenza rende esplicito il carattere non arbitrario degli intervalli di confidenza: essi riflettono scelte metodologiche (livello di confidenza) e vincoli empirici (numerosità del campione), e devono essere interpretati alla luce di entrambi.
3.7 Limiti dell’approccio frequentista
Pur rappresentando uno strumento metodologicamente rigoroso e ampiamente utilizzato, l’approccio frequentista agli intervalli di confidenza presenta alcune difficoltà concettuali e interpretative che emergono con particolare evidenza nella pratica scientifica.
Riferimento al lungo periodo. L’interpretazione degli intervalli di confidenza è intrinsecamente legata a un’idea di ripetizione ideale dell’esperimento: la copertura è definita in termini di ciò che accadrebbe su un numero molto elevato di campioni ipotetici. Tuttavia, nella pratica empirica lo sperimentatore osserva un solo campione e un solo intervallo. Questo scarto tra il riferimento teorico (il lungo periodo) e la situazione concreta (il singolo studio) può rendere l’interpretazione controintuitiva, soprattutto in contesti applicativi.
Assenza di probabilità sul parametro. Nel paradigma frequentista, il parametro è considerato una quantità fissa e ignota, non una variabile casuale. Di conseguenza, non è possibile formulare affermazioni probabilistiche dirette del tipo “la probabilità che \(\mu\) appartenga a questo intervallo è 0.95”. Questa restrizione, pur coerente dal punto di vista formale, può risultare poco naturale quando l’obiettivo dell’analisi è esprimere in modo diretto il grado di incertezza su un parametro specifico.
Dipendenza dal piano di campionamento. Gli intervalli di confidenza dipendono non solo dai dati osservati, ma anche dal piano di campionamento e dalle assunzioni del modello statistico. In linea di principio, due analisi basate sugli stessi dati numerici possono produrre intervalli diversi se derivano da disegni sperimentali o strategie di campionamento differenti. Questo aspetto evidenzia come l’inferenza frequentista sia sensibile al contesto procedurale in cui i dati sono stati raccolti.
Nel loro insieme, questi limiti non invalidano l’approccio frequentista, ma ne chiariscono la portata e le condizioni di applicabilità. Essi motivano l’interesse per la prospettiva bayesiana, che adotta una concezione diversa della probabilità e consente di formulare affermazioni probabilistiche dirette sui parametri di interesse attraverso gli intervalli di credibilità, basati sulla distribuzione a posteriori.
Riflessioni conclusive
In questo capitolo abbiamo esaminato gli intervalli di confidenza come lo strumento mediante il quale l’approccio frequentista esprime l’incertezza associata alla stima di un parametro di popolazione. È emerso con chiarezza che la loro interpretazione corretta richiede un cambio di prospettiva rispetto all’intuizione immediata: il livello di confidenza (ad esempio, il 95%) non rappresenta la probabilità che un singolo intervallo osservato contenga il parametro, bensì una proprietà della procedura di costruzione nel lungo periodo.
Una volta osservati i dati e calcolato l’intervallo, quest’ultimo è un oggetto deterministico: esso contiene oppure non contiene il valore vero del parametro, senza che sia epistemologicamente legittimo attribuirgli una probabilità. La nozione di copertura si riferisce esclusivamente al comportamento dell’intervallo sotto ripetizione ideale del campionamento, e costituisce uno degli aspetti più distintivi — e al tempo stesso più controintuitivi — dell’inferenza frequentista.
Abbiamo inoltre visto che l’ampiezza dell’intervallo di confidenza è determinata dall’interazione di tre fattori fondamentali: la variabilità intrinseca dei dati, il livello di confidenza scelto (con livelli più elevati che garantiscono maggiore copertura al prezzo di una minore precisione) e la dimensione del campione, che riduce l’errore standard e conduce a stime progressivamente più precise.
Nonostante il loro ruolo centrale nella pratica scientifica, gli intervalli di confidenza frequentisti sono frequentemente oggetto di fraintendimenti interpretativi, in particolare della tendenza ad attribuire loro un significato probabilistico diretto sul parametro. Questa difficoltà non è semplicemente un problema didattico, ma riflette una differenza filosofica profonda tra i paradigmi statistici: nel frequentismo la probabilità è una proprietà delle procedure e dei dati possibili, non dei parametri.
Questa distinzione concettuale motiva l’esplorazione di approcci alternativi all’inferenza statistica. In particolare, l’inferenza bayesiana propone una concezione diversa della probabilità, che consente di quantificare direttamente l’incertezza sui parametri attraverso distribuzioni a posteriori e intervalli di credibilità, offrendo un linguaggio inferenziale spesso più aderente alle domande poste nella ricerca empirica. L’analisi sistematica di questo approccio costituirà il tema centrale dei capitoli successivi.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 knitr_1.51 labeling_0.4.3
#> [19] bridgesampling_1.2-1 htmlwidgets_1.6.4 curl_7.0.0
#> [22] pkgbuild_1.4.8 RColorBrewer_1.1-3 abind_1.4-8
#> [25] multcomp_1.4-29 purrr_1.2.1 grid_4.5.2
#> [28] stats4_4.5.2 colorspace_2.1-2 xtable_1.8-4
#> [31] inline_0.3.21 emmeans_2.0.1 scales_1.4.0
#> [34] MASS_7.3-65 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 otel_0.2.0
#> [40] RcppParallel_5.1.11-1 cachem_1.1.0 stringr_1.6.0
#> [43] splines_4.5.2 parallel_4.5.2 vctrs_0.6.5
#> [46] V8_8.0.1 Matrix_1.7-4 sandwich_3.1-1
#> [49] jsonlite_2.0.0 arrayhelpers_1.1-0 glue_1.8.0
#> [52] codetools_0.2-20 distributional_0.5.0 lubridate_1.9.4
#> [55] stringi_1.8.7 gtable_0.3.6 QuickJSR_1.8.1
#> [58] pillar_1.11.1 htmltools_0.5.9 Brobdingnag_1.2-9
#> [61] R6_2.6.1 textshaping_1.0.4 rprojroot_2.1.1
#> [64] evaluate_1.0.5 lattice_0.22-7 backports_1.5.0
#> [67] memoise_2.0.1 broom_1.0.11 snakecase_0.11.1
#> [70] rstantools_2.5.0 gridExtra_2.3 coda_0.19-4.1
#> [73] nlme_3.1-168 checkmate_2.3.3 xfun_0.55
#> [76] zoo_1.8-15 pkgconfig_2.0.3