2 Stime, stimatori e parametri
- comprendere il concetto di distribuzione campionaria;
- familiarizzare con le proprietà della distribuzione campionaria della media;
- comprendere il teorema del limite centrale e le sue implicazioni.
- Leggere il capitolo Sampling di Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition).
- Consultare il modulo sulla probabilità per i concetti di variabili casuali, valore atteso e varianza.
2.1 Concetti di base
L’analisi statistica ha come obiettivo fondamentale la conoscenza di una o più caratteristiche di una popolazione di interesse. Nella pratica scientifica, tuttavia, l’osservazione dell’intera popolazione è quasi sempre impraticabile, sia per vincoli materiali sia per ragioni concettuali. Di conseguenza, l’inferenza statistica si fonda sull’osservazione di un campione, estratto dalla popolazione secondo un meccanismo di campionamento formalmente specificato.
Questo passaggio dalla popolazione al campione introduce inevitabilmente un elemento di incertezza, che costituisce il nucleo stesso dell’inferenza statistica. Per formalizzare tale incertezza è necessario distinguere con chiarezza alcuni concetti fondamentali:
Parametro: quantità fissa ma incognita che descrive una caratteristica della popolazione (ad esempio, la media \(\mu\) o la varianza \(\sigma^2\)). Il parametro non è oggetto di osservazione diretta e rappresenta l’oggetto primario dell’inferenza.
Stimatore: regola o funzione matematica dei dati campionari impiegata per approssimare il valore del parametro. Prima dell’osservazione del campione, uno stimatore è una variabile casuale, poiché il suo valore dipende dall’esito aleatorio del processo di campionamento.
Stima: valore numerico specifico ottenuto applicando uno stimatore a un campione concreto. La stima è quindi una realizzazione osservata dello stimatore.
La distinzione tra stimatore e stima è concettualmente cruciale. Le proprietà inferenziali, come correttezza, variabilità o consistenza, riguardano lo stimatore in quanto oggetto probabilistico, non la singola stima osservata. Quest’ultima, essendo il risultato di un campionamento casuale, è inevitabilmente affetta da incertezza statistica e, in generale, non coincide esattamente con il valore vero del parametro della popolazione.
Questa incertezza, lungi dall’essere un difetto, costituisce il punto di partenza per lo studio della distribuzione campionaria, che descrive il comportamento probabilistico di uno stimatore al variare dei campioni possibili e fornisce il fondamento teorico dell’inferenza statistica frequentista.
2.2 La distribuzione campionaria: intuizione e definizione
Per introdurre il concetto di distribuzione campionaria, è utile partire da un esempio volutamente semplice che consente di enumerare esplicitamente tutti i campioni possibili. L’obiettivo non è simulare una situazione realistica di analisi dei dati, bensì costruire un dispositivo concettuale che permetta di rendere visibile un’idea altrimenti astratta: il comportamento probabilistico di una statistica al variare dei campioni.
2.2.1 Esempio introduttivo
Consideriamo una popolazione estremamente ridotta, composta da quattro valori:
x <- c(2, 4.5, 5, 5.5)
x
#> [1] 2.0 4.5 5.0 5.5Questi valori potrebbero rappresentare, ad esempio, i tempi di reazione (in secondi) di quattro partecipanti a un esperimento. Poiché stiamo trattando l’insieme completo delle osservazioni disponibili, possiamo calcolarne direttamente la media e la varianza, che in questo contesto assumono il ruolo di parametri della popolazione:
Queste quantità descrivono la popolazione nel suo complesso e costituiscono il riferimento rispetto al quale confronteremo i risultati ottenuti dai campioni.
2.2.2 Campionamento e costruzione della distribuzione campionaria
Supponiamo ora di estrarre tutti i possibili campioni di dimensione \(n = 2\) con reinserimento dalla popolazione. L’uso del reinserimento garantisce che ogni estrazione sia indipendente e che ciascun valore della popolazione possa comparire più volte nello stesso campione.
Poiché a ogni estrazione sono disponibili quattro valori distinti, il numero totale di campioni ordinati possibili è:
\[ 4^2 = 16. \]
samples <- expand.grid(x, x)
samples
#> Var1 Var2
#> 1 2.0 2.0
#> 2 4.5 2.0
#> 3 5.0 2.0
#> 4 5.5 2.0
#> 5 2.0 4.5
#> 6 4.5 4.5
#> 7 5.0 4.5
#> 8 5.5 4.5
#> 9 2.0 5.0
#> 10 4.5 5.0
#> 11 5.0 5.0
#> 12 5.5 5.0
#> 13 2.0 5.5
#> 14 4.5 5.5
#> 15 5.0 5.5
#> 16 5.5 5.5
nrow(samples)
#> [1] 16Ogni riga della tabella rappresenta un possibile campione di dimensione 2. Per ciascun campione calcoliamo ora la media campionaria, ottenendo così l’insieme di tutti i valori che tale statistica può assumere sotto ripetizione del campionamento:
sample_means <- rowMeans(samples)
sample_means
#> [1] 2.00 3.25 3.50 3.75 3.25 4.50 4.75 5.00 3.50 4.75 5.00 5.25 3.75 5.00 5.25
#> [16] 5.50Questo insieme di valori costituisce la distribuzione campionaria della media per campioni di dimensione \(n = 2\).
2.2.3 Visualizzazione della distribuzione campionaria
Per rendere più intuitiva la struttura di questa distribuzione, rappresentiamo graficamente le medie campionarie ottenute:
df <- data.frame(Valori = sample_means)
ggplot(df, aes(x = Valori)) +
geom_histogram(
bins = 7,
aes(y = after_stat(density)),
fill = "steelblue",
color = "white"
) +
labs(
title = "Distribuzione campionaria delle medie (n = 2)",
x = "Media campionaria",
y = "Densità"
)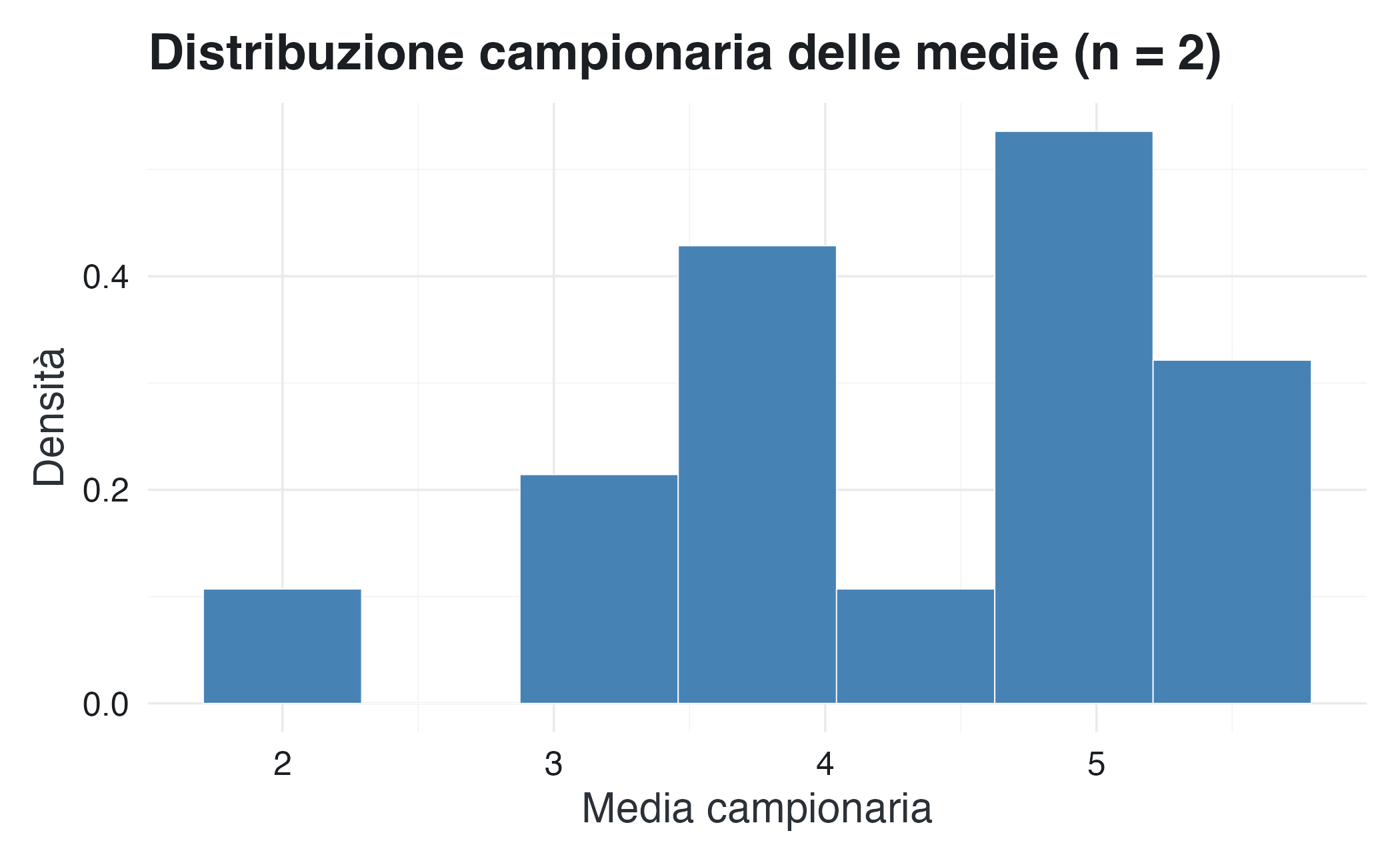
L’istogramma mostra chiaramente che le medie campionarie non sono distribuite uniformemente. Alcuni valori compaiono più frequentemente di altri perché possono essere ottenuti da un numero maggiore di combinazioni dei valori della popolazione. In altre parole, anche se il campionamento dalla popolazione avviene in modo casuale e uniforme (cioè ogni unità ha la stessa probabilità di essere estratta), la distribuzione della statistica calcolata (in questo caso, la media) non è necessariamente uniforme.
Questo esempio mette in evidenza un punto concettuale fondamentale: la distribuzione campionaria di una statistica possiede una struttura propria, che dipende sia dalla distribuzione della popolazione sia dalla dimensione del campione. Essa non coincide né con la distribuzione della popolazione né con quella dei singoli campioni osservati.
L’esempio precedente ci ha permesso di costruire esplicitamente una distribuzione campionaria in un caso elementare. Nel seguito, generalizzeremo questa idea, introducendo la definizione formale di distribuzione campionaria e analizzandone le proprietà teoriche, che costituiscono il fondamento dell’inferenza statistica frequentista.
2.2.4 Cos’è una distribuzione campionaria
Nel lavoro empirico emerge un’apparente tensione epistemologica: l’analisi statistica si fonda sull’osservazione di un singolo campione, dal quale otteniamo una singola stima del parametro di interesse (ad esempio, una media campionaria). Tuttavia, l’obiettivo dell’inferenza non è il campione in sé, bensì la valutazione dell’affidabilità di tale stima rispetto al parametro della popolazione. Come può essere quantificata questa affidabilità a partire da un’unica osservazione?
L’inferenza frequentista risolve questo problema adottando un punto di vista esplicitamente controfattuale: si chiede cosa accadrebbe se lo stesso studio potesse essere ripetuto un numero molto elevato (idealmente infinito) di volte, mantenendo inalterate le condizioni sperimentali e lo schema di campionamento.
In termini concettuali, questo equivale a immaginare che:
- dalla medesima popolazione vengano estratti ripetutamente campioni della stessa dimensione \(n\);
- per ciascun campione venga calcolata la medesima statistica (ad esempio, la media campionaria).
Poiché ogni campione differisce dagli altri per composizione, anche i valori assunti dalla statistica varieranno da un campione all’altro. Se si potessero raccogliere tutte queste stime e rappresentarle graficamente, emergerebbe una forma regolare: una distribuzione di probabilità.
Questa distribuzione teorica, che descrive come una statistica varia al variare del campione estratto, prende il nome di distribuzione campionaria.
La distribuzione campionaria di una statistica è la distribuzione di probabilità dei valori che tale statistica assume su tutti i possibili campioni di dimensione \(n\) estraibili dalla stessa popolazione, secondo uno specifico schema di campionamento.
Essa rappresenta una mappa dell’incertezza campionaria, ossia della variabilità intrinseca della stima dovuta esclusivamente al carattere aleatorio del campionamento.
È essenziale chiarire cosa la distribuzione campionaria non rappresenta:
- non è la distribuzione dei dati nella popolazione;
- non è la distribuzione dei dati osservati in un singolo campione;
- è, piuttosto, una proprietà teorica dello stimatore, che dipende dalla dimensione del campione \(n\), dalla variabilità della popolazione e dallo schema di campionamento adottato.1
La distinzione concettuale fondamentale può essere così riassunta:
- la distribuzione della popolazione descrive la variabilità di un tratto tra gli individui;
- la distribuzione campionaria descrive la variabilità di una stima di quel tratto tra esperimenti ripetuti.
Questa distinzione costituisce il nucleo dell’inferenza statistica frequentista. Sebbene nella pratica si osservi un solo campione, gli strumenti inferenziali, come gli intervalli di confidenza e i test di ipotesi, traggono la loro giustificazione teorica dal comportamento a lungo termine della statistica, così come descritto dalla sua distribuzione campionaria. Ogni stimatore, che si tratti di una media, di una proporzione o di un coefficiente di regressione, possiede una propria distribuzione campionaria, dalla quale discendono le sue proprietà di accuratezza, precisione e affidabilità inferenziale.
2.2.5 Proprietà della distribuzione campionaria
Per chiarire le proprietà fondamentali delle distribuzioni campionarie, ci concentreremo sulla media campionaria come stimatore principale. Questa scelta non è casuale: la media rappresenta lo strumento di stima più utilizzato in psicologia e nelle scienze sociali e costituisce un caso paradigmatico per comprendere i meccanismi generali dell’inferenza frequentista.
2.2.5.1 Una proprietà fondamentale: la correttezza
Un primo risultato teorico di rilievo riguarda il valore atteso della media campionaria. La teoria statistica dimostra che la media della distribuzione campionaria di \(\bar{X}\) coincide esattamente con la media della popolazione \(\mu\):
\[ \mathbb{E}(\bar{X}) = \mu. \]
Nel nostro esempio empirico, questa uguaglianza può essere verificata direttamente:
Questo risultato non è un fatto contingente, ma esprime una proprietà formale cruciale: la media campionaria \(\bar{X}\) è uno stimatore corretto (unbiased, o non distorto) del parametro \(\mu\). In termini concettuali, la correttezza implica che lo stimatore non presenta una tendenza sistematica a sovrastimare o sottostimare il valore vero della popolazione.
Dal punto di vista frequentista, ciò significa che nel lungo periodo, ossia sotto ripetizione indefinita del processo di campionamento, la media delle stime converge al parametro vero. La correttezza non garantisce che una singola stima sia vicina a \(\mu\), ma assicura che eventuali errori di stima si compensino nel complesso delle ripetizioni.
La distinzione tra correttezza e varianza dello stimatore può essere visualizzata con l’analogia di un arciere che spara ripetutamente a un bersaglio.
- La correttezza equivale ad avere il centro del raggruppamento dei colpi coincidente con il centro del bersaglio: lo stimatore non presenta distorsione sistematica.
- La precisione equivale alla concentrazione dei colpi, indipendentemente dalla loro posizione rispetto al centro: uno stimatore preciso produce stime poco dispersa attorno al proprio valore atteso.
Uno stimatore ideale è sia corretto sia preciso. Nella pratica, tuttavia, esiste spesso un compromesso tra le due proprietà: stimatori leggermente distorti possono avere varianza molto più piccola, risultando complessivamente più utili. Questo tema, noto come bias-variance tradeoff, sarà ripreso nei capitoli successivi.
2.2.6 Varianza della distribuzione campionaria
Se la correttezza riguarda il centro della distribuzione campionaria, la varianza della distribuzione campionaria ne quantifica invece la dispersione, fornendo una misura della precisione dello stimatore. Essa descrive quanto le stime della media tendano a fluttuare attorno al valore vero \(\mu\) al variare del campione.
La teoria statistica fornisce una relazione fondamentale:
\[ \mathrm{Var}(\bar{X}) = \frac{\sigma^2}{n}, \]
dove:
- \(\sigma^2\) è la varianza della popolazione,
- \(n\) è la dimensione del campione.
Nel nostro esempio, tale relazione può essere verificata empiricamente:
var(x) # σ²: varianza della popolazione
#> [1] 2.42
var(x) / 2 # σ²/n: varianza teorica della media per n = 2
#> [1] 1.21
var(sample_means) * 15/16 # varianza empirica corretta per popolazione finita
#> [1] 0.906
# Nota: si moltiplica per (N-1)/N = 15/16 perché var() usa n-1 al
# denominatore (varianza campionaria), mentre qui serve la varianza
# di popolazione sull'insieme dei 16 campioni possibili.Sia \(X_1, X_2, \ldots, X_n\) un campione casuale semplice estratto da una popolazione con media \(\mu\) e varianza \(\sigma^2\). Per definizione di campionamento casuale semplice, le variabili \(X_i\) sono indipendenti e identicamente distribuite (i.i.d.), con \(\mathbb{E}[X_i] = \mu\) e \(\mathrm{Var}(X_i) = \sigma^2\) per ogni \(i\).
La media campionaria è definita come:
\[ \bar{X} = \frac{1}{n} \sum_{i=1}^n X_i. \]
2.2.6.1 Valore atteso: \(\mathbb{E}(\bar{X}) = \mu\)
Applicando la linearità del valore atteso, che vale senza alcuna assunzione di indipendenza:
\[ \mathbb{E}(\bar{X}) = \mathbb{E}\!\left[\frac{1}{n} \sum_{i=1}^n X_i\right] = \frac{1}{n} \sum_{i=1}^n \mathbb{E}[X_i] = \frac{1}{n} \sum_{i=1}^n \mu = \frac{1}{n} \cdot n\mu = \mu. \]
Lo stimatore \(\bar{X}\) è quindi corretto (non distorto): il suo valore atteso coincide esattamente con il parametro di interesse, qualunque sia la distribuzione della popolazione e qualunque sia \(n\).
2.2.6.2 Varianza: \(\mathrm{Var}(\bar{X}) = \sigma^2/n\)
Per la varianza si utilizza la proprietà secondo cui, per variabili indipendenti, la varianza della somma è la somma delle varianze, e la varianza di una costante per una variabile casuale soddisfa \(\mathrm{Var}(cX) = c^2 \mathrm{Var}(X)\):
\[ \mathrm{Var}(\bar{X}) = \mathrm{Var}\!\left[\frac{1}{n} \sum_{i=1}^n X_i\right] = \frac{1}{n^2} \,\mathrm{Var}\!\left[\sum_{i=1}^n X_i\right] = \frac{1}{n^2} \sum_{i=1}^n \mathrm{Var}(X_i) = \frac{1}{n^2} \cdot n\sigma^2 = \frac{\sigma^2}{n}. \]
Il passaggio cruciale è il terzo: la varianza della somma si semplifica nella somma delle varianze solo grazie all’indipendenza tra le \(X_i\). In assenza di indipendenza, i termini di covarianza \(\mathrm{Cov}(X_i, X_j)\) con \(i \neq j\) non si annullerebbero, e la formula sarebbe più complessa.
2.2.6.3 Riepilogo
| Proprietà | Formula |
|---|---|
| Valore atteso | \(\mathbb{E}(\bar{X}) = \mu\) |
| Varianza | \(\mathrm{Var}(\bar{X}) = \sigma^2/n\) |
| Deviazione standard (errore standard) | \(\mathrm{SE}(\bar{X}) = \sigma/\sqrt{n}\) |
Queste tre quantità descrivono completamente la posizione e la dispersione della distribuzione campionaria della media. Insieme al teorema del limite centrale, esse costituiscono il fondamento matematico di tutti i metodi inferenziali basati sulla media campionaria.
Questa formula racchiude uno dei principi più importanti dell’inferenza statistica: la variabilità delle medie campionarie diminuisce all’aumentare della dimensione del campione. In altri termini, la precisione dello stimatore cresce con \(n\).
L’interpretazione intuitiva è che campioni più ampi tendono a “compensare” le fluttuazioni casuali dovute a osservazioni estreme o atipiche. Di conseguenza, le stime ottenute da campioni grandi risultano più stabili e replicabili. Due campioni indipendenti di dimensione \(n = 100\) produrranno, in media, stime della media molto più simili tra loro rispetto a due campioni di dimensione \(n = 10\).
Questa proprietà fornisce il fondamento teorico del principio secondo cui l’aumento della dimensione campionaria riduce l’incertezza inferenziale, e prepara il terreno per risultati più generali, come il teorema del limite centrale, che verrà discusso nella sezione successiva.
2.3 Il teorema del limite centrale
Il teorema del limite centrale (TLC) rappresenta uno dei pilastri concettuali della statistica inferenziale. La sua importanza non risiede soltanto nel contenuto matematico, ma nel ruolo epistemologico che esso svolge: il TLC fornisce il collegamento teorico tra la variabilità individuale dei dati e le regolarità aggregative emergenti nelle statistiche di sintesi. Il suo nucleo concettuale può essere riassunto nel seguente enunciato: la media (o la somma) di un numero sufficientemente elevato di variabili casuali indipendenti e identicamente distribuite converge a una distribuzione normale, indipendentemente dalla forma della distribuzione originaria delle variabili stesse.
2.3.1 Enunciato formale
Siano \(X_1, X_2, \ldots, X_n\) una sequenza di variabili casuali indipendenti e identicamente distribuite (i.i.d.), ciascuna con valore atteso \(\mathbb{E}[X_i] = \mu\) e varianza finita \(\mathrm{Var}(X_i) = \sigma^2\).
Allora, per \(n\) sufficientemente grande, la distribuzione della media campionaria
\[ \bar{X}_n = \frac{1}{n} \sum_{i=1}^n X_i \]
può essere approssimata da una distribuzione normale con la stessa media \(\mu\) e varianza ridotta di un fattore \(n\):
\[ \bar{X}_n \;\stackrel{\text{appross.}}{\sim}\; \mathcal{N}\!\left(\mu,\; \frac{\sigma^2}{n}\right). \]
In forma standardizzata, il teorema afferma che la variabile
\[ Z_n = \frac{\bar{X}_n - \mu}{\sigma / \sqrt{n}} \]
converge in distribuzione a una normale standard:
\[ Z_n \xrightarrow[]{\;d\;} \mathcal{N}(0, 1), \qquad \text{per } n \to \infty. \]
È importante sottolineare che questa convergenza riguarda la forma della distribuzione e non i singoli valori osservati: il TLC è un risultato asintotico e probabilistico, non deterministico.
2.3.2 Perché il TLC è così rilevante?
Il teorema del limite centrale spiega l’ubiquità empirica della distribuzione normale nelle scienze sperimentali e sociali, psicologia compresa. Molte delle quantità di interesse, ovvero medie, somme, proporzioni, sono, nella loro struttura matematica, il risultato di aggregazioni di osservazioni individuali. Il TLC garantisce che, anche quando la distribuzione della popolazione è asimmetrica, multimodale o irregolare, la distribuzione campionaria della media tende ad assumere una forma approssimativamente normale al crescere della dimensione campionaria.
È cruciale mantenere distinta la portata del teorema:
- il TLC non afferma che i dati grezzi \(X_i\) siano normalmente distribuiti;
- il TLC garantisce che la distribuzione campionaria della media \(\bar{X}_n\) diventi approssimativamente normale per campioni sufficientemente grandi.
Questa distinzione è spesso fonte di fraintendimenti nella pratica applicativa, ma è centrale per una corretta interpretazione dei metodi inferenziali frequentisti.
2.3.3 Implicazioni inferenziali
Dal punto di vista metodologico, il TLC costituisce il fondamento teorico che rende possibile:
- la costruzione di intervalli di confidenza per la media,
- l’applicazione di test di ipotesi basati sulla distribuzione normale,
anche in situazioni in cui l’assunzione di normalità della popolazione non è verificabile o risulta chiaramente violata. In tal senso, il TLC giustifica l’uso estensivo della distribuzione normale come modello approssimante nell’inferenza frequentista.
Al tempo stesso, il teorema chiarisce il ruolo cruciale della dimensione campionaria: quanto più \(n\) è grande, tanto migliore è l’approssimazione normale. Nei capitoli successivi vedremo come questa dipendenza da \(n\) condizioni la validità pratica dei risultati inferenziali e come, in presenza di campioni piccoli o distribuzioni fortemente asimmetriche, sia necessario ricorrere a strumenti alternativi o a cautele interpretative.
2.3.4 Dimostrazione mediante simulazione: la normalizzazione dell’asimmetria
Per cogliere in modo intuitivo la portata del teorema del limite centrale, è istruttivo partire da una distribuzione che violi in modo netto l’assunzione di normalità. Consideriamo quindi una distribuzione esponenziale con parametro \(\lambda = 1\), che presenta caratteristiche opposte a quelle di una distribuzione normale:
- è fortemente asimmetrica (asimmetria positiva pari a 2);
- è limitata inferiormente (assume solo valori positivi);
- presenta una coda lunga verso destra.
Distribuzioni di questo tipo sono comuni in contesti empirici, ad esempio nello studio dei tempi di attesa, delle durate o dei tempi di reazione. Proprio per la loro marcata non-normalità, esse costituiscono un banco di prova ideale per osservare l’azione del TLC.
L’idea della simulazione è la seguente: estrarre ripetutamente campioni dalla distribuzione esponenziale, calcolare la media di ciascun campione e osservare come si distribuiscono queste medie al variare della dimensione campionaria \(n\).
Il codice seguente genera 10,000 campioni indipendenti per tre diverse dimensioni campionarie (\(n = 3\), \(n = 30\), \(n = 300\)), calcolando ogni volta la media campionaria:
set.seed(123)
n_samples <- 10000
# Funzione per calcolare medie campionarie da distribuzione esponenziale
calculate_means <- function(sample_size) {
replicate(n_samples, mean(rexp(sample_size, rate = 1)))
}
# Medie per diverse dimensioni campionarie
means_n3 <- calculate_means(3)
means_n30 <- calculate_means(30)
means_n300 <- calculate_means(300)
# Parametri teorici della distribuzione esponenziale(1):
# media = 1/λ = 1, deviazione standard = 1/λ = 1
mu <- 1
sigma <- 1
# Visualizzazione
par(mfrow = c(1, 3), mar = c(4, 4, 3, 1))
# n = 3
hist(means_n3, breaks = 40, main = "n = 3", xlab = "Media campionaria",
probability = TRUE, col = "lightblue", xlim = c(0, 3))
curve(dnorm(x, mean = mu, sd = sigma / sqrt(3)), add = TRUE,
col = "red", lwd = 2, lty = 2)
# n = 30
hist(means_n30, breaks = 40, main = "n = 30", xlab = "Media campionaria",
probability = TRUE, col = "lightblue", xlim = c(0.5, 1.8))
curve(dnorm(x, mean = mu, sd = sigma / sqrt(30)), add = TRUE,
col = "red", lwd = 2, lty = 2)
# n = 300
hist(means_n300, breaks = 40, main = "n = 300", xlab = "Media campionaria",
probability = TRUE, col = "lightblue", xlim = c(0.7, 1.4))
curve(dnorm(x, mean = mu, sd = sigma / sqrt(300)), add = TRUE,
col = "red", lwd = 2, lty = 2)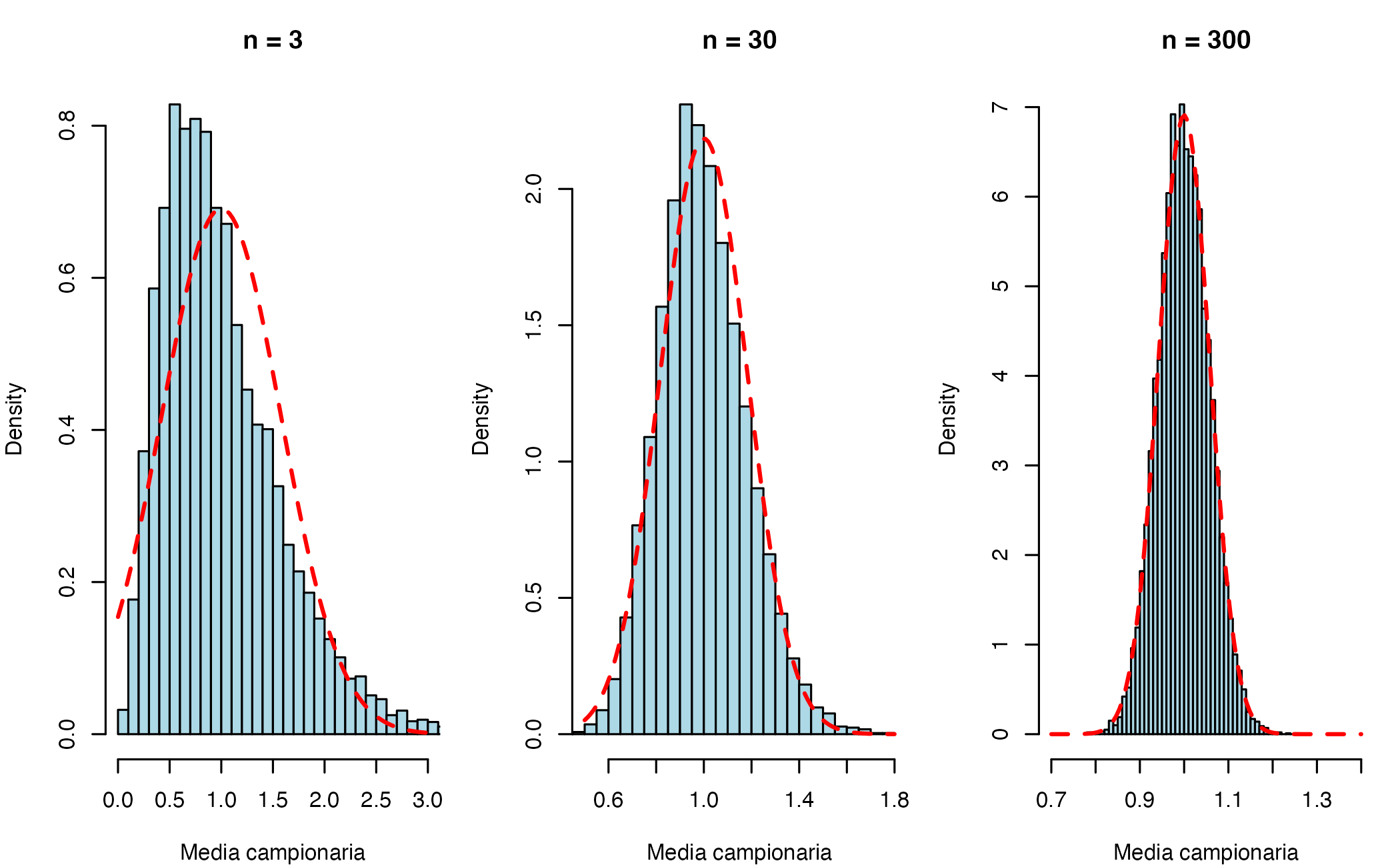
2.3.4.1 Interpretazione dei risultati
Il confronto tra i tre pannelli rende visibile il teorema del limite centrale in azione.
1. Dalla asimmetria alla simmetria
- Con \(n = 3\), la distribuzione delle medie campionarie conserva una marcata asimmetria verso destra. La forma riflette ancora chiaramente la distribuzione esponenziale di partenza.
- Con \(n = 30\), l’asimmetria si riduce drasticamente. La distribuzione appare ormai campanulare e quasi simmetrica.
- Con \(n = 300\), la distribuzione delle medie è praticamente indistinguibile da una distribuzione normale. L’asimmetria originaria è scomparsa.
Questo mostra come il TLC operi una vera e propria normalizzazione dell’asimmetria, anche quando la popolazione di origine è fortemente non-normale.
2. Riduzione progressiva della dispersione
Parallelamente, si osserva una chiara riduzione della dispersione delle medie campionarie:
- la varianza teorica della media diminuisce come \(\sigma^2/n = 1/n\);
- l’intervallo di variazione si restringe progressivamente: per \(n = 300\), la maggior parte delle medie si concentra in un intorno molto stretto del valore vero \(\mu = 1\).
Questa riduzione riflette l’aumento della precisione inferenziale associato a campioni più grandi.
2.3.4.2 Due messaggi chiave del TLC
La simulazione evidenzia in modo diretto i due aspetti centrali del teorema del limite centrale:
Normalizzazione della forma. Anche partendo da una distribuzione estremamente asimmetrica, la distribuzione campionaria della media tende a una forma gaussiana al crescere di \(n\).
-
Ruolo cruciale della dimensione campionaria. La dimensione del campione controlla simultaneamente:
- la velocità di convergenza alla normalità;
- la precisione della stima, che cresce come \(1/\sqrt{n}\).
La curva rossa tratteggiata in ciascun pannello rappresenta la distribuzione normale teorica prevista dal TLC, \(\mathcal{N}(1, 1/n)\). Il buon accordo osservato, soprattutto per \(n\) grandi, mostra come il TLC fornisca una base solida per l’uso della distribuzione normale nell’inferenza statistica frequentista, anche quando i dati di partenza non presentano alcuna somiglianza con una gaussiana.
2.4 Errore standard
L’errore standard (Standard Error, SE) rappresenta la deviazione standard della distribuzione campionaria di uno stimatore. Esso quantifica, in forma sintetica, la variabilità teorica della stima dovuta esclusivamente al processo di campionamento e fornisce quindi una misura diretta della precisione inferenziale.
Nel caso della media campionaria \(\bar{X}\), l’errore standard è definito come:
\[ \mathrm{SE}(\bar{X}) = \frac{\sigma}{\sqrt{n}}, \]
dove \(\sigma\) è la deviazione standard della popolazione e \(n\) la dimensione del campione. Questa espressione discende direttamente dalla varianza della distribuzione campionaria della media e rende esplicita una relazione cruciale: la precisione della stima cresce con la dimensione del campione, ma con un rendimento decrescente, poiché dipende dalla radice quadrata di \(n\).
Dal punto di vista teorico, l’errore standard è dunque una proprietà dello stimatore, non dei dati osservati. Esso descrive quanto la stima fluttuerebbe, in media, se il processo di campionamento fosse ripetuto molte volte nelle stesse condizioni.
2.4.1 Errore standard stimato
Nella pratica applicativa, la deviazione standard della popolazione \(\sigma\) è quasi sempre ignota. Per questo motivo, essa viene sostituita dalla deviazione standard campionaria \(s\), ottenendo una stima empirica dell’errore standard:
\[ \widehat{\mathrm{SE}}(\bar{X}) = \frac{s}{\sqrt{n}}. \]
Questa quantità è essa stessa una stima e introduce un ulteriore livello di incertezza, particolarmente rilevante per campioni di piccola dimensione. Tuttavia, per campioni moderati o grandi, l’errore standard stimato fornisce un’approssimazione affidabile della variabilità reale della media campionaria.
2.4.2 Interpretazione concettuale
L’errore standard svolge un ruolo centrale nell’inferenza frequentista perché connette tre livelli concettuali distinti:
- la variabilità della popolazione (\(\sigma\));
- la dimensione del campione (\(n\));
- la variabilità della stima sotto campionamento ripetuto.
Un errore standard piccolo indica che la distribuzione campionaria della media è fortemente concentrata attorno al valore atteso, e quindi che stime ottenute da campioni diversi tenderebbero a essere simili. Al contrario, un errore standard elevato segnala una maggiore instabilità inferenziale.
È importante sottolineare che l’errore standard non misura la dispersione dei dati, ma la dispersione delle stime. Confondere l’errore standard con la deviazione standard dei dati è uno degli errori interpretativi più comuni nella pratica empirica.
2.4.3 Ruolo inferenziale dell’errore standard
Dal punto di vista operativo, l’errore standard costituisce l’elemento chiave per:
- la costruzione di intervalli di confidenza, che quantificano l’incertezza frequentista associata alla stima;
- il calcolo delle statistiche test nei test di ipotesi frequentisti;
- la valutazione della precisione comparativa tra studi con dimensioni campionarie diverse.
In questo senso, l’errore standard rappresenta il punto di incontro tra la teoria delle distribuzioni campionarie, il teorema del limite centrale e le procedure inferenziali applicate. Nei prossimi paragrafi vedremo come esso venga utilizzato esplicitamente nella costruzione degli intervalli di confidenza per la media e nei test statistici basati sulla distribuzione normale e sulla distribuzione t di Student.
2.5 Implicazioni per l’inferenza
I concetti di distribuzione campionaria ed errore standard costituiscono il fondamento teorico dell’inferenza frequentista. Essi formalizzano l’idea centrale secondo cui la conoscenza statistica non riguarda il singolo campione osservato, ma il comportamento di una procedura inferenziale sotto la ripetizione ideale del campionamento.
Comprendere come uno stimatore si comporta nel lungo periodo consente di affrontare in modo sistematico tre problemi fondamentali dell’inferenza statistica:
Quantificare l’incertezza. L’errore standard permette di associare a una stima puntuale una misura della sua variabilità teorica. In questo modo, la stima non è più interpretata come un valore isolato, ma come il risultato di un processo aleatorio, la cui dispersione è descritta dalla distribuzione campionaria dello stimatore.
Costruire intervalli di confidenza. La conoscenza della distribuzione campionaria consente di derivare intervalli di valori per il parametro incognito, la cui interpretazione è intrinsecamente procedurale: un intervallo di confidenza è definito dalla sua percentuale di copertura nel lungo periodo, non dalla probabilità che il parametro si trovi in un singolo intervallo osservato.
Condurre test di ipotesi. I test statistici utilizzano la distribuzione campionaria di una statistica test per valutare quanto i dati osservati siano compatibili con un’ipotesi nulla di riferimento. Il valore-\(p\) quantifica la probabilità di osservare dati almeno altrettanto estremi, assumendo la validità dell’ipotesi nulla e del modello di campionamento ripetuto.
In ciascuno di questi casi, l’inferenza frequentista non attribuisce probabilità ai parametri o alle ipotesi, ma alle procedure e ai dati possibili generati sotto specifiche assunzioni.
Il concetto di distribuzione campionaria può risultare controintuitivo, poiché richiede di ragionare in termini di esperimenti ipoteticamente ripetuti, nonostante nella pratica si osservi un solo campione. Questa prospettiva controfattuale costituisce una caratteristica distintiva del pensiero frequentista e ne definisce tanto la forza metodologica quanto il limite interpretativo.
Riflessioni conclusive
In questo capitolo sono stati introdotti i principi fondamentali che governano l’inferenza statistica nell’approccio frequentista, mettendo in luce il ruolo centrale della distribuzione campionaria come strumento concettuale per comprendere l’incertezza statistica. È stato mostrato come l’inferenza frequentista si fondi sull’analisi del comportamento di uno stimatore sotto l’ipotesi di campionamento ripetuto dalla stessa popolazione, piuttosto che sull’interpretazione di un singolo campione osservato.
Con riferimento alla media campionaria \(\bar{X}\), è stato dimostrato — sia formalmente che mediante verifica empirica — che la sua distribuzione campionaria ha valore atteso pari al parametro della popolazione \(\mu\), garantendo la proprietà di correttezza (unbiasedness, assenza di distorsione) dello stimatore. È stato inoltre evidenziato come la varianza della distribuzione campionaria, pari a \(\sigma^2 / n\), diminuisca all’aumentare della dimensione del campione, mostrando che la precisione inferenziale cresce con \(n\). Il teorema del limite centrale ha fornito il fondamento teorico per l’approssimazione normale della distribuzione campionaria della media, quando la dimensione campionaria è sufficientemente grande, indipendentemente dalla forma della distribuzione della popolazione.
In questo quadro, l’errore standard, definito come la radice quadrata della varianza della distribuzione campionaria, emerge come una quantità chiave per quantificare la precisione di una stima e per collegare la teoria delle distribuzioni campionarie alle procedure inferenziali operative.
Nel loro insieme, questi concetti costituiscono l’ossatura logica dell’inferenza frequentista e forniscono il fondamento teorico necessario per comprendere strumenti quali gli intervalli di confidenza e i test di ipotesi, che verranno sviluppati nei capitoli successivi. Comprendere tali strumenti richiede, infatti, una chiara consapevolezza del quadro probabilistico che li giustifica e dei presupposti concettuali su cui essi si basano.
sessionInfo()
#> R version 4.5.3 (2026-03-11)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.4
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.2 tinytable_0.16.0 withr_3.0.2
#> [4] systemfonts_1.3.2 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.2
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.2.0
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.4.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-6
#> [13] magrittr_2.0.4 compiler_4.5.3 rlang_1.1.7
#> [16] tools_4.5.3 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-30 purrr_1.2.1
#> [28] grid_4.5.3 stats4_4.5.3 colorspace_2.1-2
#> [31] xtable_1.8-8 inline_0.3.21 emmeans_2.0.2
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-6 rmarkdown_2.31 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-2 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.3 parallel_4.5.3
#> [46] vctrs_0.7.2 V8_8.0.1 Matrix_1.7-5
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.7.0
#> [55] lubridate_1.9.5 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.9.0 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.5
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-9
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.12
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-169 checkmate_2.3.4
#> [76] xfun_0.57 zoo_1.8-15 pkgconfig_2.0.3Schema di campionamento: si riferisce al metodo con cui vengono selezionate le unità dalla popolazione. Nell’esempio specifico, poiché si considerano tutte le possibili coppie ordinate (
expand.grid), lo schema è equivalente a un campionamento casuale con reimmissione (ogni estrazione è indipendente e la popolazione rimane identica).↩︎